标签:
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
一、前言
大家好,今天我要来讲讲一个比较实用的爬虫工具,抓取淘宝的关键字商品信息,即是:
输入关键字,按照价格等排序,抓取列出的商品信息以及下载图片,并且支持导出为Excel。
如果如下:
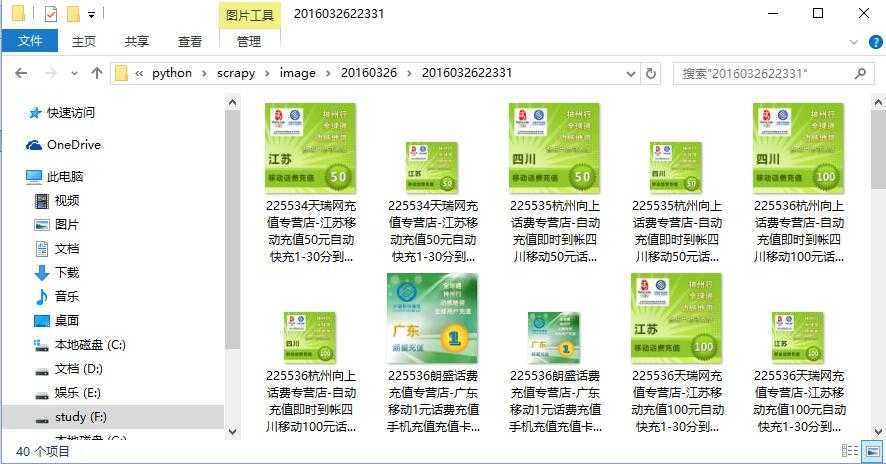
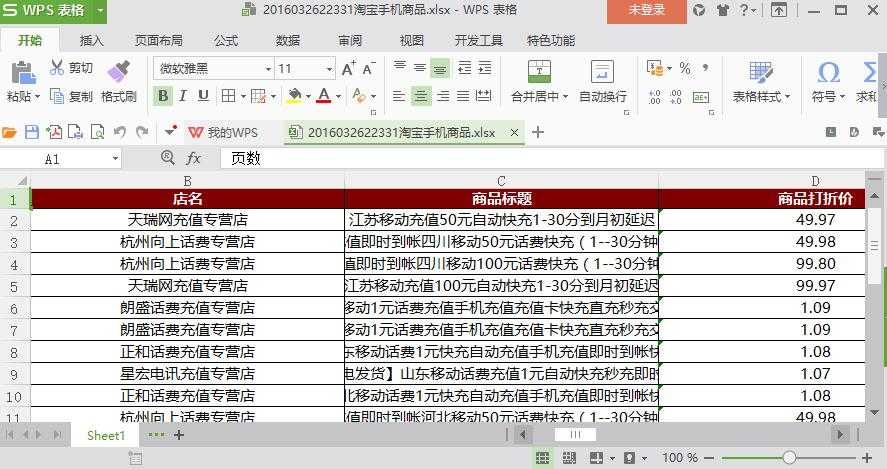
看完下面的讲解,Python语言就掌握得差不多,中级水平了,而且这个封装后的工具还是很好用的。
感觉自己萌萌哒~~
二、原理
大家知道什么叫爬虫,它也叫网络蜘蛛,机器人等,意思就是说自动的程序,可以去抓取使用网络协议传输的内容。
目前来讲爬虫主要使用在抓网站,即使用Http协议传输的各种数据,如html,xml和json等,也包括图片等二进制内容。
http协议主要有请求报文和响应报文,计算机网络必须学好,网络编程嘛!
发送一个请求报文给网站服务器,它就会回报一个响应报文,附带一些数据。
请求报文,后面带一堆头部,可能会携带数据,如post或get的时候:
GET www.baidu.com HTTP/1.1
...
响应报文,后面带头部还有数据:
HTTP/1.1 200 OK
..
以下为火狐F12的结果,仅供参考!
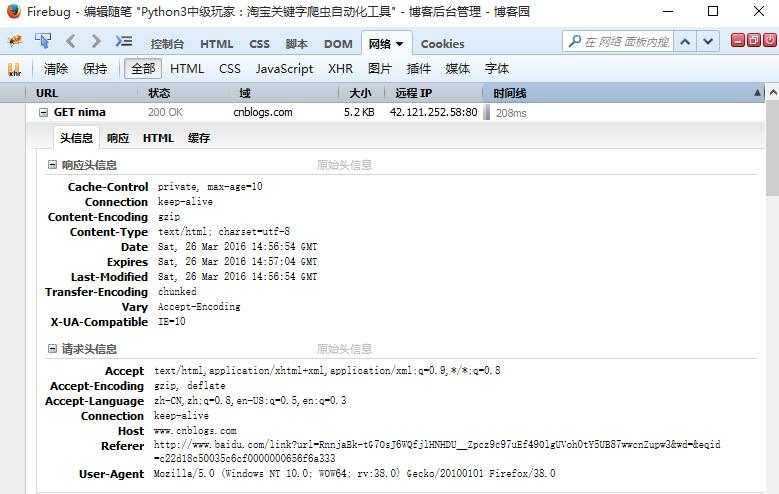
正在翻译:http://www.kancloud.cn/yizhinima/httpcore/117444
我们只需正常进行http请求即可获得数据,问题是淘宝会反爬虫,或者是需要登录。
1.一般反爬虫会在头部做点手脚,加密一些头部,如防盗链有个Referer,如果不是本服务器则拒绝提供服务。
而Session传送的Cookie一般以jsessionid这种头部存在。。。。
2.可能会根据IP访问次数,如一秒访问100次则认为是机器人,比如豆瓣。
本人抓过豆瓣大部分的书~~~~存在数据库了~~请上github!
解决方法:自然是伪装成人类,暂停,换IP,登录,完美!!
由于本人更喜欢用手机玩淘宝,自然是抓手机淘宝的数据,因为也是HTML原生的,所以抓的数据应该是PC端一样妥妥的!
三、思路
先根据F12调试后,确定链接地址,伪装头部,伪装查询条件,非常情况使用外部Cookie文件,得到JSONP数据,替换成JSON数据,抽取JSON数据,
提取图片链接,更改图片尺寸,抓取大图片,图片压缩,数据选择填入EXCEL,生成EXCEL,KO!
四、代码
因为代码较长,下面先按层次逐步讲解,请保存耐心!
使用Python3.4,下面为文件层次截图,部分未截。
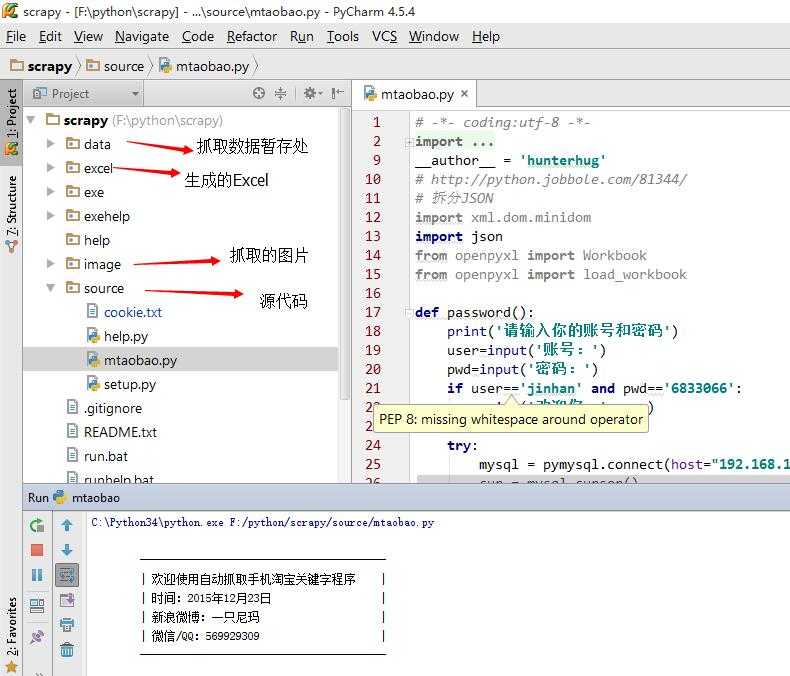
1.导入相应模块
# -*- coding:utf-8 -*- import urllib.request, urllib.parse, http.cookiejar import os, time,re import http.cookies import xlsxwriter as wx # 需安装,EXCEL强大库 from PIL import Image # 需安装,图片压缩截取库 import pymysql # 需安装,mysql数据库操作库 import socket import json
安装模块请使用
pip3 install *
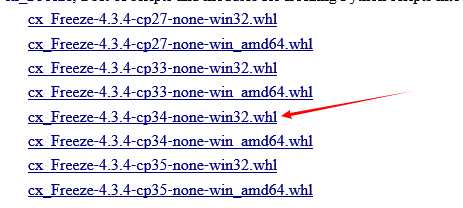
或者从万能仓库 http://www.lfd.uci.edu/~gohlke/pythonlibs/#cx_freeze
下载对应版本:
然后打开cmd,转到该文件目录,使用:
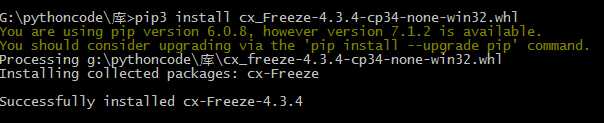
妥妥的,自行安装哈,有问题咨询我!
核心代码如下:
def getHtml(url,daili=‘‘,postdata={}): """ 抓取网页:支持cookie 第一个参数为网址,第二个为POST的数据 """ # COOKIE文件保存路径 filename = ‘cookie.txt‘ # 声明一个MozillaCookieJar对象实例保存在文件中 cj = http.cookiejar.MozillaCookieJar(filename) # cj =http.cookiejar.LWPCookieJar(filename) # 从文件中读取cookie内容到变量 # ignore_discard的意思是即使cookies将被丢弃也将它保存下来 # ignore_expires的意思是如果在该文件中 cookies已经存在,则覆盖原文件写 # 如果存在,则读取主要COOKIE if os.path.exists(filename): cj.load(filename, ignore_discard=True, ignore_expires=True) # 读取其他COOKIE if os.path.exists(‘../subcookie.txt‘): cookie = open(‘../subcookie.txt‘, ‘r‘).read() else: cookie=‘ddd‘ # 建造带有COOKIE处理器的打开专家 proxy_support = urllib.request.ProxyHandler({‘http‘:‘http://‘+daili}) # 开启代理支持 if daili: print(‘代理:‘+daili+‘启动‘) opener = urllib.request.build_opener(proxy_support, urllib.request.HTTPCookieProcessor(cj), urllib.request.HTTPHandler) else: opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) # 打开专家加头部 opener.addheaders = [(‘User-Agent‘, ‘Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5‘), (‘Referer‘, ‘http://s.m.taobao.com‘), (‘Host‘, ‘h5.m.taobao.com‘), (‘Cookie‘,cookie)] # 分配专家 urllib.request.install_opener(opener) # 有数据需要POST if postdata: # 数据URL编码 postdata = urllib.parse.urlencode(postdata) # 抓取网页 html_bytes = urllib.request.urlopen(url, postdata.encode()).read() else: html_bytes = urllib.request.urlopen(url).read() # 保存COOKIE到文件中 cj.save(ignore_discard=True, ignore_expires=True) return html_bytes
这是万能的抓取代码,要代理有代理,要Post数据有数据,还有Cookie保存机制,外部cookie引用。
头部伪装成手机端,妥妥的!!
下面拆分讲解:
filename = ‘cookie.txt‘ # 声明一个MozillaCookieJar对象实例保存在文件中 cj = http.cookiejar.MozillaCookieJar(filename)
上述语句表明,访问网站后cookie保存在cookie.txt中,程序运行后如图

由于每次生成cookie.txt后需要重新使用
# 从文件中读取cookie内容到变量 # ignore_discard的意思是即使cookies将被丢弃也将它保存下来 # ignore_expires的意思是如果在该文件中 cookies已经存在,则覆盖原文件写 # 如果存在,则读取主要COOKIE if os.path.exists(filename): cj.load(filename, ignore_discard=True, ignore_expires=True)
所以如果存在cookie.txt就加载进去,作为头部。
然而并没有什么卵用,淘宝会加密,Cookie没那么简单。生成的Cookie不够用!
因为有时淘宝需要登录,登陆产生的密码好变态,所以不管,用简单粗暴的方法。
登陆:http://s.m.taobao.com/h5entry

登陆后在浏览器上按F12,点击网络,然后在地址栏输入:
如下图,复制Cookie。

将复制的Cookie粘贴到subcookie.txt文件中,最后一行这一部分去掉。

因为JSESSIONID已经自动生成了,需要上面的其他头部。下面是subcookie.txt内容,好丑!
thw=cn; isg=A7A89D9621A9A068A783550E83F9EA75; l=ApqaMO0Erj-EZWH3j8agZ1OFylq8yx6l; cna=Hu3jDrynL3MCATsp1roB7XpN ; t=55aa84049f7d4d13fd9d35f615eca657; uc3=nk2=odrVGF%2FSsTE%3D&id2=UonciKb8CbgV7g%3D%3D&vt3=F8dAScLyUuy4Y2y %2BLsc%3D&lg2=W5iHLLyFOGW7aA%3D%3D; hng=CN%7Czh-cn%7CCNY; tracknick=%5Cu843D%5Cu7FCE%5Cu4E4B%5Cu5C18 ; _cc_=VT5L2FSpdA%3D%3D; tg=0; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato %3D0; ali_ab=59.41.214.186.1448953885940.9; miid=7373684866201455773; lzstat_uv=5949133953778742363|2144678 @2981197; lgc=%5Cu843D%5Cu7FCE%5Cu4E4B%5Cu5C18; _m_h5_tk=1e74de0ae376f631a8496c95c76f5992_1450410384099 ; _m_h5_tk_enc=dd07257232a80053507709abdb5c25ba; WAPFDFDTGFG=%2B4dRjM5djSecKyo4JwyfmJ2Wk7iKyBzheenYyV7Q4jpJ5AGWi %2BQ%3D; ockeqeudmj=jJryFc8%3D; _w_tb_nick=%E8%90%BD%E7%BF%8E%E4%B9%8B%E5%B0%98; imewweoriw=3%2Fsult5sjvHeH4Vx %2FRjBTLvgKiaerF3AknLfbEF%2Fk%2BQ%3D; munb=1871095946; _w_app_lg=18; _w_al_f=1; v=0; cookie2=1c990a2699863063b5429a793eb3a06d ; uc1=cookie14=UoWyjiifHcHNvg%3D%3D&cookie21=URm48syIYB3rzvI4Dim4&cookie15=VT5L2FSpMGV7TQ%3D%3D; mt=ci =-1_0; _tb_token_=QPkhOWpqBYou; wud=wud; supportWebp=false; sg=%E5%B0%986c; cookie1=URseavpIenqQgSuh1bZ8BwEFNWDY3M88T0 %2BWawaafIY%3D; ntm=0; unb=1871095946; _l_g_=Ug%3D%3D; _nk_=%5Cu843D%5Cu7FCE%5Cu4E4B%5Cu5C18; cookie17 =UonciKb8CbgV7g%3D%3D
其实有时是不用到subcookie.txt的,有时却需要用到,有效期很长,几个星期!
# 读取其他COOKIE if os.path.exists(‘../subcookie.txt‘): cookie = open(‘../subcookie.txt‘, ‘r‘).read() else: cookie=‘ddd‘
如果存在subcookie.txt,则读进去,否则就写乱七八糟~~~感觉么么哒
# 建造带有COOKIE处理器的打开专家 proxy_support = urllib.request.ProxyHandler({‘http‘:‘http://‘+daili}) # 开启代理支持 if daili: print(‘代理:‘+daili+‘启动‘) opener = urllib.request.build_opener(proxy_support, urllib.request.HTTPCookieProcessor(cj), urllib.request.HTTPHandler) else: opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
构建代理专家,如果存在代理,那么就加入支持,没有就算了,opener是开启人的意思,他就是我!!
# 打开专家加头部 opener.addheaders = [(‘User-Agent‘, ‘Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5‘), (‘Referer‘, ‘http://s.m.taobao.com‘), (‘Host‘, ‘h5.m.taobao.com‘), (‘Cookie‘,cookie)]
开始伪装,看到Cookie头部没有,我们的subcookie派上用场了,而且我们伪装成iPad!
# 分配专家 urllib.request.install_opener(opener)
将我安装到全局请求里面,上面这样做就是全局咯,一旦urlopen,就直接把所有头部发出去了~~~
# 有数据需要POST if postdata: # 数据URL编码 postdata = urllib.parse.urlencode(postdata) # 抓取网页 html_bytes = urllib.request.urlopen(url, postdata.encode()).read() else: html_bytes = urllib.request.urlopen(url).read()
如果有数据要POST,那么先urlencode一下,因为有些规定一些字符不能出现在url里面,所以要转义,把汉字转成%*,如果某天你post数据的时候一直出错,那么你要考虑是否url里面是否有非法字符,请百度base64原理!!!
转义后直接
html_bytes = urllib.request.urlopen(url).read()
打开url链接,然后读取,读的是二进制喔!!
# 保存COOKIE到文件中 cj.save(ignore_discard=True, ignore_expires=True) return html_bytes
最后把生成的cookie保存起来,返回抓取的数据。
这就是我们第一个核心函数代码,后面还有很多个喔!
时间:2016/3/27
明天待续:Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第二篇)
欢迎访问我的毕业设计网站:http://www.lenggirl.com
等不及,请github武装!!!
git clone https://github.com/hunterhug/taobaoscrapy.git
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
标签:
原文地址:http://www.cnblogs.com/nima/p/5324490.html