标签:
最近在学大数据这门课,课上讲到了一个关于尿布与啤酒的故事,说是发现在超市中尿布如果和啤酒放在一起能跟提高销量,原因是买尿布的多是父亲,这些人看到啤酒后就想买(这是什么逻辑)。当然,这个故事被证明是虚构的了信息来源。
不过这个故事引出了一个问题,如果在一群放在不同类目(baskets)中的物品(items)中寻找成对(pair)的物品,且物品在不同类目中出现了至少threshold次,那么应该怎样做是有效率(空间上)的呢?
最naive的方法对于N个items,需要的操作数是
假设![]()
为了解决占用内存过大问题,引入了Aprior算法。
先看下Wikipedia的说明。先验算法(英语:Apriori algorithm)是关联式规则中的经典算法之一。在关联式规则中,一般对于给定的项目集合baskets(例如,零售交易集合,每个集合都列出的单个商品的购买信息),算法通常尝试在项目集合中找出至少有threshold个相同的子集。先验算法采用自底向上的处理方法,即频繁子集每次只扩展一个对象(该步骤被称为候选集产生),并且候选集由数据进行检验。当不再产生符合条件的扩展对象时,算法终止。
看起来好简单的算法,很快就实现了,但是跑起来慢得要死...最开始的版本,跑了一个晚上也没有跑完数据,优化后的依然不行,经过再次优化,最终优化版本30s跑完,可是我错过了Assignment提交的deadline

简单讲,Aprior算法就是利用了单调性:如果一个集合I,I中的物品都至少出现了threshold次,那么任意I的子集,不可能出现的次数少于threshold次(threshold在这里是指一个门限值)。
反过来讲,如果一个物品i出现次数不到threshold,那么凡是包含了i的集合,都不可能出现超过threshold次。
一般的实现思路是:
这样需要的内存就是最常出现的items的平方了
一图胜千言,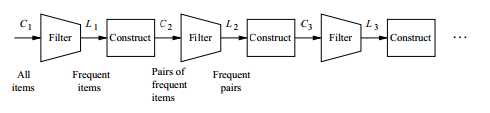
该流程迭代到
有10000个basket,同时有10000个数,第i个basket里放的都是能够整除i的数,举个例子:
解决这个问题,我们按照上方提到的算法,先构造k-tuple,将其通过过滤器,获取符合条件的的k-tuple,然后再将k-tuple构造成(k+1)-tuple,再继续迭代即可。
举一个简单的例子:
实际上,在生成(k+1)-tuple, 和过滤器这一步,有很多细节。如果剪枝剪得不充分,就会时间复杂度特别高,运行起来极其耗时。
根据这个算法,我们需要一个这样的函数:construct_filter(baskets_set, last_result, length)
这个函数的作用是,将candidate items输入,构造新的,长度为length的tuple,并对其过滤输出。其中baskets_set是我们要用于检查新tuple是否合格的源
第一个问题,如何构造(k+1)-tuple?
我的解决方法是,从
1 2 3 4 5 6 7 8 | for atuple in last_result: for index in range(len(atuple)): candidate_set.add(atuple[index]) if atuple[index] in source.keys(): source[atuple[index]].add(atuple) else: source[atuple[index]] = set() source[atuple[index]].add(atuple) |
显然,这样的实现有个很大的问题,在过滤时要遍历整个baskets,不必要的计算使得运行时间几个小时都跑不完。根据Apriori,
反过来讲,如果一个物品i出现次数不到threshold,那么凡是包含了i的集合,都不可能出现超过threshold次。
这里应该剪枝,不应该遍历整个baskets,而应该遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | for atuple in last_result: # shrinke the set temp_set = candidate_set - set(atuple) # construct new (k+1)tuple temp_list = [] for num in temp_set: # make sure this tuple never checked before temp_list = list(atuple) temp_list.append(num) temp_list.sort() current_tuple = tuple(temp_list) if current_tuple not in history: history.add(current_tuple) else: continue # count the frequent via basket_set # find the source of num:source[num] is a set temp_basket_set = set() for aset in basket_set[atuple]: if num in baskets[aset]: temp_basket_set.add(aset) if len(temp_basket_set) > threshold: result.append(current_tuple) new_basket_set[current_tuple] = temp_basket_set print("one answer:" + str(current_tuple)) |
在这次作业中,我耗费了大量时间,错过了deadline,存在以下问题:
总而言之,自己过于自信,在自己不熟悉的情况下没有敬畏之心,在自己没有构思好整体思路时直接处理细节,导致我在处理过程中跟无头苍蝇一样。
通过这次作业,对python比较熟悉了,不得不说,python的api设计的很符合人的直觉,set的运算也非常好用。
标签:
原文地址:http://www.cnblogs.com/yilujuechen/p/4850903.html