标签:
1、集合的特性:
特性:无序,不重复的序列
如果定义的时候有重复的,就会自动的去重
1 se = {‘123‘,‘234‘} 2 se=set()
#转换: li=[1,2,3] s1=set(li) 转换一个列表为集合 #原理就是调用了set __init__构造方法,就是做了一个for循环。
操作:
1 set.add() #添加,只能一个元素一个元素的添加,不能同时添加多个元素 2 3 set.clear() #清除 4 5 set.copy() #浅拷贝 6 7 set.difference() #差集 8 #例子: 9 s1,difference(s2) #找出s1中存在的s2中不存在的元素 10 11 set.symmetric_difference() #把两个集合的相互不存在的元素找出来,对称差集 12 13 s1 = {1,2,3} 14 s2 = {2,3,4} 15 s1.difference_update(s2) 16 print(s1) 17 {1} # 把s1存在s2不存在的找出来并且更新覆盖到s1 18 19 s1.symmetrice.difference_update(s2) #把互相不存在的更新到s1中。 20 print(s1) 21 {1,4} 22 23 s1.discrd(3) #移除s1中的3,如果没有3则不报错 24 25 s1.remove(3) #移除s1中的3,如果没有则报错 26 27 s1.pop() #随机删除一个参数并获取它,没有参数 28 29 s1.intersection(s2) # 找s1 s2的交集 30 31 s1.intersection.update(s2) #找s1 s2的交集并赋给s1 32 33 s1.isdisjoint(s2) # 判断s1,s2是否不向交 34 35 s2.issubest(s1) #s1,s2是否有交集 36 37 s3=s2.union(s1) #s3为s1和s2的并集 38 39 s1.update() #向s1中批量添加一组可迭代的对象 40 #例子 list dict tuple 可以,现在以dict为例 41 s3={‘k1‘:‘v1‘,‘k2‘:‘v2‘} 42 #想要添加s3的key 43 s2.update(s3) 44 #也可以添加s3的values 45 s2.update(s3.values())
练习题:
old_dict = { "#1": 8, "#2":4, "#4":2, } new_dict = { "#1":4, "#2":4, "#3":2, } #old_dict是服务器原内存插槽位置及内存容量, #new_dict是服务器新内存插槽位置及内存容量。 #应该删除那几个槽位, #应该更新那几个槽位 #应该增加那几个槽位
函数分为自定义函数,和内置函数:
使用步骤:
声明函数,使用函数
声明函数:
def f1() return True
def:关键字
f1():函数名
return:返回值
使用函数:
f1()
以发邮件函数为例:
1 def sendmail(): #声明函数 sendmail为函数名 2 import smtplib 3 from email.mime.text import MIMEText 4 from email.utils import formataddr 5 6 msg = MIMEText(‘邮件内容‘, ‘plain‘, ‘utf-8‘) 7 msg[‘From‘] = formataddr(["alex", ‘alex@126.com‘]) 8 msg[‘To‘] = formataddr(["走人", ‘alex@qq.com‘]) 9 msg[‘Subject‘] = "主题" 10 11 server = smtplib.SMTP("smtp.126.com", 25) 12 server.login("alex@126.com", "密码") 13 server.sendmail(‘alex@126.com‘, [‘alex@qq.com‘, ], msg.as_string()) 14 server.quit() 15 16 sendmail() #使用函数
return:
**在函数中一旦执行return,函数立即终止
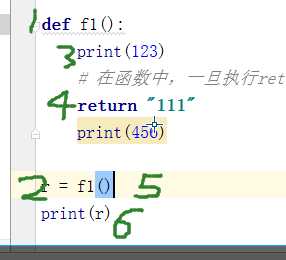
函数参数分为:形式参数和实际参数
def send(arg1,arg2) #arg1,arg2是 形式参数,目的是占位。 print(arg1,arg2) #函数内的形式参数也是占位,但是名字要和 #声明函数中的形式参数一一对应 #可以按照位置传输实际参数 send(‘alex‘,‘nb‘) #也可以指定传输实际参数 send(arg2="nb",arg1="alex")
形式参数也可以设置成默认参数
def send(arg1,arg2=‘alex‘) #arg1的默认参数位alex,默认参数,一定要放到所有形参的最右边,否则会报错。 print(arg2,arg1)
#使用函数并传递参数时如果不传递参数则使用默认参数
send(‘nb‘)
alex nb
#也可以传递删除
send(‘nb‘,‘wo‘)
wo nb
如果想一下传入多个参数
def f1(*arg) print(arg) for i in arg: print(i) l=[1,2,3] f1(l) #这样传输l就被当成一个元素穿进去,那么这样的结果是: ([1,2,3],) #这样传入的元素被当成了一个元组 [1,2,3] #循环后就得出了这个元组内的元素。
如果想把l这个列表打散,也可以,这颗 * 很神奇!
def f1(*arg) print(arg) l=[1,2,3] f1(*l) #这样传输l就被当成一个元素穿进去,那么这样的结果是: (1,2,3,) #这样传入列表中的元素就被遍历后再一个一个的传入到f1中
这就叫神奇了吗?不还有更神奇的,**
元组,列表,字符串都都可以传了,还有一个千万别忘了,对就是字典:
def f1(args): print(args) d={‘a‘:1,‘b‘:2} f1(d) {‘b‘: 2, ‘a‘: 1}
按照上面的方法我们要这么传递字典
如果我要直接定义key value呢:
def f1(**args): print(args) f1(a=1,b=2) {‘b‘: 2, ‘a‘: 1}
通过例子看出来**args只接收键值对形式的参数。
第三种就是这样
def f1(**args): print(args) d1={‘a‘:1,‘b‘:2} f1(**d1)
{‘a‘: 1, ‘b‘: 2}
如果调用函数的时候不加上** 就会报错,因为形式参数的**args,需要接收的参数为字典。
传递实际参数的时如果不加**就会认为d1是一个整体,**args不会接受,但是实际参数也加一个**d1,则传参的时候args就会遍历d1里面
的每个key-values,赋值给args。
万能参数:
def f1(*args,**kwargs) print(args) print(kwargs) #这样往这个函数里面传参就不用考虑实际参数类型了。
格式化方法:
str.format
def format(self, *args, **kwargs): # known special case of str.format """ S.format(*args, **kwargs) -> str
s = "i am {0},i am {1}" .format(‘jack‘,18) i am jack,age18 #jack 和 18 都别识别为 给*args传参数。也可以定义一个可遍历的对象如: a=[‘jack‘,11] s = "i am {0},i am {1}" .format(*a) i am jack,age 11 ================================== 还有一个格式: s = "i am {name},i am {age}" .format(name=‘jack‘,age=18) 也可以利用万能参数的特性 a={‘name‘:‘hx‘,‘age‘:19} s="i am {name},age {age}".format(**a) i am hx,age 19
函数就像变量一样,被复制的函数被放到内存里,一旦有新的赋值,原赋值内容就被清空
#有两个同名的函数 def f1(a1,a2): return a1 + a2 def f1(a1,a2): return a1 * a2 ret = f1(8,8) print(ret) 64 #函数默认是从上自下依次执行的。
函数参数的传递,是引用还是值
引用是传递的参数和函数内使用的参数传递id相同
值是当参数传递到函数中再创建一个新的相同的参数给函数使用
def f1(a): a.append(999) li=[111,222,333] f1(li) print(li) [11, 22, 33, 999] #函数中对li进行了添加操作,最后函数外的li被函数给改变了。
#所以python传参数传递的是引用。
私有变量,全局变量
私有变量:
在函数内声明的变量为私有变量,其他函数无法使用此变量
全局变量:
在函数外声明的变量,所以的函数都能调用此变量
命令要求:
全局变量最好全部大写,与常量要求一样。
全局变量所以的地方都能读
需要修改全局变量,需要加上global字段
AGE=22 def f1(): name = ‘hx‘ global AGE AGE = ‘26‘ print(name,AGE) f1() print(AGE) hx 26 26 此时外面的AGE也被修改了
其他的函数如果要调用AGE的时候就是修改后的数值了。 =============================== AGE=22 def f1(): name = ‘hx‘ AGE = ‘26‘ print(name,AGE) f1() print(AGE) hx 26 22 此时外面的AGE没有被修改
上面是重新赋值,下面就要说说修改值了
在函数里面,字典,列表 不用通过global可以对全局变量进行修改。(如: append,pop之类)
NAME=[1,2,3]
DIC = {‘k1‘:11,‘k2‘:22}
def f1():
NAME.append(4)
DIC.clear()
f1()
print(NAME)
print(DIC)
[1,2,3,4]
{}
#但是如果想重新赋值就需要加上global了
def f1():
global NAME,DIC
NAME = [2,3,4]
DIC = {‘k1‘: 13, ‘k2‘:14}
f1()
print(NAME)
print(DIC)
[2, 3, 4]
{‘k1‘: 13, ‘k2‘: 14}
定义全局变量全部都是【大写】
是什么鬼?二郎神军?
嘻嘻,三目运算又称之为三元运算,(我擦,又变成牛奶了)
其实它就是简单的if else的表达形式
比如:
if 1==1: name=‘abarma‘ else: name=‘putin‘
使用三目运算的表达方式就非常简单:
name =‘abarma‘ if 1 == 1 else ‘putin‘
lambda其实就是一个简单的函数的表达式
def f1(a): return a+100
使用lambda表达:
f1 = lambda a :a + 100
f1:函数名
a:xingcan
a+100:函数的return
#形参在lambda里也可以设置默认值:
f1 = lambda a b=20 : a + b + 100
abs() #取绝对值
all() #接受一个可迭代对象,所有元素如果都为真返回为真,则为假。
any() #接受一个可迭代对象,所有的元素如果有一个为真就为真。
ascii() #自动执行对象的__repr___方法:
class Foo:
def __repr__(self):
return "111"
n = ascii(Foo())
print(n)
111
bin() #接受10进制转为2进制 ob开头
oct() #接收10进制转为8进制 0o开头
hex() #接受10进制转16进制 0x开头
bytes() #把一个汉字转换成字节
对于utf-8 来讲一个汉字三个字节 一个字节8位,
s="哈哈"
n = bytes(s,encoding="utf-8")
print(n)
b‘\xe5\x93\x88\xe5\x93\x88‘
对于gbk,一个汉字2个字节
s="哈哈"
n = bytes(s,encoding="gbk")
print(n)
b‘\xb9\xfe\xb9\xfe‘
#上面的表现形式就是把汉字转换成字节的类型
字节转化成 字符串
使用str就可以转换
new_list = str(bytes(s,encoding="utf-8"),encoding="utf-8")
#这样就给转化你回来了。
a=bytes("哈哈",encoding="utf-8")
print(a)
b‘\xe5\x93\x88\xe5\x93\x88‘
b=str(a,encoding="utf-8")
print(b)
哈哈
b=str(b‘\xe5\x93\x88\xe5\x93\x88‘,encoding="utf-8")
或者这样也可以把字节给转换回字符串
print(b)
哈哈
对于文件操作就是3步:打开文件 、 操作文件 、 关闭文件
open() 打开文件
r: 只读 w: 只写,清空源文件 x: 如果这个文件存在就报错,如果不存在则创建并写。 (python3中新加) a: 追加 rb: 以二进制的形式读取 wb: 以二进制的形式读取 ab: 以二进制的形式追加
r+: 读写
w+: 写读
x+: 写读
a+: 写读
b: 有b就是字节类型,没有b就是字符串类型
f = open(‘x‘,‘rb‘) #用rb 的意思就是存或者读文件的时候我告诉python解释器,你不用帮我转换了。我直接转换成字节以2进制的方式存取。 f.read()
#如果一开始不是以rb存储的,比如是用utf-8存储的,但是你却用rb去读取。哪肯定读不出来了。
如果你之前用的utf-8写的文件,再次写非要想用个b,可以实现。
f.open(‘a‘,‘rb‘)
f.write(bytes(‘hello‘,encoding=‘utf-8‘)) 这样的话就是告诉解释器:我来写,我使用bytes,把hello使用utf-8来保存。
(我用bytes把‘hello’以utf-8的形式转换成二进制)
f.close()
如果你要以r存,然后非要以b读的话怎么办?
with open(‘aaa‘,‘rb‘) as file1:
a=file1.readline()
print(a)
b‘\xe5\x93\x88\xe5\x93\x88‘
因为a就已经是被utf-8转换的字节了所以可以世界用str转换回来
b=str(a,encoding="utf-8")
print(b)
哈哈
r+ w+ a+ x+ 功能对比:
r+
要先读再写,才能内次写进去。
指针在读前是在最开始位置,一点读了以后指针就跑到了最后的位置,之后我们再写就可以把内容追加进去了。
如果用r+模式先写在读就会发生指针错乱:
本来指针在最开始,等待让我们读,但是我们却写了数据进去,然后指针就到了我们写进数据的后面,此时我们又开始读了,所以我们只能读取到指针后面的东西了。
没有 b read()的时候按照字符读取,有 b read() 按照字节读取
r+ 在读写文件时最灵活,可以所以的用seek()调整位置,然后写文件。
==========================================================
a+:
虽然可以读写了,但是不管你读到那里,再写的话永远写到文件的最后面
==========================================================
w+:
虽然可以读写,它会先清空,再写,最后写进去的东西可以读出来了
==========================================================
f.seek() #主动的把指针调整到某一个位置
使用f.seek()调整位置后,然后再往里面写东西,新写的文字会覆盖原来的文字。
如果read()无参数则打开全部文件
f.read(1)
是否+b的区别
在使用 r 读取时没有b 位置单位是一个字符
但是我们用 r+b 来读取的时候 位置单位就是一个字节
但是seek不管用什么方式打开,都是以字节的方式来找位置。
f.tell() #获取当前指针的位置
readline() #以字符串的形式仅读取一行
readlines() #把全部文件都读取出来放到一个列表中去。
truncate() #清空指针后面的字符
seek() #指针跳转到指定位置,按照字节来跳转
write() #写数据,如果打开方式有b 只能写字节,无b写字符
fileno() #文件描述符,查看底层文件有没有变化时用这个
flush() #强刷文件
readable() #判断是否可读, 如果以w方式打开,就是不可读 False
seekable() #是否可以移动指针
最常用:
f = open(‘ab‘,‘r‘)
for line in f
print(line)
或者
while True
x=f.readline()
if x:
print(x)
else:
break
关闭文件:
f.close() #关闭文件 with open(‘xb‘,r,encoding="utf-8") as f: pass #with这个功能,在对文件操作完了就自动关闭了。
源代码定义:
def open(file, mode=‘r‘, buffering=None, encoding=None, errors=None, newline=None, closefd=True)
2.7以后支持with 同时打开多个文件
with open(‘xb‘,‘r‘,encoding="utf-8") as f,open(‘xb2‘,‘w‘,encoding="utf-8") as f2
一个读一个就可以把读出来的写到f2里面。
标签:
原文地址:http://www.cnblogs.com/python-way/p/5521071.html