标签:
学习Qt也有段时间了,前一阵子想着写一个Qt版的博客园桌面端。现阶段主要想实现:
(1)显示博客园主页的推荐的那个些文章的条目(包括作者的图像、该博客的浏览次数、发布时间等)。
(2)可以登陆自己的博客园账号,并显示自己的博客文章。
(3)点击显示的博客文章条目时可以弹出窗口显示该片博客的内容。
同时还要实现自动刷新功能。
但是在编写的过程中,需要跟reply回来的html文档打交道,需要一个可以解析html文档的库。我在网上搜索了找到了C++编写的html解析库有htmlcxx、和google的gumbo-parser,还有几个其他的库,使用较多的是htmlcxx和gumbo-parser。但是在实际的使用中,我发现htmlcxx虽然解析的很好但是使用起来很不方便,不能够自己定制类似于JS的document.getElementById()以及document.getElementByName()这样的函数,同时查找html标签也很困难(可能是我没有深入的研究,个人感觉),而gumbo-parser是linux和unix下的,因为里面用到了几个函数在windows上没有提供位于string.h头文件,所以基于这个情况,我便自己编写了一个html文档解析库。经过了很多页面的测试,解析的比较准确,至少我使用博客园首页的html源码解析时通过自己的get_element_by_id函数能正确的获取到各个标签节点。
在完成该桌面端之后,我会把源代码贡献出来,同时也会给出一些使用的案例。希望对大家有帮助,该库会在以后不断的扩展,实现CSS选择器选取标签元素的功能,使我们可以更方便的使用。
现在不废话了,直接上一个小案例。
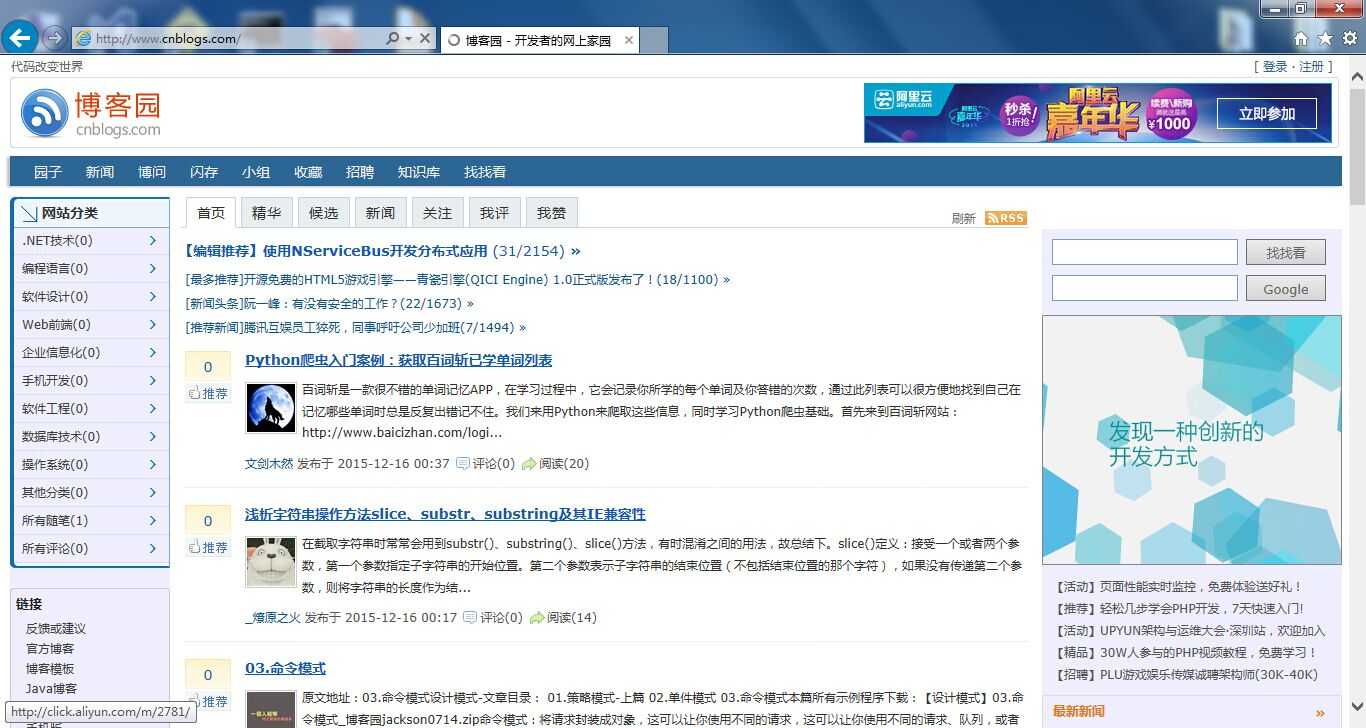
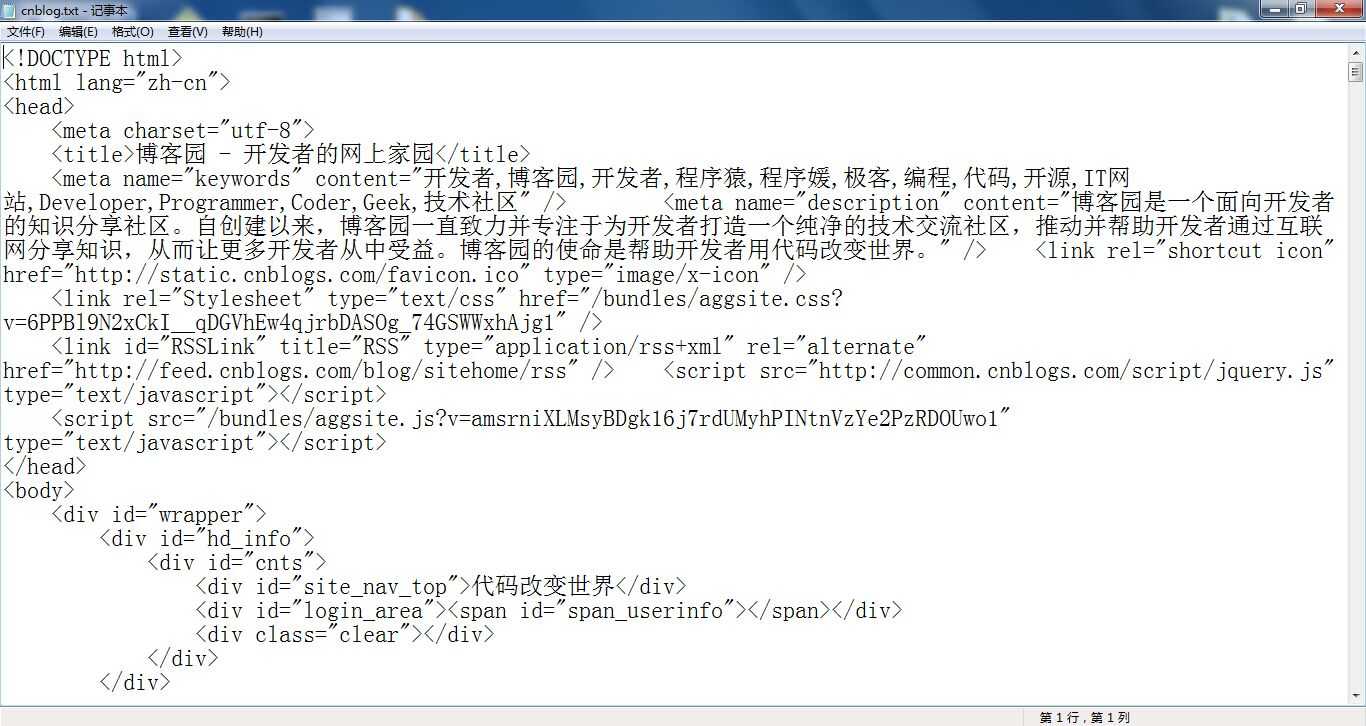
首先,我们需要准备博客园首页的html文档(在浏览器页面中邮件选择源码既可以获得,然后赋值粘贴保存到一个txt文件中)。
然后,分析一下博客园中间部分推荐的博客文章的条目,在该html中的结构。可以看到这20个条目全部包含在一个id=‘post_list‘的div中,而每一个条目又是包含在class=‘post_item‘的div中。
<div id="post_list"> <div class="post_item"> <div class="digg"> <div class="diggit" onclick="DiggPost(‘wenjianmuran‘,5049966,256767,1)"> <span class="diggnum" id="digg_count_5049966">0</span> </div> <div class="clear"></div> <div id="digg_tip_5049966" class="digg_tip"></div> </div> <div class="post_item_body"> <h3> <a class="titlelnk" href="http://www.cnblogs.com/wenjianmuran/p/5049966.html" target="_blank">Python爬虫入门案例:获取百词斩已学单词列表</a> </h3> <p class="post_item_summary"> <a href="http://www.cnblogs.com/wenjianmuran/" target="_blank"><img width="48" height="48" class="pfs" src="http://pic.cnblogs.com/face/728333/20151201230814.png" alt=""/></a> 百词斩是一款很不错的单词记忆APP,在学习过程中,它会记录你所学的每个单词及你答错的次数,通过此列表可以很方便地找到自己在记忆哪些单词时总是反复出错记不住。我们来用Python来爬取这些信息,同时学习Python爬虫基础。首先来到百词斩网站:http://www.baicizhan.com/logi... </p> <div class="post_item_foot"> <a href="http://www.cnblogs.com/wenjianmuran/" class="lightblue">文剑木然</a> 发布于 2015-12-16 00:37 <span class="article_comment"> <a href="http://www.cnblogs.com/wenjianmuran/p/5049966.html#commentform" title="" class="gray">评论(0)</a> </span> <span class="article_view"> <a href="http://www.cnblogs.com/wenjianmuran/p/5049966.html" class="gray">阅读(20)</a> </span> </div> </div> <div class="clear"></div> </div> </div>
接下来,就是需要解析并获取这些条目的标题并输出。
#ifndef HTML_ #define HTML_ #include <Windows.h> #include <string> #include <iostream> std::string html; void init_html(){ HANDLE hFile = CreateFile(TEXT("./cnblog.txt"), GENERIC_READ, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL); if (hFile != INVALID_HANDLE_VALUE){ int size = GetFileSize(hFile, NULL); std::cout << "file size : " << size << std::endl; char * p = new char[size + 1]; DWORD dwReads; ReadFile(hFile, p, size, &dwReads,NULL); p[dwReads] = 0; CloseHandle(hFile); AllocConsole(); html.assign(p); delete [] p; }else{ std::cout << "can not open file" << std::endl; } } #endif
上面是读取html文档内容的函数。(需要注意的是:使用该方式读取的时需要将文件保存为ANSI格式的,否则会出现中文乱码)
#include "htmlparser.h" #include "parentnode.h" #include "html.h" using namespace std; int main(){ init_html(); hunter::HtmlParser parser; parser.parser_html(html.c_str()); std::cout << "finished parser..." << std::endl; Node * node = parser.get_element_by_id(std::string("post_list")); if (parser.error().empty()){ if (node == 0){ std::cout << "Can‘t find this node..." << std::endl; } else{ std::vector<Node *> childs = parser.get_childs_by_class(node, "div", "class", "post_item"); for (int i = 0; i<childs.size(); i++){ Node * divnode = childs.at(i); std::vector<Node *> divchilds = parser.get_childs_by_class(divnode, "div", "class", "post_item_body"); if (divchilds.size()>0){ Node * divchild = divchilds.at(0); Node * h3 = parser.get_child_tag(divchild, "h3"); if (h3 != 0){ Node * a = parser.get_child_tag(h3, "a"); std::cout << parser.get_tag_text(a) << std::endl; } } } } } else{ std::cout << parser.error() << std::endl; } std::cin.get(); return 0; }
解析html,同时使用了几个函数parser.get_element_by_id(std::string("post_list"))、parser.get_childs_by_class(node, "div", "class", "post_item")、parser.get_child_tag(divchild, "h3")和parser.get_tag_text(a)。这些函数是用来获取相应标签节点的,好了下面看下输出的结果:
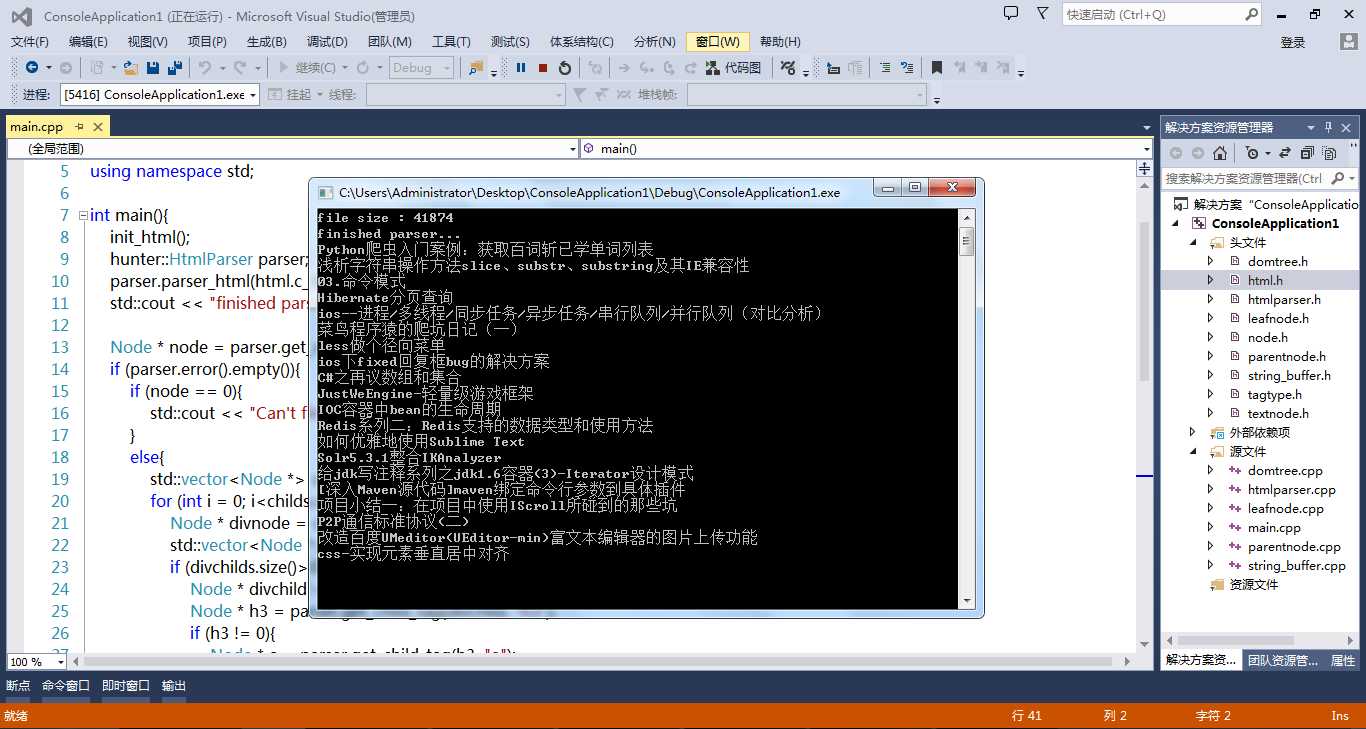
看看,是不是解析并成功获取到了首页20个条目的信息。
标签:
原文地址:http://www.cnblogs.com/gis-user/p/5050005.html