标签:
师兄推荐我学习Lucene这门技术,用了两天时间,大概整理了一下相关知识点。
一、什么是Lucene
Lucene即全文检索。全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程。
二、Lucece全文检索和数据库检索的区别
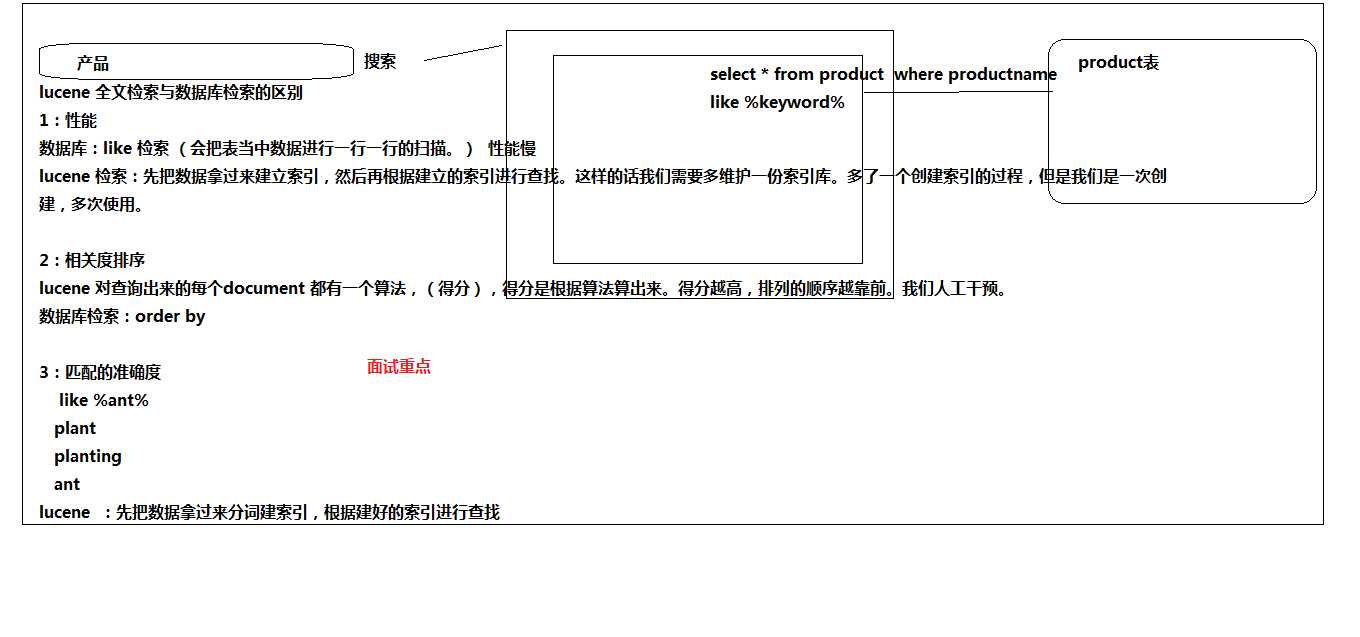
三、Lucene的原理
(1)索引库操作原理
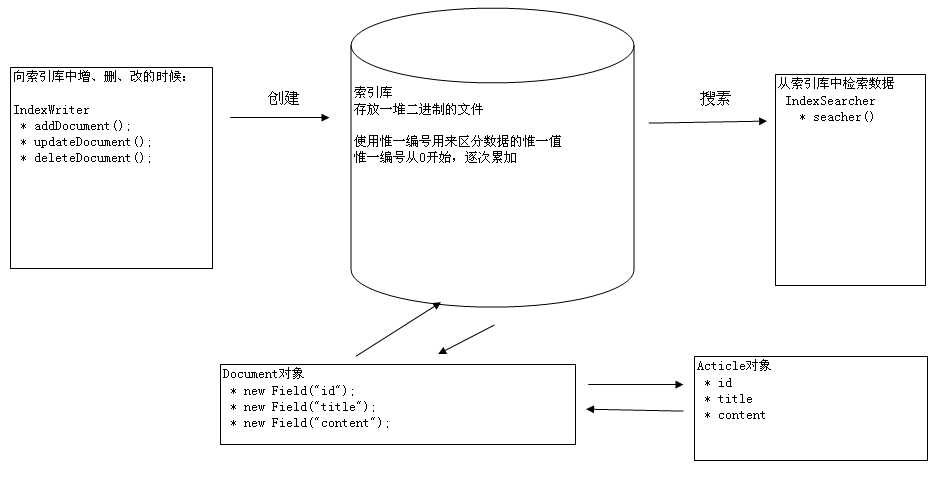
注意:这里面有两个关键的对象:分别是IndexWriter和IndexSearcher。
执行增删改操作用的是IndexWriter对象,执行查询操作用的是IndexSearcher对象。
(2)索引库存放数据原理

注意:Lucece库在4.0之前和4.0之后的API发生了很大变化,这个图中的Index到后面的API已经不建议再用了。后面有相应的替代方法。
比如:原来的写法:
String id = NumericUtils.intToPrefixCoded(1);
new Field("id",id,Store.YES,Index.NOT_ANALYZED);
new Field("title", "我是陈驰",Store.YES, Index.NOT_ANALYZED);
new Field(""content",
"国防科学技术大学(National University of Defense Technology),是中华人民共和国中央军事委员会直属的一所涵盖理学、工学、军事学、管理学、经济学、哲学、文学、教育学、法学、历史学等十大学科门类的综合性全国重点大学",
Store.YES,
Index.ANALYZED);
后来的写法:
new IntField("id", 1, Store.YES);
new StringField("title", "我是陈驰", Store.YES);
new TextField(
"content",
"国防科学技术大学(National University of Defense Technology),是中华人民共和国中央军事委员会直属的一所涵盖理学、工学、军事学、管理学、经济学、哲学、文学、教育学、法学、历史学等十大学科门类的综合性全国重点大学",
Store.YES);

四、Lucene开发原理(索引库与数据库同步)
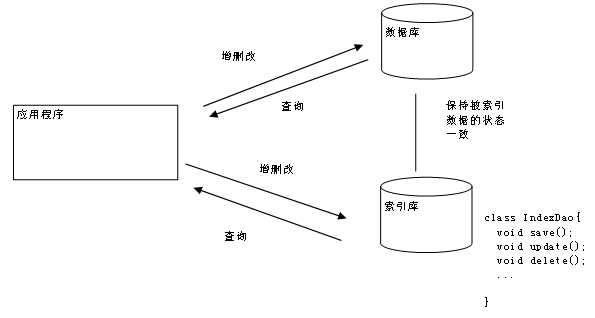
数据库与索引库中存放相同的数据,可以使用数据库中存放的ID用来表示和区分同一条数据。
--数据库中用来存放数据
--索引库中用来查询、检索
检索库支持查询检索多种方式,
特点:
1:由于是索引查询(通过索引查询数据),检索速度快,搜索的结果更加准确
2:生成文本摘要,摘要截取搜索的文字出现最多的地方
3:显示查询的文字高亮
4:分词查询等
注意:添加了索引库,并不意味着不往数据库中存放数据,数据库的所有操作仍和以前一样。只不过现在多维护一个索引库,在查询的时候可以提高效率。
索引库中存放的数据要转换成Document对象(每条数据就是一个Document对象),并向Document对象中存放Field对象(每条数据对应的字段,例如主键ID、所属单位、图纸类别、文件名称、备注等),将每个字段中的值都存放到Field对象中。
五、开发步骤
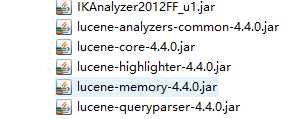
(1)需要的jar包
(2)需要的配置文件(注:这里我用的是IKAnalyzer,是第三方的中文分词器,庖丁分词,中文分词,特点:扩展新的词,自定义停用词。只有用该分词器才用到以下配置文件。)
l IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典--> <entry key="ext_dict">mydict.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">ext_stopword.dic</entry> </properties>
l ext.dic(扩展词库)
l stopword.dic(停用词库)
(3)一个简单的例子(用的标准分词器StandardAnalyzer,所以暂时没有用到上面的配置文件,标准分词器是汉字一个一个分的,英语还是按单词)
import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.IntField; import org.apache.lucene.document.StringField; import org.apache.lucene.document.Field.Index; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.IndexableField; import org.apache.lucene.index.Term; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; import org.junit.Test; /** * 使用lucene对数据创建索引 * * @author chenchi * */ public class TestLucene { /** * 使用IndexWriter对数据创建索引 * @throws IOException */ @Test public void testCreateIndex() throws IOException { // 索引存放的位置... Directory d = FSDirectory.open(new File("indexDir/")); // 索引写入的配置 Version matchVersion = Version.LUCENE_CURRENT;// lucene当前匹配的版本 Analyzer analyzer = new StandardAnalyzer(matchVersion);// 分词器 IndexWriterConfig conf = new IndexWriterConfig(matchVersion, analyzer); // 构建用于操作索引的类 IndexWriter indexWriter = new IndexWriter(d, conf); // 通过IndexWriter来创建索引 // 索引库里面的数据 要遵守一定的结构(索引结构,document) Document doc = new Document(); /** * 1.字段的名称 2.该字段的值 3.字段在数据库中是否存储 * StringField是一体的 * TextField是可分的 */ IndexableField field = new IntField("id", 1, Store.YES); IndexableField title = new StringField("title", "java培训零基础开始 从入门到精通", Store.YES); IndexableField content = new TextField( "content", "java培训,中软国际独创实训模式,三免一终身,学java多项保障让您无后顾之忧。中软国际java培训,全日制教学,真实项目实战,名企定制培训,四个月速成java工程师!", Store.YES); doc.add(field); doc.add(title); doc.add(content); // document里面也有很多字段 indexWriter.addDocument(doc); indexWriter.close(); } /** * 使用IndexSearcher对数据创建索引 * * @throws IOException */ @Test public void testSearcher() throws IOException { // 索引存放的位置... Directory d = FSDirectory.open(new File("indexDir/")); // 通过indexSearcher去检索索引目录 IndexReader indexReader = DirectoryReader.open(d); IndexSearcher indexSearcher = new IndexSearcher(indexReader); // 这是一个搜索条件,根据这个搜索条件我们来进行查找 // term是根据哪个字段进行检索,以及字段对应值 //================================================ //注意:这样是查询不出,只有单字才能查询出来 Query query = new TermQuery(new Term("content", "培训")); // 搜索先搜索索引目录 // 找到符合条件的前100条数据 TopDocs topDocs = indexSearcher.search(query, 100); System.out.println("总记录数:" + topDocs.totalHits); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { //得分采用的是VSM算法 System.out.println("相关度得分:" + scoreDoc.score); //获取查询结果的文档的惟一编号,只有获取惟一编号,才能获取该编号对应的数据 int doc = scoreDoc.doc; //使用编号,获取真正的数据 Document document = indexSearcher.doc(doc); System.out.println(document.get("id")); System.out.println(document.get("title")); System.out.println(document.get("content")); } } }
(4)实现Lucene的CURD操作
先写一个LuceneUtils类:
import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class LuceneUtils { public static Directory d = null; public static IndexWriterConfig conf = null; public static Version matchVersion = null; public static Analyzer analyzer = null; static{ try { d = FSDirectory.open(new File(Constant.FILEURL)); matchVersion = Version.LUCENE_44; //注意:该分词器是单字分词 analyzer = new StandardAnalyzer(matchVersion); conf = new IndexWriterConfig(matchVersion, analyzer); } catch (IOException e) { e.printStackTrace(); } } /** * * @return 返回版本信息 */ public static Version getMatchVersion() { return matchVersion; } /** * * @return 返回分词器 */ public static Analyzer getAnalyzer() { return analyzer; } /** * * @return 返回用于操作索引的对象 * @throws IOException */ public static IndexWriter getIndexWriter() throws IOException{ IndexWriter indexWriter = new IndexWriter(d, conf); return indexWriter; } /** * * @return 返回用于读取索引的对象 * @throws IOException */ public static IndexSearcher getIndexSearcher() throws IOException{ IndexReader r = DirectoryReader.open(d); IndexSearcher indexSearcher = new IndexSearcher(r); return indexSearcher; } }
标签:
原文地址:http://www.cnblogs.com/DarrenChan/p/5860738.html