标签:
catalogue
0. 引论 1. 数据结构的概念 2. 逻辑结构实例 2.1 堆栈 2.2 队列 2.3 树形结构 2.3.1 二叉树 3. 物理结构实例 3.1 链表 3.1.1 单向线性链表 3.1.2 单向循环链表 3.1.3 双向线性链表 3.1.4 双向循环链表 3.1.5 数组链表 3.1.6 链表数组 3.1.7 二维链表 3.2 顺序存储 4. 算法 4.1 查找算法 4.2 排序算法
0. 引论

0x1: 为什么要学习数据结构
N.沃思(Niklaus Wirth)教授提出
程序 = 算法 + 数据结构 以上公式说明了如下两个问题 1. 数据上的算法决定如何构造和组织数据(算法 -> 数据结构) 2. 算法的选择依赖于作为基础的数据结构(数据结构 -> 算法)
软件工程的观点
软件 = 程序 + 文档
0x2: 数值计算解决问题的一般步骤
数学模型 -> 选择计算机语言 -> 编出程序 -> 测试 -> 最终解答
数值计算的关键是
如何得出数学模型(方程)
程序设计人员比较关注程序设计的技巧
0x3: 求解非数值计算的问题
主要考虑的是设计出合适的数据结构及相应的算法,即
首先要考虑对相关的各种信息如何表示、组织和存储
因此,可以认为,数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作的学科
0x4: STL
STL(Standard Template Library,标准模板库)是算法和其他一些组件的集合,STL的目的是标准化组件。STL现在是C++的一部分,我们可以很方便地使用STL直接获得数据结构的特性以及操作集
Relevant Link:
http://www.cnblogs.com/LittleHann/p/4011614.html
1. 数据结构的概念
0x1: 相关术语
1. 数据: 是计算机化的信息载体 2. 数据元素: 是数据的基本单位,是数据集合中的个体(例如:结点、顶点、记录等) 3. 数据项: 是具有独立含义的数据最小单位,例如: 在田径比赛表中,一个选手的有关信息就是数据元素(记录),而选手参赛的项目就是数据项(字段)
0x2: 定义
1. 定义1: 数据元素之间的相互关系称为结构,带有结构的数据元素的集合称为数据结构 2. 定义2: 按某种逻辑关系组织起来的一批数据(或称带结构的数据元素的集合)应用计算机语言并按一定的存储表示方式把它们存储在计算机的存储器中,并在其上定义了一个运算的集合
0x3: 数据结构的三个层次
1. 逻辑结构: 数据元素间抽象化的相互关系(简称为数据结构),它与数据的存储无关,独立于计算机,它是从具体问题抽象出来的数学模型 1) 集合结构: 集合结构的集合中任何两个数据元素之间都没有逻辑关系,组织形式松散 2) 线性结构: 数据结构中线性结构指的是数据元素之间存在着"一对一"的前后关系 2.1) 结构中必须存在唯一的首元素 2.2) 结构中必须存在唯一的尾元素 2.3) 除首元素外,结构中的每个元素有且仅有一个前趋元素 2.4) 除尾元素外,结构中的每个元素有且仅有一个后继元素 3) 树状结构: 树状结构是一个或多个节点的有限集合,树型结构中的元素具有一对多的父子关系 3.1) 结构中必须存在唯一的根元素 3.2) 除根元素外,结构中的每个元素有且仅有一个前趋元素 3.3) 除叶元素外,结构中的每个元素拥有一到多个后继元素 4) 网络结构: 网状结构中的元素具有多对多的交叉映射关系 4.1) 结构中的每个元素都可以拥有任意数量的前趋和后继元素 4.2) 结构中的任意两个元素之间均可建立关联 2. 存储结构(物理结构): 存储结构是指数据结构在计算机中的表示(又称映像),也称物理结构。它包括数据元素的表示和关系的表示。数据的存储结构是逻辑结构用计算机语言的实现,它依赖于计算机语言 1) 顺序存储: 把逻辑上相邻的元素存储在物理位置上也相邻的存储单元里,元素之间的关系由存储单元的邻接关系来体现 1.1) 其优点是可以实现随机存取,每个元素占用最少的存储空间 1.2) 缺点是只能使用相邻的一整块存储单元,因此可能产生较多的外部碎片(零散存储区域碎片) 2) 链接存储: 不要求逻辑上相邻的元素在物理位置上也相邻,借助指示元素存储地址的指针表示元素之间的逻辑关系 2.1) 其优点是不会出现碎片现象,充分利用所有存储单元 2.2) 缺点是每个元素因存储指针而占用额外的存储空间,并且只能实现顺序存取 3) 索引存储: 在存储元素信息的同时,还建立附加的索引表。索引表中的每一项称为索引项,索引项的一般形式是: (关键字,地址) 3.1) 其优点是检索速度快 3.2) 缺点是增加了附加的索引表,会占用较多的存储空间 3.3) 另外,在增加和删除数据时要修改索引表,因而会花费较多的时间 4) 散列存储: 根据元素的关键字直接计算出该元素的存储地址,又称为Hash存储 4.1) 其优点是检索、增加和删除结点的操作都很快 4.2) 缺点是如果散列函数不好可能出现元素存储单元的冲突,而解决冲突会增加时间和空间开销 3. 运算(算法): 施加在数据上的运算包括运算的定义和实现 1) 运算的定义是针对逻辑结构的,指出运算的功能 2) 运算的实现是针对存储结构的,指出运算的具体操作步骤
1. 逻辑结构
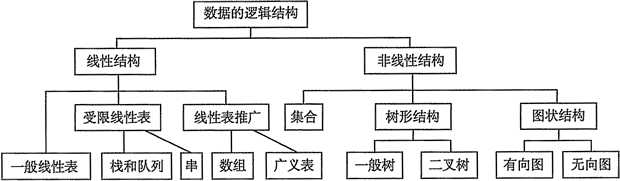
逻辑结构是指数据元素之间的逻辑关系,即从逻辑关系上描述数据。它与数据的存储无关,是独立于计算机的
逻辑结构是我们在学习数据结构时最重要的一个部分,本质上它是一种面向接口编程的范式思想,即不管底层物理存储采用何种方式和算法,逻辑结构规定了该结构"必须"要遵守的规范(例如pop、push),这表现为该数据结构的变化行为,而底层的物理存储方式解决了如何实现这些"接口范式"的需求
2. 存储结构(物理结构)
数据的存储结构是指数据的逻辑结构在计算机中的表示,顺序存储和链接存储是数据的两种最基本的存储结构
1. 在顺序存储中,每个存储空间含有所存元素本身的信息,元素之间的逻辑关系是通过数组下标位置简单计算出来的线性表的顺序存储,若一个元素存储在对应数组中的下标位置为i,则它的前驱元素在对应数组中的下标位置为i-1,它的后继元素在对应数组中的下标位置为i+1 2. 在链式存储结构中,存储结点不仅含有所存元素本身的信息,而且含有元素之间逻辑关系的信息,数据的链式存储结构可用链接表来表示。 其中data表示值域,用来存储节点的数值部分。Pl、p2、...、Pill(1n≥1)均为指针域,每个指针域为其对应的后继元素或前驱元素所在结点(以后简称为后继结点或前驱结点)的存储位置。通过结点的指针域(又称为链域)可以访问到对应的后继结点或前驱结点,若一个结点中的某个指针域不需要指向其他结点,则令它的值为空(NULL) 3. 在数据的顺序存储中,由于每个元素的存储位置都可以通过简单计算得到,所以访问元素的时间都相同 4. 而在数据的链接存储中,由于每个元素的存储位置保存在它的前驱或后继结点中,所以只有当访问到其前驱结点或后继结点后才能够按指针访问到,访问任一元素的时间与该元素结点在链式存储结构中的位置有关
在学习分析一个新的数据结构的时候,我们需要从逻辑结构和物理结构这2个不同的层次去理解,所有的数据结构和算法本质上都能在这个大的框架中找到对应的位置,所不同的只是为了解决特定领域的问题时,对一般化的数据结构附加了一些"额外的约束",使之表现出新的特性,同时解决了新的问题
3. 运算(算法)
所谓算法(Algorithm)是描述计算机解决给定问题的操作过程(解题方法),即为解决某一特定问题而由若干条指令组成的有穷序列
一个算法必须满足以下五个准则
1. 有穷性: 执行了有限条指令后一定要终止 2. 确定性(无二义): 算法的每一步操作都必须有确切定义,不得有任何歧义性 3. 可(能)行性: 算法的每一步操作都必须是可行的,即每步操作均能在有限时间内完成 4. 输入数据: 一个算法有n(n>=0)个初始数据的输入 5. 输出数据: 一个算法有一个或多个与输入有某种关系的有效信息的输出
Relevant Link:
http://baike.baidu.com/view/540423.htm http://student.zjzk.cn/course_ware/data_structure/web/gailun/gailun1.1.1.htm http://c.biancheng.net/cpp/html/2649.html http://baike.baidu.com/view/2820182.htm
2. 逻辑结构实例
2.1 堆栈
0x1: 基于顺序表的堆栈
#include <stdio.h> #include <stdbool.h> #define LISTSIZE 10 typedef int DataType; struct Stack { DataType data[LISTSIZE]; int top; //处了记录大小 还可以记录栈顶位置 }; void init(struct Stack* stack) { stack->top = 0; } bool empty(struct Stack* stack) { return stack->top == 0; } void push(struct Stack* stack, DataType d) { if (stack->top == LISTSIZE) return; stack->data[stack->top++] = d; } void pop(struct Stack* stack) { if (empty(stack)) return; stack->top--; } DataType topData(struct Stack* stack) { return stack->data[stack->top - 1]; } int main() { struct Stack stack; init(&stack); push(&stack, 30); push(&stack, 60); push(&stack, 80); while (!empty(&stack)) { printf("%d ", topData(&stack)); pop(&stack); } printf("\n"); return 0; }
0x2: 基于链式存储结构的堆栈
#include <stdio.h> #include <stdlib.h> #include <stdbool.h> typedef int DataType; struct Stack { DataType data; struct Stack *next; }; void init(struct Stack** top) { *top = NULL; } bool empty(struct Stack* top) { return top == NULL; } void push(struct Stack** top, DataType d) { struct Stack *newNode = (struct Stack*)malloc(sizeof(struct Stack)); newNode->data = d; newNode->next = *top; *top = newNode; } void pop(struct Stack** top) { if (empty(*top)) return; struct Stack *tempNode = *top; *top = (*top)->next; free(tempNode); } void topData(struct Stack* top, DataType* data) { if (empty(top)) return; *data = top->data; } int main() { struct Stack *top; init(&top); push(&top, 30); push(&top, 60); push(&top, 80); while (!empty(top)) { int data; topData(top, &data); printf("%d ", data); pop(&top); } printf("\n"); return 0; }
0x3: STL Stack
C++ STL Stack(堆栈)是一个容器类的改编,为程序员提供了堆栈的全部功能,——也就是说实现了一个先进后出(FILO)的数据结构。C++ STL栈stack的头文件为:
#include <stack>
C++ STL栈stack的成员函数介绍
empty(): 堆栈为空则返回真
pop(): 移除栈顶元素
push(): 在栈顶增加元素
size(): 返回栈中元素数目
top(): 返回栈顶元素
1. 代码举例1
#include "stdafx.h" #include <stack> #include <vector> #include <deque> #include <iostream> using namespace std; int _tmain(int argc, _TCHAR* argv[]) { deque<int> mydeque(2,100); vector<int> myvector(2,200); stack<int> first; stack<int> second(mydeque); stack<int,vector<int> > third; stack<int,vector<int> > fourth(myvector); cout << "size of first: " << (int) first.size() << endl; cout << "size of second: " << (int) second.size() << endl; cout << "size of third: " << (int) third.size() << endl; cout << "size of fourth: " << (int) fourth.size() << endl; return 0; }
2. 代码举例2
#include <iostream> #include <stack> using namespace std; int main () { stack<int> mystack; int sum (0); for (int i=1;i<=10;i++) mystack.push(i); while (!mystack.empty()) { sum += mystack.top(); mystack.pop(); } cout << "total: " << sum << endl; return 0; }
3. 代码举例3
#include <iostream> #include <stack> using namespace std; int main () { stack<int> mystack; for (int i=0; i<5; ++i) mystack.push(i); cout << "Popping out elements..."; while (!mystack.empty()) { cout << " " << mystack.top(); mystack.pop(); } cout << endl; return 0; }
Relevant Link:
http://www.cplusplus.com/reference/stack/stack/ http://www.169it.com/article/2839007600903800247.html
2.2 队列
0x1: 基于顺序表的队列
#include <stdio.h> #include <stdbool.h> #define QueueSize 6 typedef int DataType; typedef struct _Queue2{ DataType data[QueueSize]; int front; int rear; }Queue2; void init(Queue2* q){ q->front = q->rear = 0; } bool empty(Queue2* q){ return q->rear == q->front; } /* -> empty full -arraysize ~ 0 ~ arraysize */ bool full(Queue2* q){ return q->rear - q->front == QueueSize; } bool push(Queue2* q, DataType d){ if(full(q)) return false; q->data[q->rear++ % QueueSize] = d; return true; } bool pop(Queue2* q){ if(empty(q)) return false; q->front++; return true; } DataType getFront(Queue2* q){ return q->data[q->front % QueueSize]; } int main(int argc, const char * argv[]){ int i = 0; Queue2 q2; init(&q2); for (i = 0; i < 6; i++) { push(&q2, i); } pop(&q2); push(&q2, 300); pop(&q2); pop(&q2); push(&q2, 200); while (!empty(&q2)) { printf("%d ", getFront(&q2)); pop(&q2); } printf("\n"); return 0; }
0x2: 基于链式表的队列
#include <stdio.h> #include <stdlib.h> #include <stdbool.h> typedef int DataType; typedef struct _Queue{ DataType data; struct _Queue* next; }Queue; void init(Queue** front, Queue** rear){ *front = NULL; *rear = NULL; } bool empty(Queue* node){ return node == NULL; } void push(Queue** front, Queue** rear, DataType d){ Queue* newNode = (Queue*)malloc(sizeof(Queue)); newNode->data = d; newNode->next = NULL; if(!empty(*rear)) (*rear)->next = newNode; *rear = newNode; //如果队尾指针为空,则表示此时队中没有元素,所以直接将队尾指针指向新创建的队元素节点即可 if(empty(*front)) *front = *rear; } void pop(Queue** front, Queue** rear){ if(empty(*rear)) return; Queue* tempNode = *front; *front = (*front)->next; free(tempNode); //判断删除一个队元素后,队是否为空,如果队中没有元素了,也应该将队尾指针置为空,否则队尾指针将是野指针 if(empty(*front)) *rear = NULL; } void topData(Queue* front, DataType* data){ if(empty(front)) return; *data = front->data; } int main(){ Queue* front, *rear; init(&front, &rear); push(&front, &rear, 30); push(&front, &rear, 60); push(&front, &rear, 80); while (!empty(front)) { int data; topData(front, &data); printf("%d ", data); pop(&front, &rear); } printf("\n"); return 0; }
0x3: STL Queue
queue模板类的定义在<queue>头文件中
与stack模板类很相似,queue模板类也需要两个模板参数,一个是元素类型,一个容器类型,元素类型是必要的,容器类型是可选的,默认为deque类型
queue的基本操作有
push入队,q.push(x); 将x接到队列的末端
pop: 出队,q.pop(); 弹出队列的第一个元素,注意,并不会返回被弹出元素的值
front: 访问队首元素,q.front(),即最早被压入队列的元素
back: 访问队尾元素,q.back(),即最后被压入队列的元素
empty: 判断队列空,q.empty(),当队列空时,返回true
size: 返回队列中的元素个数,q.size()
1. 示例代码1
#include <cstdlib> #include <iostream> #include <queue> using namespace std; int main() { int e,n,m; queue<int> q1; for(int i=0;i<10;i++) q1.push(i); if(!q1.empty()) cout<<"dui lie bu kong\n"; n=q1.size(); cout<<n<<endl; m=q1.back(); cout<<m<<endl; for(int j=0;j<n;j++) { e=q1.front(); cout<<e<<" "; q1.pop(); } cout<<endl; if(q1.empty()) cout<<"dui lie bu kong\n"; system("PAUSE"); return 0; }
2. 示例代码2
#include <iostream> #include <queue> #include <assert.h> /* 调用的时候要有头文件: #include<stdlib.h> 或 #include<cstdlib> + #include<queue> #include<queue> 详细用法: 定义一个queue的变量 queue<Type> M 查看是否为空范例 M.empty() 是的话返回1,不是返回0; 从已有元素后面增加元素 M.push() 输出现有元素的个数 M.size() 显示第一个元素 M.front() 显示最后一个元素 M.back() 清除第一个元素 M.pop() */ using namespace std; int _tmain(int argc, _TCHAR* argv[]) { queue <int> myQ; cout<< "现在 queue 是否 empty? "<< myQ.empty() << endl; for(int i =0; i<10 ; i++) { myQ.push(i); } for(int i=0; i<myQ.size(); i++) { printf("myQ.size():%d\n",myQ.size()); cout << myQ.front()<<endl; myQ.pop(); } system("PAUSE"); return 0; }
Relevant Link:
http://www.cnblogs.com/LittleHann/p/4392061.html http://blog.csdn.net/wangshihui512/article/details/8930652 http://www.cplusplus.com/reference/queue/queue/ http://www.169it.com/article/2718050585107790752.html
2.3 树形结构
2.3.1 二叉树
0x1: 逻辑定义
1. 在计算机中,二叉树是指每个节点最多只有两个子节点的树形结构 2. 其中起始节点叫做根节点,整棵二叉树只有一个根节点。除了根节点之外,每个节点都有一个唯一的父节点 3. 其中没有任何子节点的节点叫做叶子节点,除了叶子节点之外,每个节点最多有两个子节点,即叶子节点只有父节点没有子节点 4. 除了根节点和叶子节点之外,剩下的节点叫枝节点,枝节点既有父节点也有子节点 5. 满二叉树: 如果该二叉树中每层节点均达到最大值,即每个枝节点都有两个子节点,则该二叉树叫满二叉树 6. 完全二叉树: 如果该二叉树中除了最下面一层之外,每层节点个数均达到最大值,并且最下面一层的节点都连续集中在左侧,则该二叉树叫做完全二叉树 7. 有序二叉树: 满足下列条件的非空二叉树即为有序二叉树 1) 若左子树非空,则左子树上所有节点的值均小于等于根节点(传递性) 2) 若右子树非空,则右子树上所有节点的值均大于等于根节点(传递性) 3) 左右子树亦分别为有序二叉树(递归) 8. 二叉树具有递归嵌套的空间结构,也就是说对于一棵二叉树来说,可以拆分为若干个小二叉树组成,因为这种逻辑结构,采用递归的方法处理二叉树比较方便 if(空树) 直接处理完毕 else { 处理根节点; 处理左子树; => 递归 处理右子树; => 递归 }
二叉树是一种逻辑结构的概念,在物理存储层面上,可以采用顺序/链式方式存储
0x2: 物理存储方式
1. 顺序存储结构: 一般来说,从上到下,从左到右依次存储节点,对于非完全二叉树来说,采用虚节点来补全二叉树 2. (二叉链表)链式存储结构: 一般来说,每个节点中除了存储数据元素本身之外,还需要两个指针,分别记录左右子节点的地址 typedef struct Node{ int data; struct Node* left; struct Node* right; } 3. (三叉链表)链式存储结构: 每个节点包括四个域 1) 数据域 2) 两个分别指向其左右子节点的指针域 3) 指向其父节点的指针域
0x3: 基本操作(算法)
1. 创建 2. 销毁 3. 插入新元素 4. 删除元素 5. 查找指定的元素 6. 修改指定的元素 7. 判断二叉树是否为满 8. 判断二叉树是否为空 9. 计算二叉树节点的个数 10. 获取根节点元素值 11. 遍历 1) 前序遍历: 对于从树根开始的每一课子树,先处理根节点中的数据,然后处理它的左子树,最后处理它的右子树,简单表示为DLR 2) 中序遍历: 对于从树根开始的每一棵子树,先处理它的左子树,然后处理根节点中的数据,最后处理它的右子树,简单表示为LDR 3) 后序遍历: 对于从树根开始的每一棵子树,先处理它的左子树,然后处理它的右子树,最后处理根节点中的数据,简单表示为LRD
1. 有序二叉树
1. 若左子树非空,则左子树上所有节点的值均小于根节点的值 2. 若右子树非空,则右子树上所有节点的值均大于等于根节点 3. 左右子树也分别递归地为有序二叉树
用途
1. 排序: 无论以何种顺序构建有序二叉树,其中序遍历的结果一定是一个有序序列 2. 搜索 1) 若搜索目标与根节点的值相等,则搜索成功,否则用搜索目标和根节点的值比较大小 2) 若搜索目标小于根节点的值,则在根节点的左子树中继续搜索,否则在根节点的右子树中继续搜索 3) 以递归的方式重复以上过程,知道搜索成功,或因子树不存在而宣告失败 4) 基于有序二叉树的搜索,可达到对数级的平均时间复杂度
bst.c
#include <stdio.h> #include <stdlib.h> typedef int DataType; typedef struct _Node{ DataType data; struct _Node* left; struct _Node* right; }Node; Node* createNode(DataType d){ Node* pn = (Node*)malloc(sizeof(Node)); pn->data = d; pn->left = pn->right = NULL; return pn; } void insert(Node** root, Node* pn){ if(pn == NULL) return; if(*root == NULL){ *root = pn; return; } if(pn->data > (*root)->data){ insert(&(*root)->right, pn); } else{ insert(&(*root)->left, pn); } } void delete(Node** root, DataType k){ Node* p, *f, *s, *q; p = *root; f = NULL; //search the node whose data == k while(p){ if(p->data == k) break; //f is point to p‘s parent f = p; if(p->data > k) p = p->left; else p = p->right; } //when break to here, means have benn find out the node if(p == NULL) return; if(p->left == NULL){ //p is the root if(f == NULL) *root = p->right; else if(f->left == p) f->left = p->right; else f->right = p->right; free(p); } else{ q = p; s = p->left; while(s->right){ q = s; s = s->right; } if(q == p) q->left = s->left; else q->right = s->left; p->data = s->data; free(s); } } Node* find(Node* root,DataType d){ if(root == NULL) return NULL; if(d > root->data) return find(root->right, d); else if(d < root->data) return find(root->left, d); else return root; } void modify(Node* root, DataType oldData, DataType newData){ Node* p; p = find(root, oldData); p->data = newData; } void clears(Node** root){ if(*root == NULL) return; clears(&(*root)->left); clears(&(*root)->right); free(*root); *root = NULL; } void print(Node* root) { if (root == NULL) return; printf("%d ", root->data); print(root->left); print(root->right); } int main() { Node* root = NULL; insert(&root, createNode(10)); insert(&root, createNode(5)); insert(&root, createNode(3)); insert(&root, createNode(2)); insert(&root, createNode(1)); insert(&root, createNode(4)); insert(&root, createNode(7)); insert(&root, createNode(6)); insert(&root, createNode(9)); insert(&root, createNode(8)); insert(&root, createNode(15)); print(root); printf("\n"); printf("%d\n", find(root, 5)->data); delete(&root, 10); print(root); return 0; }
3. 物理结构实例
3.1 链表
0x1: 链表的基本运算
1. 追加: 在链表的尾部添加新元素 2. 插入: 在特定位置的元素之前或之后加入新元素 3. 删除: 删除特定位置的元素 4. 遍历: 依次访问链表中的每个元素,不重复、不遗漏
3.1.1 单向线性链表
0x1: 定义
链表(Linked List)是由节点组成的(node)。而节点实质上是一个数据结构(struct or class)。链表和数组(Array)的区别在于链表中的节点在内存中的位置不一定是连续的,并且节点个数无需在编译时确定
节点包含两种信息
1. 一种是数据(data) 2. 一种是指向另一个节点的指针(指针实质上存储的是节点的物理位置) 3. 链表尾节点的指针为空指针
链表结构定义
struct student { long num; /*学号 */ float score; /*分数,其他信息可以继续在下面增加字段 */ struct student *next; /*指向下一结点的指针 */ };

0x2: 操作
#include <stdio.h> #include <stdbool.h> #include <stdlib.h> typedef int DataType; typedef struct _Node{ DataType data; struct _Node *next; }Node; void init(Node** head){ *head = NULL; } int getSize(Node *head){ Node* p = head; int count = 0; while(p){ count++; p = p->next; } return count; } Node* getptr(Node* head, int pos){ Node* p = head; int i = 0; if(p == 0 || pos == 0){ return head; } for(i = 0; p && i < pos; i++){ p = p->next; } return p; } bool insert(Node** head, int position, DataType d){ if(position < 0 || position > getSize(*head)){ return false; } //create node Node* node = (Node*)malloc(sizeof(Node)); node->data = d; node->next = NULL; //insert before the first node if(position == 0){ node->next = *head; *head = node; return true; } //insert between the node linktable Node* p = getptr(*head, position - 1); Node* r = p->next; node->next = r; p->next = node; return true; } bool erases(Node** head, int pos){ if(pos < 0 || pos >= getSize(*head)) return false; Node* p = *head; if(pos == 0){ *head = (*head)->next; free(p); p = NULL; return true; } p = getptr(*head, pos - 1); Node* q = p->next; p->next = q->next; free(q); q = NULL; return true; } bool set(Node* head, int pos, DataType d){ if(pos < 0 || pos >= getSize(head)) return false; Node* p = getptr(head, pos); p->data = d; return true; } void clears(Node* head){ while(head){ Node* p = head->next; free(head); head = p; } } void print(Node* head) { Node *p = head; while (p) { printf("%d ", p->data); p = p->next; } printf("\n"); } int main(){ Node* headList; init(&headList); insert(&headList, 0, 10); insert(&headList, 0, 20); insert(&headList, 0, 30); insert(&headList, 2, 40); insert(&headList, 2, 50); insert(&headList, 0, 60); insert(&headList, 0, 80); print(headList); erases(&headList, 0); print(headList); set(headList, 0, 100); set(headList, 0, 110); print(headList); return 0; }
3.1.2 单向循环链表
0x1: 定义
1. 每个节点依旧跟单向链表一样,包含一个指向下一节点的指针 2. 最后一个节点不再指向NULL,指向第一个节点,构成环状 3. 单向循环链表可以从任意一个节点出发遍历整个链表

3.1.3 双向线性链表
0x1: 定义
由一系列内存中不连续的节点组成,每个节点除了保存数据以外,还需要保存其前后节点的地址,链表首节点的前指针和尾节点的后指针都为NULL,线性和循环的区别在于线性需要一个额外的head头指针来进行遍历
typedef struct Node { int data; struct Node *pNext; struct Node *pPre; }NODE, *pNODE;

0x2: 操作
1. 在给定节点之前插入 1) 创建持有待插入元素的新节点,令其前指针指向给定结点的前节点,令其后指针指向给定结点 2) 若新建结点存在前节点,则令其前节点的后指针指向新建结点,否则新建节点为新的首节点 3) 令新建结点的后节点的前指针指向新建节点 2. 删除节点 1) 若待删除节点存在前节点,则令其前节点的后指针指向待删除节点的后节点(链节点合并),否则待删除节点的后节点为新的首节点 2) 若待删除节点存在后节点,则令其后节点的前指针指向待删除节点的前节点,否则待删除节点的前节点为新的尾节点 3) 销毁待删除节点

#include <stdio.h> #include <stdbool.h> #include <stdlib.h> typedef int DataType; typedef struct _Node{ DataType data; struct _Node* pre, *next; }Node; void init(Node** head){ *head = NULL; } int getSize(Node* head){ Node* p = head; int count = 0; while(p){ count++; p = p->next; } return count; } Node* getptr(Node* head, int pos){ Node* p = head; int i = 0; if(p == 0 || pos == 0){ return head; } for(i = 0; p && i < pos; i++){ p = p->next; } return p; } bool insert(Node** head, int position, DataType d){ if(position < 0 || position > getSize(*head)){ return false; } //create node Node* node = (Node*)malloc(sizeof(Node)); node->data = d; node->pre = NULL; node->next = NULL; //insert before the first node if(position == 0){ node->next = *head; if(*head != NULL) (*head)->pre = node; *head = node; return true; } //insert between into the node linktable Node* p = getptr(*head, position - 1); Node* r = p->next; node->next = r; r->pre = node; p->next = node; node->pre = p; return true; } bool erases(Node** head, int pos){ if(pos < 0 || pos >= getSize(*head)) return false; //erase the first node Node* p = *head; if(pos == 0){ *head = (*head)->next; if(*head != NULL) (*head)->pre = NULL; free(p); p = NULL; return true; } //erase the node between the node linktable p = getptr(*head, pos - 1); Node* q = p->next; p->next = q->next; q->next->pre = p; free(q); q = NULL; return true; } bool set(Node* head, int pos, DataType d){ if(pos < 0 || pos >= getSize(head)){ return false; } Node* p = getptr(head, pos); p->data = d; return true; } void clears(Node* head){ while(head){ Node* p = head->next; free(head); head = p; } } void print(Node* head) { Node *p = head; while (p) { printf("%d ", p->data); p = p->next; } printf("\n"); } int main(){ //head point Node* headList; init(&headList); insert(&headList, 0, 10); insert(&headList, 0, 20); insert(&headList, 0, 30); insert(&headList, 2, 40); insert(&headList, 2, 50); insert(&headList, 0, 60); insert(&headList, 0, 80); print(headList); erases(&headList, 1); print(headList); set(headList, 0, 100); set(headList, 0, 110); print(headList); return 0; }
3.1.4 双向循环链表
0x1: 定义
1. 每个节点除了存放元素数据以外,还需要保存指向下一个节点的指针,即所谓的后指针,以及指向前一个节点的指针,即所谓的前指针 2. 链表首节点的前指针指向链表尾节点,尾节点的后指针指向首节点

3.1.5 数组链表
0x1: 定义
链表中的每个元素都是一个数组,即由数组构成的链表

3.1.6 链表数组
0x1: 定义
数组中的每一个元素都是一个链表,即由链表构成的数组

PHP内核的Hashtable就是采用这种物理存储结构
3.1.7 二维链表
0x1: 定义
链表中的每一个元素都一个链表

3.2 顺序存储
使用数组进行存储
4. 算法
0x1: 基本概念
1. 算法就是对解决问题的方案进行准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制 2. 算法中的指令描述的是一个计算过程,在它的作用下,系统从初始状态和初始输入(允许为空)开始,经历一些列有限且被明确定义的中间状态,最终产生所要求的输出,并停止于终止状态 3. 同一个问题,不同的算法,可能会在时间、空间等方面表现出明显的差异,一个算法的优劣可以用时间复杂度和空间复杂度来衡量
0x1: 基本特征
1. 有穷性: 算法必须能在执行有限个步骤后终止 2. 确切性: 算法的每个步骤都必须有确切的定义(DFN 有穷状态机) 3. 输入项: 算法有规范化的输入,以表示运算对象的初始状态 4. 输出项: 算法至少有一个输出,以反映处理的最终结果 5. 可行性: 算法中的每个执行步骤都必须能在有限时间内完成
0x3: 基本要素
1. 运算和操作: 计算机可以执行的基本操作是以指令的形式描述的,包括以下 1) 算法运算 1.1) 加 1.2) 减 1.3) 乘 1.4) 除 1.5) 模 .. 2) 关系运算 2.1) 大于 2.2) 小于 2.3) 等于 2.4) 不等于 .. 3) 逻辑运算 3.1) 与 3.2) 或 3.3) 非 .. 4) 数据传输 4.1) 输入 4.2) 输出 4.3) 赋值 2. 流程和控制: 算法的功能不仅取决于所选用的操作,还与各操作之间的执行顺序有关
0x4: 算法的评定标准
1. 时间复杂度: 算法的时间消耗与问题规模之间的函数关系: T(N) = O(F(N)) 1) 常数级复杂度: O(1) 2) 对数级复杂度: O(logN) 3) 线性级复杂度: O(N) 4) 线性对数级复杂度: O(NlogN) 5) 平方级复杂度: O(N2) 2. 空间复杂度: 算法的空间消耗与问题规模之间的函数关系: S(N) = O(F(N)) //原则上说,复杂度曲线越平越好,越陡越差,常数级复杂度最为理想 3. 正确性: 执行算法的结果是否满足要求 4. 可读性: 算法本身可供人们阅读的难易程度 5. 健壮性: 算法对非正常输入的反应和处理能力,也称容错性
0x5: 算法的思想方法
1. 递推法 1) 通过计算前面的一些项来得出序列中指定项的值 2) 其思想是把一个复杂而庞大的计算过程转化为简单过程的多次重复 2. 递归法 1) 把大问题转化为原问题相似的小问题来求解 2) 递归的神奇之处在于用有限的语句来定义无限的对象的集合 3) 递归需要有终止条件、递归前进段和递归返回段,若终止条件不满足则递归前进,否则递归返回 3. 穷举法 1) 对于要解决的问题,列举出它所有的可能性,逐个判断其中哪些符合问题所要求满足的条件,从而得到问题的解 4. 贪心算法 1) 自顶向下,以迭代的方式做出相继的贪心选择,没做一次贪心选择,就将所求问题简化为一个规模更小的子问题,通过每一步贪心选择,可得到相应子问题的一个最优解,虽然每一步都能够保证局部最优解,但最终得到的全局解未必最优 5. 分治法 1) 把一个复杂问题分成两个或更多相同或相似的子问题,再把子问题分成更小的子问题,知道最后的子问题可以简单地直接求解,原问题的解即子问题解的合并 6. 动态规划法 1) 将原问题分解为相似的子问题,在求解的过程中通过子问题的解求出原问题的解 7. 迭代法 1) 按照一定的规则,不断地用旧值推算出新值,直到满足某种特定条件为止 8. 分支界限法 1) 把全部可行的解空间不断分隔为越来越小的子集,称之为分支,并为每个子集计算一个下界或上界,称之为定界 2) 在每次分支后,对界限超出已知可行解的子集不再做进一步分支,搜索范围迅速收敛 3) 这一过程一直进行到找出可行解为止,该可行解的值不大于任何子集的界限,因此这种算法一般可以求得全局最优解 9. 回溯法 1) 在包含问题所有解的解空间树中,从根节点出发,按深度优先搜索解空间树,当搜索到某一节点时,先判断该节点是否包含问题的解,若包含则从该节点出发继续搜索,否则逐层向其父节点回溯 2) 若希望求得问题的所有解,则必须回溯到根,且根节点的所所有可行子树都必须被搜索到才能结束,否则只要搜索到问题的一个解即可终止
0x6: 算法的分类
1. 按照执行期限分类 1) 有限算法: 算法过程无论长短,总能在有限时间内终止 2) 无限算法: 算法过程因无终止条件或终止条件无法得到满足,而永不停息 2. 按照解的确定性分类 1) 确定性算法: 对于确定的输入,算法总能得到确定的结果 2) 非确定算法: 对于确定的输入,算法得到的结果并不唯一确定 3. 按照理论和应用的专门领域分裂 1) 基本算法: 数值分析算法 2) 排序算法: 数据结构算法 3) 搜索算法: 动态规划算法 4) 代数算法: 压缩解压算法 5) 几何算法: 加密解密算法 6) 数论算法: 数据摘要算法 7) 图论算法: 数据挖掘算法 8) 随机算法: 随机森林算法 9) 并行算法: 人工智能算法 10) 分类算法: 模式识别算法
4.1 查找算法
1. 线性查找
算法描述
1. 从头开始,依次将每一个元素与查找目标进行比较 2. 或者找到目标,或者找不到目标
伪码实现
for each item in the list if that item has the desired value stop the search and return the item‘s location return not found
总体评价
1. 平均时间复杂度: O(N) 2. 对数据的有序性没有要求
实例代码
#include <stdio.h> typedef char DataType; int mySearch(DataType* ts, int n, const DataType d){ int i = 0; for(i = 0; i < n; i++){ if(ts[i] == d) return i; } return -1; } int main(){ char cs[6] = {‘*‘, ‘A‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘}; printf("%d\n", mySearch(cs, 6, ‘*‘)); printf("%d\n", mySearch(cs, 6, ‘A‘)); }
2. 二分查找
算法描述
1. 假设表中的元素按升序排列 2. 若中间元素与查找目标相等,则查找成功,否则利用中间元素将表划分成前后两个子表 3. 若查找目标小于中间元素,则在前子表中查找,否则在后子表中查找 4. 重复以上过程,直到查找成功,或者因子表不存在而宣告失败
伪码实现
基于递归的二分查找 function binarySearch(a, value, left, right) if right < left return not found mid := floor( (right - left) / 2 ) + left if a[mid] == value return mid if value < a[mid] return binarySearch(a, value, left, mid - 1) else return binarySearch(a, value, mid + 1, right) 基于循环的二分查找 function binarySearch(a, value, left, right) while left <= right mid := floor( (right - left) / 2 ) + left if a[mid] == value return mid if value < a[mid] right := mid - 1 else left := mid + 1 return not found
总体评价
1. 平均时间复杂度: O(logN) 2. 数据必须有序
实例代码
#include <stdio.h> typedef char DataType; int mySearch(DataType *ts, int n, DataType d){ int L = 0; int R = n - 1; while(L <= R){ int M = (L + R) / 2; if(ts[M] == d) return M; if(ts[M] < d) L = M + 1; else R = M - 1; } return -1; } int main() { char cs[6] = {‘*‘,‘A‘,‘B‘,‘C‘,‘D‘,‘E‘}; printf("%d\n", mySearch(cs, 6, ‘*‘)); printf("%d\n", mySearch(cs, 6, ‘A‘)); printf("%d\n", mySearch(cs, 6, ‘D‘)); printf("%d\n", mySearch(cs, 6, ‘C‘)); }
4.2 排序算法
1. 冒泡排序
算法描述
1. 相邻元素两辆比较,前者大于后者,彼此交换 2. 从第一对到最后一对,最大的元素沉降到最后 3. 针对未排序部分,重复以上步骤,沉降次最大值 4. 每次扫描越来越少的元素,直至不再发生交换
伪码实现
procedure bubbleSort(A:list of sortable items) n = length(A) repeat swapped = false for i = 1 to n-1 inclusive do if A[i-1] > A[i] then swap(A[i-1], A[i]) swapped = true end if end for n = n - 1 until not swapped end procedure
总体评价
1. 平均时间复杂度: O(N2) 2. 稳定排序 3. 对数据的有序性非常敏感(swap的过程需要消耗时间)
代码示例
#include <stdio.h> #include <stdbool.h> typedef int DataType; void bubble(DataType* a, int n){ int i = 0, j = 0; for(i = 0; i < n-1; i++){ bool flag = true; for(j = 0; j < n-i-1; j++){ if(a[j] > a[j+1]){ DataType t = a[j]; a[j] = a[j+1]; a[j+1] = t; flag = false; } } if(flag) break; } } void print(DataType* a, int n) { int i = 0; for (i = 0; i < n; i++) printf("%d ", a[i]); printf("\n"); } int main() { int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0}; bubble(a, 10); print(a, 10); return 0; }
2. 插入排序
算法描述
1. 首元素自然有序 2. 取出下一个元素,对已排序序列,从后向前扫描 3. 大于被取出元素者后移 4. 小于等于被取出元素者,将被取出元素插入其后 5. 重复步骤2,直至处理完所有元素
伪码实现
for i = 1 to length(A) x = A[i] j = i while j > 0 and A[j-1] > x A[j] = A[j-1] j = j - 1 A[j] = x
总体评价
1. 平均时间复杂度: O(N2) 2. 稳定排序 3. 对数据的有序性非常敏感(即有序性影响最终的交换次数) 4. 不交换只移动,优于冒泡排序
代码示例
#include <stdio.h> #include <stdbool.h> typedef int DataType; void insert(DataType* a, int n){ int i = 0; for(i = 0; i < n; i++){ DataType t = a[i]; int j = 0; for(j = i; j > 0 && a[j-1] > t; j--){ a[j] = a[j-1]; } a[j] = t; } } void print(DataType* a, int n) { int i = 0; for (i = 0; i < n; i++) printf("%d ", a[i]); printf("\n"); } int main() { int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0}; insert(a, 10); print(a, 10); return 0; }
3. 选择排序
算法描述
1. 在整个序列中寻找最小元素,与首元素交换 2. 在剩余序列中寻找最小元素,与次首元素交换 3. 以此类推,直到剩余序列中仅包含一个元素
伪码实现
function selectionSort(list[1..n]) for i from 1 to n-1 minIndex = i for j from i+1 to n if list[j] < list[minIndex] minIndex = j swap list[i] and list[minIndex]
总体评价
1. 平均时间复杂度: O(N2) 2. 非稳定排序(相同元素在排序过程中可能会改变顺序) 3. 对数据的有序性不敏感(必须全量遍历完) 4. 交换次数少,优于冒泡排序
代码示例
#include <stdio.h> #include <stdbool.h> #include <algorithm> typedef int DataType; void selects(DataType* a, int n){ int i = 0; for(i = 0; i < n; i++){ int k = i; int j = 0; for(j = i + 1; j < n; j++){ if(a[j] < a[k]){ k = j; } } if(k != i){ std::swap(a[k], a[i]); } } } void print(DataType* a, int n) { int i = 0; for (i = 0; i < n; i++) printf("%d ", a[i]); printf("\n"); } int main() { int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0}; selects(a, 10); print(a, 10); return 0; }
4. 快速排序
算法描述
1. 从待排序序列中任意挑选一个元素,作为基准 2. 将所有小于基准的元素放在基准之前,大于基准的元素放在基准之后,等于基准的元素放在基准之前或之后,这个过程称为分组 3. 以递归的方式,分别对基准之前和基准之后的分组继续进行分组,直到每个分组内的元素个数不多于1为止
就地分组
1. 在不额外分配内存空间的前提下,完成分组过程
伪码实现
基于分组的排序 quickSort(A, i, k): if i < k: p := partition(A, i, k) quickSort(A, i, p-1) quickSort(A, P+1, K) 就地分组 partition(array left, right) pivotIndex := choosePivot(array, left, right) pivotValue := array(pivotIndex) i = left j = right while i < j while i < pivotIndex and array[i] <= pivotValue i = i + 1 if i < pivotIndex array[pivotIndex] = array[i] pivotIndex = i while j > pivotIndex and array[j] >= pivotValue j = j - 1 if j > pivotIndex array[pivotIndex] = array[j] pivotIndex = j array[pivotIndex] = pivotValue return pivotIndex
总体评价
1. 平均时间复杂度: O(NlogN) 2. 非稳定排序 3. 若每次都能均匀分组,则排序速度最快
实例代码
#include <stdio.h> #include <stdbool.h> typedef int DataType; void qsorts(DataType* a, int n){ if(n <= 1) return; int L = 0; int R = n - 1; while(L < R){ //R backing while(L < R && a[L] <= a[R]) R--; DataType t = a[L]; a[L] = a[R]; a[R] = t; //L going while(L < R && a[L] <= a[R]) L++; t = a[L]; a[L] = a[R]; a[R] = t; } qsorts(a, L); qsorts(a+L+1, n-L-1); } void print(DataType* a, int n) { int i = 0; for (i = 0; i < n; i++) printf("%d ", a[i]); printf("\n"); } int main() { int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0}; qsorts(a, 10); print(a, 10); return 0; }
5. 归并排序
算法描述
1. 将待排序序列从中间划分为两个相等的子序列 2. 以递归的方式分别对两个子序列进行排序 3. 将两个有序的子序列合并成完整序列
有序合并
1. 分配合并序列,其大小为两个有序序列大小之和 2. 设定两个指针,分别指向两个有序序列的首元素 3. 比较指针目标,较小者进入合并序列,指针后移 4. 重复步骤3,直到某一指针到达序列末尾 5. 将另一序列的剩余元素直接复制到合并序列末尾
伪码实现
基于合并的排序 function mergeSort(list m) if length(m) <= 1 return , var list left, right var integer middle = length(m) / 2 for each x in m before middle add x to left for each x in m after or equal middle add x to right left = mergeSort(left) right = mergerSort(right) return merge(left, right) 有序合并 function merge(left, right) var list result while length(left) > 0 or length(right) > 0 if length(left) > 0 and length(right) > 0 if first(left) <= first(right) append first(left) to result left = rest(left) else append first(right) to result rigth = rest(right) else if length(left) > 0 append first(left) to result left = rest(left) else if length(right) > 0 append first(right) to result right = rest(right) end while return result
总体评价
1. 平均时间复杂度: O(2NlogN) 2. 稳定排序 3. 对数据的有序性不敏感 4. 非就地排序,需要辅助空间,不适合处理海量数据
代码示例
#include<stdlib.h> #include<stdio.h> #define SIZE 8 void Merge(int sourceArr[], int startIndex, int midIndex, int endIndex){ int start = startIndex; int i, j, k; int tempArr[SIZE]; for(i=midIndex+1, j=startIndex; startIndex <= midIndex && i<=endIndex; j++){ if(sourceArr[startIndex] <= sourceArr[i]) tempArr[j] = sourceArr[startIndex++]; else tempArr[j] = sourceArr[i++]; } if(startIndex <= midIndex){ for(k = 0; k <= midIndex - startIndex; k++){ tempArr[j+k] = sourceArr[i+k]; } } for(i=start; i<=endIndex; i++) sourceArr[i] = tempArr[i]; } void MergeSort(int sourceArr[], int startIndex, int endIndex){ int midIndex; if(startIndex < midIndex){ midIndex = (startIndex + endIndex) / 2; MergeSort(sourceArr, startIndex, midIndex); MergeSort(sourceArr, midIndex + 1, endIndex); } } void print(int* a, int n) { int i = 0; for (i = 0; i < n; i++) printf("%d ", a[i]); printf("\n"); } int main() { int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0}; MergeSort(a, 0, 10); print(a, 10); return 0; }
Copyright (c) 2016 Little5ann All rights reserved
数据结构(DataStructure)与算法(Algorithm)、STL应用
标签:
原文地址:http://www.cnblogs.com/LittleHann/p/5191378.html