标签:
使用JavaScript在前端访问跨域页面常常用到Ajax,后端Node.js抓取网页信息就容易得多。
下面是一个最简单的例子,抓取我的博客主页信息,显示首页博客标题。
1 var http = require(‘http‘) 2 var cheerio = require(‘cheerio‘) 3 4 var url = ‘http://www.cnblogs.com/feitan/‘ 5 6 function filterHtml(html) { //使用cheerio处理DOM 7 var $ = cheerio.load(html) 8 9 var data = [] 10 var titles = $(‘.postTitle a‘) 11 titles.each(function(){ 12 data.push($(this).text()) 13 }) 14 15 return data 16 } 17 18 function outputInfo(data){ //数据进一步传递,这里直接输出 19 data.forEach(function(title){ 20 console.log(‘\n‘+ title) 21 }) 22 23 } 24 25 http.get(url,function(res){ //http模块get方法访问url资源 26 var html = ‘‘ 27 res.on(‘data‘,function(data){ 28 html+=data 29 }) 30 31 res.on(‘end‘,function(){ 32 var data = filterHtml(html) 33 outputInfo(data) 34 }) 35 }).on(‘error‘,function(){ 36 console.log(‘获取数据出错‘) 37 })
21行指定一个url资源发起get请求,回调函数处理响应对象response,response返回的是HTML文档。
对DOM处理使用了cheerio包,它类似jQuery对JavaScriptDOM操作的封装,使用方式也类似。
结果:
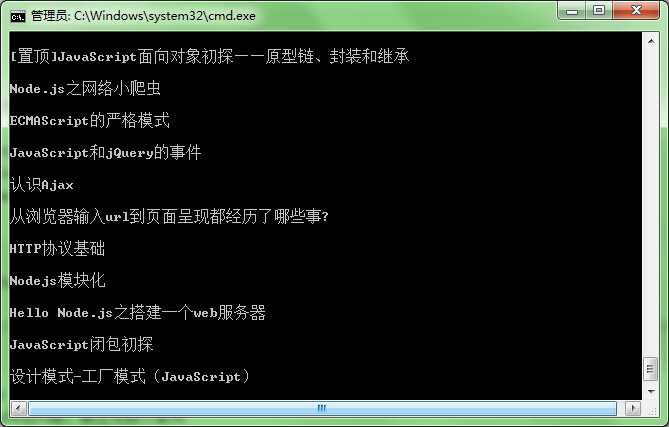
标签:
原文地址:http://www.cnblogs.com/feitan/p/5322665.html