标签:
堆是一棵顺序存储的完全二叉树。
其中每个结点的关键字都不小于其孩子结点的关键字,这样的堆称为大根堆。
其中i=1,2,…,n/2向下取整;

堆排序的基本思想:
首先,按堆的定义将数组R[0..n]调整为堆(这个过程称为创建初始堆),交换R[0]和R[n];
然后,将R[0..n-1]调整为堆,交换R[0]和R[n-1];
如此反复,直到交换了R[0]和R[1]为止。
以上思想可归纳为两个操作:
(1)根据初始数组去构造初始堆(构建一个完全二叉树,保证所有的父结点都比它的孩子结点数值大)。
(2)每次交换第一个和最后一个元素,输出最后一个元素(最大值),然后把剩下元素重新调整为大根堆。
当输出完最后一个元素后,这个数组已经是按照从小到大的顺序排列了。
 核心代码
核心代码
1.堆
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2]
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
2.堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
操作过程如下:
1)初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
下面举例说明:
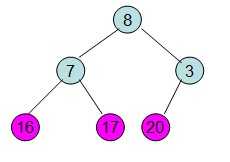
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
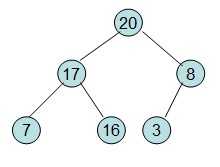
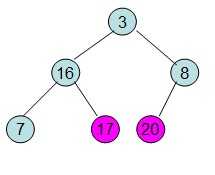
首先根据该数组元素构建一个完全二叉树,得到
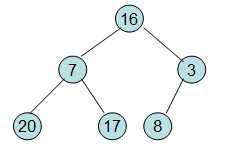
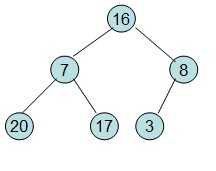
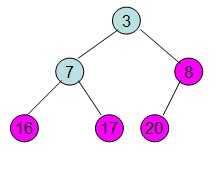
 20和16交换后导致16不满足堆的性质,因此需重新调整
20和16交换后导致16不满足堆的性质,因此需重新调整
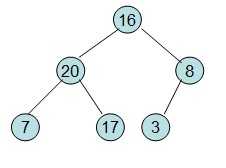
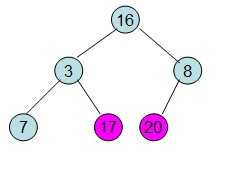
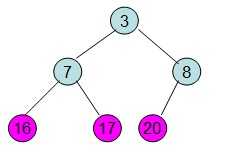
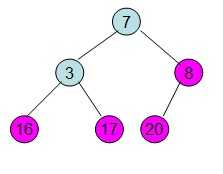
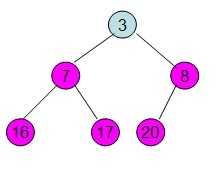
 这样就得到了初始堆。
这样就得到了初始堆。
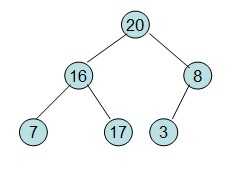
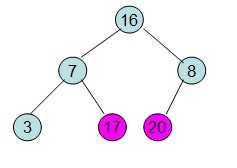
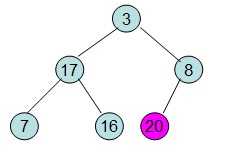 此时3位于堆顶不满堆的性质,则需调整继续调整
此时3位于堆顶不满堆的性质,则需调整继续调整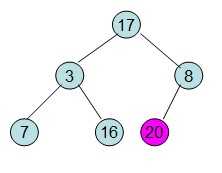
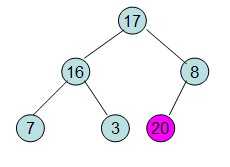
/*堆排序(大顶堆) 2011.9.14*/
#include <iostream>
#include<algorithm>
using namespace std;
void HeapAdjust(int *a,int i,int size) //调整堆
{
int lchild=2*i; //i的左孩子节点序号
int rchild=2*i+1; //i的右孩子节点序号
int max=i; //临时变量
if(i<=size/2) //如果i是叶节点就不用进行调整
{
if(lchild<=size&&a[lchild]>a[max])
{
max=lchild;
}
if(rchild<=size&&a[rchild]>a[max])
{
max=rchild;
}
if(max!=i)
{
swap(a[i],a[max]);
HeapAdjust(a,max,size); //避免调整之后以max为父节点的子树不是堆
}
}
}
void BuildHeap(int *a,int size) //建立堆
{
int i;
for(i=size/2;i>=1;i--) //非叶节点最大序号值为size/2
{
HeapAdjust(a,i,size);
}
}
void HeapSort(int *a,int size) //堆排序
{
int i;
BuildHeap(a,size);
for(i=size;i>=1;i--)
{
//cout<<a[1]<<" ";
swap(a[1],a[i]); //交换堆顶和最后一个元素,即每次将剩余元素中的最大者放到最后面
//BuildHeap(a,i-1); //将余下元素重新建立为大顶堆
HeapAdjust(a,1,i-1); //重新调整堆顶节点成为大顶堆
}
}
int main(int argc, char *argv[])
{
//int a[]={0,16,20,3,11,17,8};
int a[100];
int size;
while(scanf("%d",&size)==1&&size>0)
{
int i;
for(i=1;i<=size;i++)
cin>>a[i];
HeapSort(a,size);
for(i=1;i<=size;i++)
cout<<a[i]<<"";
cout<<endl;
}
return 0;
}
堆排序算法的总体情况
| 排序类别 | 排序方法 | 时间复杂度 | 空间复杂度 | 稳定性 | 复杂性 | ||
| 平均情况 | 最坏情况 | 最好情况 | |||||
| 选择排序 | 堆排序 | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(1) | 不稳定 | 较复杂 |
时间复杂度
因为堆排序的时间复杂度是O(n+klog2n),若k≤n/log2n,则可得到的时间复杂度为O(n)。
算法稳定性
堆排序是一种不稳定的排序方法。
因为在堆的调整过程中,关键字进行比较和交换所走的是该结点到叶子结点的一条路径,
因此对于相同的关键字就可能出现排在后面的关键字被交换到前面来的情况。
以下范例是对上文提到的无序序列 { 1, 3, 4, 5, 2, 6, 9, 7, 8, 0 } 进行排序。

标签:
原文地址:http://www.cnblogs.com/nxxshxf/p/5151304.html
