标签:
张潇月 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
学习目录:
(1)计算机是如何工作的 http://www.cnblogs.com/20135131zxy/p/5224486.html
(2)操作系统是如何工作的 http://www.cnblogs.com/20135131zxy/p/5248343.html
(3)Linux系统启动过程 http://www.cnblogs.com/20135131zxy/p/5272607.html
(4)系统调用的方法 http://www.cnblogs.com/20135131zxy/p/5297795.html
(5)分析system-call中断处理过程 http://www.cnblogs.com/20135131zxy/p/5315514.html
(6)分析Linux内核创建新进程的过程 http://www.cnblogs.com/20135131zxy/p/5340944.html
(7)Linux如何装载和启动一个可执行程序 http://www.cnblogs.com/20135131zxy/p/5371904.html
(8)理解进程调度时机跟踪分析进程调度和进程切换的过程 http://www.cnblogs.com/20135131zxy/p/5390502.html
学习总结:
在Linux内核这几周的学习中,我受益匪浅,了解到了很多之前不曾了解的知识。
关于计算机是如何工作的:
计算机系统由硬件系统和软件系统两大部分组成。冯•诺依曼(Johnvon Neumann)奠定了现代计算机的基本结构,这一结构又称冯•诺依曼结构,其特点是:
1)使用单一的处理部件来完成计算、存储以及通信的工作。
2)存储单元是定长的线性组织。
3)存储空间的单元是直接寻址的。
4)使用低级机器语言,指令通过操作码来完成简单的操作。
5)对计算进行集中的顺序控制。
6)计算机硬件系统由运算器、存储器、控制器、输入设备、输出设备五大部件组成并规定了它们的基本功能。
7)采用二进制形式表示数据和指令。
我认为计算机在运行时,先从内存中取出第一条指令,然后按照指令的要求按,从存储器中取出数据进行指定的运算和逻辑操作等加工,然后再按地址把结果送到内存中去。接下来,再取出第二条指令,在控制器指挥下完成规定操作,就相当于C语言当中的for循环,依此进行下去。直至遇到停止指令。
关于操作系统是如何工作的:
当一个进程在执行一个程序的时候,进来一个中断,CPU首先将当前EIP,ESP压入内核栈,然后把ESP指向内核栈,EIP指向中断处理的入口,其中最关键的就是TSS,因为TSS中保存了用户态下各个寄存器的信息,所以将用户态下的EIP和ESP入栈,就相当于对进程之前的一个状态进行保存,以便于从中断返回后继续执行之前任务,然后kernel调用SAVE_ALL来将其他寄存器信息保存在栈中,接着根据CS EIP指向的中断程序,对中断进行处理。当执行完一个中断后,会通过schedule进行调度,其中最重要的要数switchto,其会调用switch to函数来进行调度。当中断执行完后,若要返回到用户态,就需要回到最初中断开始的地方继续执行先前任务,这就需要restore all将之前保存在内核栈中的值出栈,然后通过iret恢复其计算器的状态,这样我们就又回到了用户态,继续执行之前因中断而暂停的任务。
我认为操作系统工作的核心是进程,而许多操作系统都有自己的核心进程,进程是程序的动态执行。系统最重要的操作就是完成核心进程,而其他的程序都是其核心进程的衍生物,其可以控制衍生进程的进程启动及切换甚至可以终止进程,当核心系统结束,将影响整个操作系统的运行。
关于Linux系统的启动过程:
首先找到main.c中startkernel,不管分析内核的哪一个部分都要调用startkernel.
Trap init中arch/x86,设置了很多中断,而系统调用也是一种中断。Initprocess是Linux系统中的一号进程,当系统中没有进程需要执行的时候就会调度到idle进程,startkernel从内核一开始启动就会一直存在,这便是0号进程,随后0号进程创建了1号进程即init,于是系统便启动起来了。这是内核的启动过程。init_task是进程0使用的进程描述符,也是Linux系统中第一个进程描述符,该进程的描述符在arch/powerpc/kernel/init_task.c中定义,代码片段如下:struct task_struct init_task =INIT_TASK(init_task);init_task描述符使用宏INIT_TASK对init_task的进程描述符进行初始化,宏INIT_TASK在include/linux/init_task.h文件中,init_task是Linux内核中的第一个线程,它贯穿于整个Linux系统的初始化过程中,该进程也是Linux系统中唯一一个没有用kernel_thread()函数创建的进程,在init_task进程执行后期,它会调用kernel_thread()函数创建第一个核心进程kernel_init,同时init_task进程继续对Linux系统初始化。在完成初始化后,init_task会退化为cpu_idle进程,当Core0的就绪队列中没有其它进程时,该进程将会获得CPU运行。新创建的1号进程kernel_init将会逐个启动次CPU,并最终创建用户进程。
关于系统调用的方法:
用户程序------>C库(即API):INT0x80 ----->system_call------->系统调用服务例程-------->内核程序
先说明一下,我们常说的用户API其实就是系统提供的C库。
系统调用是通过软中断指令 INT 0x80 实现的,而这条INT0x80指令就被封装在C库的函数中。
(软中断和我们常说的硬中断不同之处在于,软中断是由指令触发的,而不是由硬件外设引起的。)
INT 0x80这条指令的执行会让系统跳转到一个预设的内核空间地址,它指向系统调用处理程序,即system_call函数。
(注意:!!!系统调用处理程序system_call并不是系统调用服务例程,系统调用服务例程是对一个具体的系统调用的内核实现函数,而系统调用处理程序是在执行系统调用服务例程之前的一个引导过程,是针对INT0x80这条指令,面向所有的系统调用的。简单来讲,执行任何系统调用,都是先通过调用C库中的函数,这个函数里面就会有软中断 INT0x80 语句,然后转到执行系统调用处理程序 system_call ,
system_call再根据具体的系统调用号转到执行具体的系统调用服务例程。)
system_call函数通过系统调用号查找系统调用表sys_call_table!软中断指令INT0x80执行时,系统调用号会被放入 eax寄存器中,system_call函数可以读取eax寄存器获取,然后将其乘以4,生成偏移地址,然后以sys_call_table为基址,基址加上偏移地址,就可以得到具体的系统调用服务例程的地址了!
然后就到了系统调用服务例程了。需要说明的是,系统调用服务例程只会从堆栈里获取参数,所以在system_call执行前,会先将参数存放在寄存器中,system_call执行时会首先将这些寄存器压入堆栈。system_call退出后,用户可以从寄存器中获得(被修改过的)参数。
另外:系统调用通过软中断INT0x80陷入内核,跳转到系统调用处理程序system_call函数,然后执行相应的服务例程。但是由于是代表用户进程,所以这个执行过程并不属于中断上下文,而是进程上下文。因此,系统调用执行过程中,可以访问用户进程的许多信息,可以被其他进程抢占,可以休眠。
当系统调用完成后,把控制权交回到发起调用的用户进程前,内核会有一次调度。如果发现有优先级更高的进程或当前进程的时间片用完,那么会选择优先级更高的进程或重新选择进程执行。
关于system-call中断处理过程:
系统调用是通过软中断指令 INT 0x80 实现的,而这条INT 0x80指令就被封装在C库的函数中。INT 0x80这条指令的执行会让系统跳转到一个预设的内核空间地址,它指向系统调用处理程序,即system_call函数。系统调用处理程序system_call并不是系统调用服务例程,系统调用服务例程是对一个具体的系统调用的内核实现函数,而系统调用处理程序是在执行系统调用服务例程之前的一个引导过程,是针对INT0x80这条指令,面向所有的系统调用的。简单来讲,执行任何系统调用,都是先通过调用C库中的函数,这个函数里面就会有软中断 INT0x80 语句,然后转到执行系统调用处理程序 system_call ,system_call再根据具体的系统调用号转到执行具体的系统调用服务例程。
system_call函数通过系统调用号查找系统调用表sys_call_table!软中断指令INT0x80执行时,系统调用号会被放入 eax寄存器中,system_call函数可以读取eax寄存器获取,然后将其乘以4,生成偏移地址,然后以sys_call_table为基址,基址加上偏移地址,就可以得到具体的系统调用服务例程的地址了!
然后就到了系统调用服务例程了。需要说明的是,系统调用服务例程只会堆栈里获取参数,所以在system_call执行前,会先将参数存放在寄存器中,system_call执行时会首先将这些寄存器压入堆栈。system_call退出后,用户可以从寄存器中获得(被修改过的)参数。
另外:系统调用通过软中断INT0x80陷入内核,跳转到系统调用处理程序system_call函数,然后执行相应的服务例程。但是由于是代表用户进程,所以这个执行过程并不属于中断上下文,而是进程上下文。因此,系统调用执行过程中,可以访问用户进程的许多信息,可以被其他进程抢占,可以休眠。
当系统调用完成后,把控制权交回到发起调用的用户进程前,内核会有一次调度。如果发现有优先级更高的进程或当前进程的时间片用完,那么会选择优先级更高的进程或重新选择进程执行
关于Linux内核创建一个新进程的过程
在Linux中创建一个新进程的唯一方法是使用fork函数,fork()执行一次但有两个返回值。
在父进程中,返回值是子进程的进程号;在子进程中,返回值为0。因此可通过返回值来判断当前进程是父进程还是子进程。
在fork的最后是将任务设置成了就绪状态,由于fork()是一个系统调用,在系统调用部分system_call.s,可以看到在系统函数返回后,会调用调度函数schedule(),在schedule()中,就会检测到新进程的就绪状态,并用switch_to()切换到新进程进行执行。
使用fork函数得到的子进程是父进程的一个复制品,它从父进程处复制了整个进程的地址空间,包括进程上下文,进程堆栈,内存信息,打开的文件描述符,信号控制设定,进程优先级,进程组号,当前工作目录,根目录,资源限制,控制终端等。而子进程所独有的只是它的进程号,资源使用和计时器等。可以看出,使用fork函数的代价是很大的,它复制了父进程中的代码段,数据段和堆栈段里的大部分内容,使得fork函数的执行速度并不快。由fork() 系统调用创建的新进程被称为子进程。该函数被调用一次,但返回两次。如果fork()进程调用成功,两次返回的区别是子进程的返回值是0,而父进程的返回值则是新子进程的进程号
关于Linux如何装载和启动一个可执行程序
在linux首先创建父进程,然后通过调用fork()系统调用创建一个新的进程,然后新的进程调用execve()系统调用执行指定的ELF文件。主进程继续返回等待新进程执行结束,然后重新等待用户输入命令。execve()系统调用被定义在unistd.h,它的原型如下:
intexecve(const char *filenarne, char *const argv[], char *constenvp[]);
它的三个参数分别是被执行的程序文件名、执行参数和环境变最。Glibc对execvp()系统调用进行了包装,提供了execl(),execlp(), execle(),execv()和execvp()等5个不同形式的exec系列API,它们只是在调用的参数形式上有所区别,但最终都会调用到execve()这个系统中。
调用execve()系统调用之后,再调用内核的入口sys_execve()。sys_execve()进行一些参数的检查复制之后,调用do_execve()。因为可执行文件不止ELF一种,还有java程序和以“#!”开始的脚本程序等,所以do_execve()会首先检查被执行文件,读取前128个字节,特别是开头4个字节的魔数,用以判断可执行文件的格式。如果是解释型语言的脚本,前两个字节“#!"就构成了魔数,系统一旦判断到这两个字节,就对后面的字符串进行解析,以确定程序解释器的路径。环境下,可执行文件是以ELF格式存在的,文件头部标明了文件在加载到内存中需要的相关信息,随后的部分是以段的形式存在的代码和数据,段的划分主要依据加载到内存中的读写属性。系统调用execve负责可执行文件的调度工作,先进行相关参数的传递和调用前环境的处理,然后加载可执行文件的信息,查找相应的可执行文件解析模块,对于ELF格式的可执行文件,按照格式要求加载到内存中相应的地址空间,如果是静态链接的就将文件头部标明的入口地址作为开始;如果是依赖动态链接库的可执行文件则需要将动态链接器ld的入口地址作为开始。execve是一个特殊的系统调用,在子进程总fork返回到一个特定的点,当前程序执行到execve时陷入到内核态,当execve返回时返回的是一个新的可执行程序的执行起点,shell环境执行execve,当系统调用陷入内核中时,调用evecve,doexecve,根据可执行文件加载头部,在链表当中寻找能够解析的内核模块
关于理解进程调度时机跟踪分析进程调度和进程切换的过程
系统中有一个正在当前系统在运行,其中有一个用户态进程X,X需要切换到用户态Y,从正在运行的X切换到Y
最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
1.正在运行的用户态进程X
2.发生中断——savecs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entryof a specific ISR) and ss:esp(point to kernelstack).(使其有机会陷入内核态,将cpu进程压到内核堆栈中)
3.SAVE_ALL //保存现场
4.中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换(在中断处理过程中有中断处理时机)
5.标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
6.restore_all //恢复现场
7.iret - pop cs:eip/ss:esp/eflags fromkernel stack
8.继续运行用户态进程Y
中断和中断返回有个cpu上下文切换,进程调度有一个进程上下文切换
的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
几种特殊情况
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
加载一个新的可执行程序后返回到用户态的情况,如execve;
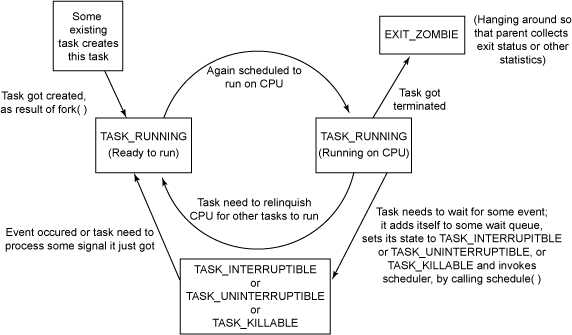
关于各个进程状态的切换关系
标签:
原文地址:http://www.cnblogs.com/20135131zxy/p/5438229.html