标签:
首先抛出一个问题:在example_mnist这个例子中,测试集是人家给好了的。那么如果我们想自己试着手写几个数字然后验证识别效果又当如何呢?
观察CAFFE_ROOT/examples/mnist/下的lenet_train_test.prototxt文件,发现里面既给出了训练集的路径,又给出了测试集的路径。因此答案很显然了,我们可以把自己的测试集做成leveldb(或lmdb)格式的,然后在lenet_train_test.prototxt中给出它的路径,然后按照上一次博客说的那样做即可。
如何将自己的训练集和测试集(比方说一些写着我们自己写的数字的图像)做成leveldb格式?
之所以需要转格式,是因为我之后有一个想做的小实验《用简单的神经网络来实现二元二次函数的拟合》,如此一来输入的数据就得是leveldb或者lmdb格式,需要把这一点搞清楚才能获取训练集和测试集。这个问题我还没有尝试过,不过网上有很多博客有相关的说明,现在列几个我觉得可以研读一下的:
[1]CSDN博客《caffe神经网络框架的辅助工具(将图片转为leveldb格式)》(该博客里面附有C++源码,但是非常难懂);
[2]知乎问题《caffe下如何把自己的数据转成lmdb或者leveldb-beanfrog的回答》(里面有python代码,但牵扯到更多不熟悉的问题,还要先研究一下caffe怎么在python中用,比如被import的caffe包如何生成?)。
[3]薛开宇《学习笔记3用自己的数据训练和测试“CaffeNet”》(本次博客我就是参考他的内容,他的这个博客是[4]的详细版,写的很好)。
[4]caffe官网《Caffe|ImageNet tutorial》(其开头有这么一段话:This guide is meant to get you ready to train your own model on your own data.)
(1)首先新建一个文件夹叫“批量名称”,然后在里面放上若干图片:
(2)接下来开始菜单→cmd,一路cd索引路径直到目录“批量名称”下:
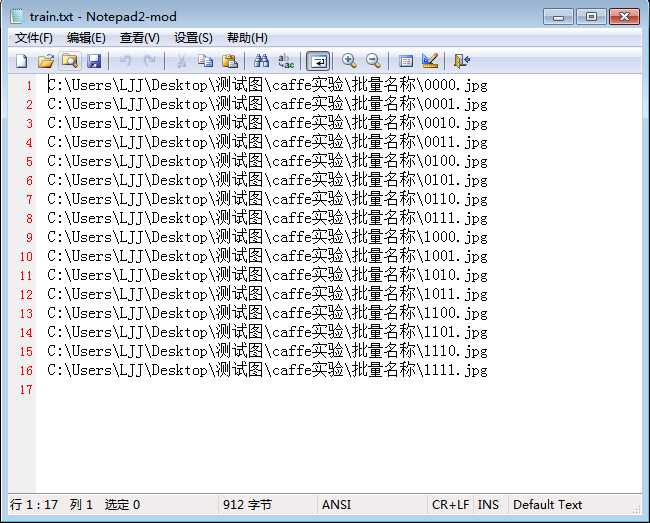
(3)输入命令“dir/s/on/b>d:/train.txt”,则会在D盘生成一个名为train的文本文件,里面存放着“批量名称”中全部图像的路径。
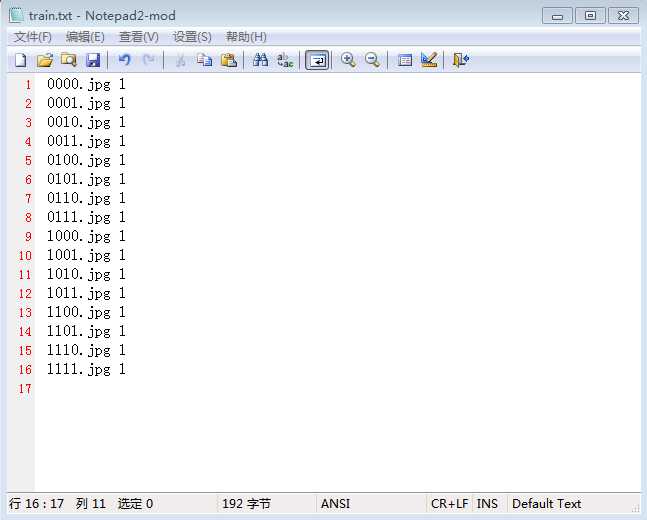
(4)可以使用查找与替换功能,使得上面的内容被修改为“文件名 label”的形式:
①索引“C:\Users\LJJ\Desktop\测试图\caffe实验\批量名称\”替换成空。
相当于把这些路径去掉,只保留文件名;
②索引“jpg”替换成“jpg 1”。这里1是label,指代了图像的类别。
一个小技巧就是先不要把所有的训练数据都混合放,而是分门别类放在各自的文件夹中。比如对于手写数字,我们应该建立10个文件夹,然后把0全部放在一个文件夹“0”,1全部放在一个文件夹“1”……
接下来用刚才(3)中的指令给每个文件夹中的图像都分别建立一个txt文件用于存放图像名,最后建立好后将得到train0.txt~train9.txt十个文件。对每一个txt文件,按照其所属类别,然后查找与替换的时候替换成的内容也是不一样的。比如对于train3.txt,我们就要查找“jpg”替换成“jpg 3”,对于train5.txt,我们就要查找“jpg”替换成“jpg 5”。
当所有的train0.txt~train9.txt全部查找与替换完毕后,再将它们整合到一个txt文档中命名为train.txt即可。
官网和薛开宇的笔记都给出了一段代码,说可以通过把它做成sh文件并运行就可以将图像转成256*256的,但是我试了好久都没成功。
为了达到目的,我决定曲线救国,用opencv里提供的cvResize函数来完成这一项。之所以选择opencv是因为之前我的毕业设计用的是opencv所以比较熟悉,看网上更多人用的是matlab,有机会也可以一试。
由于这里详细写起来也是一篇博客的篇幅,所以我另外开了一个博客专门讲这个问题,请移步《OpenCV玩耍(一)批量resize一个文件夹里的所有图像》。
在CAFFE_ROOT目录下有一个文件夹叫tools,里面有一个cpp文件叫convert_imageset.cpp,利用这个cpp文件生成一个exe文件convert_imageset.exe。具体的做法请移步《CAFFE学习笔记(三)在VS2013下生成需要的exe文件》。
在data目录下创建一个文件夹叫myself,这里把杂七杂八跟本次活动有关的文件全部放进来,有:训练集train(一个放了所有训练图片的文件夹),测试集val(一个放了所有测试图片的文件夹),train.txt,val.txt,test.txt。其中后两者的文件名完全相同,只不过val.txt带标签,而test.txt不带标签。
将CAFFE_ROOT\examples\imagenet下一个叫create_imagenet.sh的文件拷贝到myself下,然后对里面的路径进行设定。
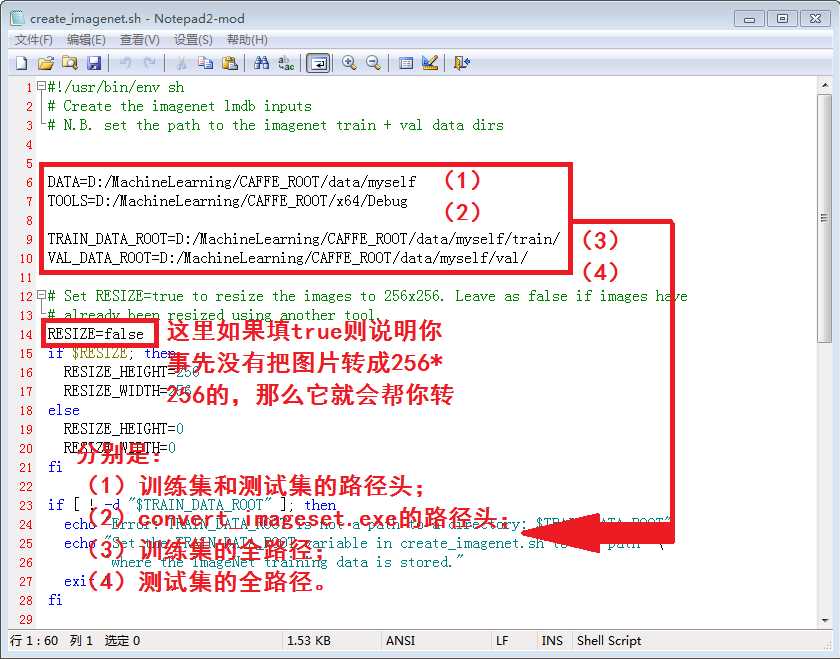
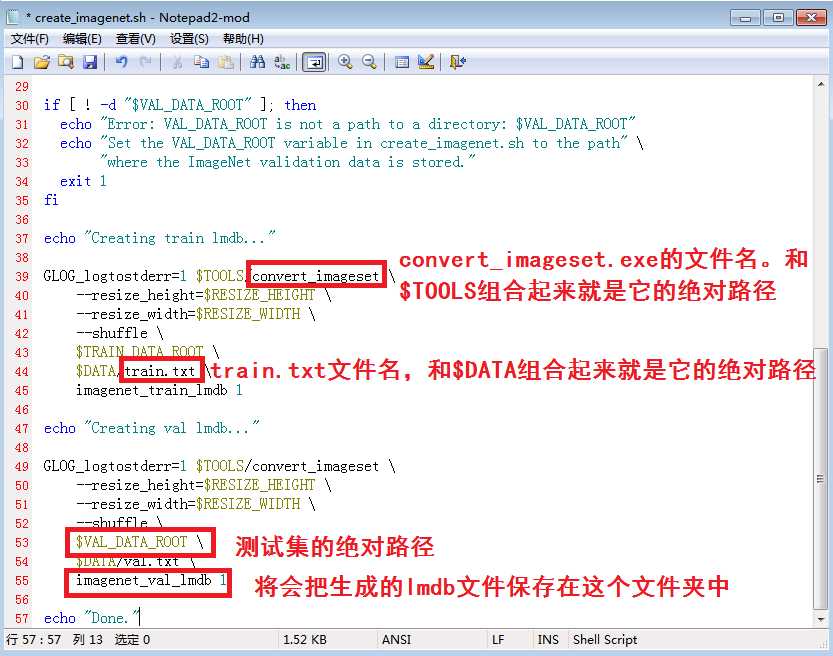
这里用到的思想跟之前在《OpenCV玩耍(一)批量resize一个文件夹里的所有图像》中说过的一样,都是字符串拼接。其中DATA、TOOLS皆为路径头,得和后面的文件名组合起来才是完全路径。说白了,就是在GLOG下分别给训练集和测试集填写三个绝对路径+一个将要生成的文件夹名,这三个绝对路径分别为:
(1)convert_imageset.exe的绝对路径;
(2)train.txt/val.txt的绝对路径;
(3)存放着图片的训练集train文件夹/测试集val文件夹的绝对路径。
而上面关于resize的那段代码实际上可以去掉不要了,因为事先我们已经resize过图像了。一个简化版的create_imagenet.sh可按如下来写,其跑出的效果是一模一样的:
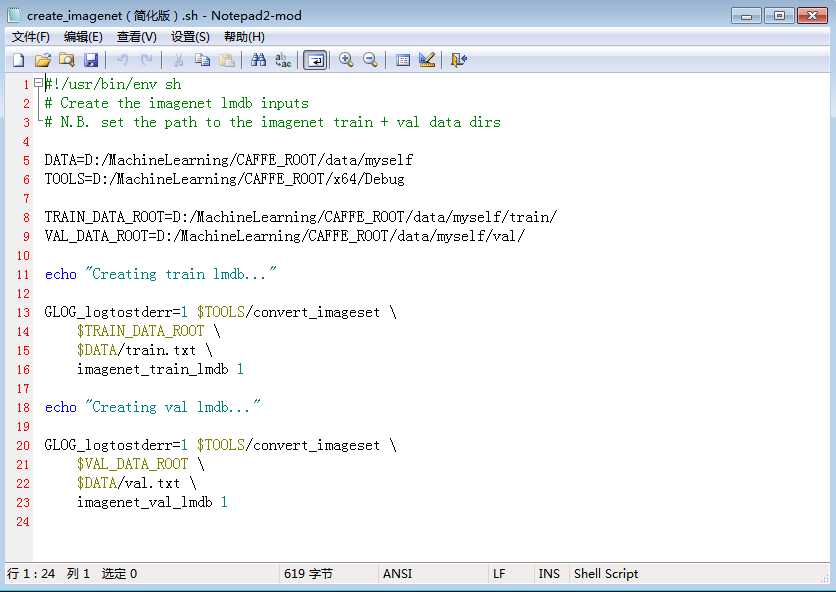
完成路径设定之后,双击该sh文件,即可在myself文件夹下生成imagenet_train_lmdb与 imagenet_val_lmdb文件夹。
在生成lmdb文件的时候,其日志如下:
Creating train lmdb... *** Check failure stack trace: *** I0512 16:23:45.290897 1184 convert_imageset.cpp:83] Shuffling data I0512 16:23:45.290897 1184 common.cpp:32] System entropy source not available, using fallback algorithm to generate seed instead. I0512 16:23:45.290897 1184 convert_imageset.cpp:86] A total of 12 images. F0512 16:23:45.306498 1184 db_lmdb.hpp:14] Check failed: mdb_status == 0 (112 vs. 0) Creating val lmdb... *** Check failure stack trace: *** I0512 16:23:45.509299 3544 convert_imageset.cpp:83] Shuffling data I0512 16:23:45.509299 3544 common.cpp:32] System entropy source not available, using fallback algorithm to generate seed instead. I0512 16:23:45.509299 3544 convert_imageset.cpp:86] A total of 4 images. F0512 16:23:45.509299 3544 db_lmdb.hpp:14] Check failed: mdb_status == 0 (112 vs. 0) Done.
说是有“check failed”,那么这种检查失败是否会对生成的lmdb文件有影响?这种错误的出现是否跟之前配置时我把“在db.cpp中作如下修改...CHECK_EQ”这一步都去掉了有关?又如何能消除这个错误呢?
尝试用这种方法生成了一批手写数字(含标签)的lmdb文件,然后用caffe第二次博客中说的方法拿训练好的网络lenet_iter_10000.caffemodel对该lmdb文件进行测试,一看结果就是失败的,其日志如下:
(前面的日志一切正常,我从打开lmdb开始截) I0512 17:13:10.089304 188 db_lmdb.cpp:38] Opened lmdb D:/MachineLearning/CAFFE_ROOT/data/myself/imagenet_train_lmdb I0512 17:13:10.089304 188 data_reader.cpp:114] Restarting data prefetching from start. F0512 17:13:10.089304 2492 data_transformer.cpp:465] Check failed: datum_channels > 0 (0 vs. 0) I0512 17:13:10.089304 188 data_reader.cpp:114] Restarting data prefetching from start. I0512 17:13:10.089304 188 data_reader.cpp:114] Restarting data prefetching from start.
重点是不知道测试数据是怎么做的,带标签还是不带标签?val.txt与test.txt分别用在何处?为什么在生成lmdb文件时只使用了val.txt而没有用到test.txt?那test.txt又该用到什么地方呢?这些问题先悬挂在这里,我准备老老实实跟着薛开宇的第三次笔记做一遍再说。
本次试验生成的是lmdb文件,但是就leveldb文件如何生成,在配置文件create_imagenet.sh中并没有相应的选项。那答案是否能在convert_imageset.cpp中找到呢?
希望在后续学习中能解决以上这三个问题。
2016.5.12
by 悠望南山
标签:
原文地址:http://www.cnblogs.com/NanShan2016/p/5487194.html