标签:
这里windows和Linxu系列的PID 管理方式有所不同,windows中进程的PID和句柄没有本质区别,根据句柄索引对象和根据PID或者TID查找进程或者线程的步骤也是一样的。
NTSTATUS PsLookupProcessByProcessId( __in HANDLE ProcessId, __deref_out PEPROCESS *Process ) /*++ Routine Description: This function accepts the process id of a process and returns a referenced pointer to the process. Arguments: ProcessId - Specifies the Process ID of the process. Process - Returns a referenced pointer to the process specified by the process id. Return Value: STATUS_SUCCESS - A process was located based on the contents of the process id. STATUS_INVALID_PARAMETER - The process was not found. --*/ { PHANDLE_TABLE_ENTRY CidEntry; PEPROCESS lProcess; PETHREAD CurrentThread; NTSTATUS Status; PAGED_CODE(); Status = STATUS_INVALID_PARAMETER; CurrentThread = PsGetCurrentThread (); KeEnterCriticalRegionThread (&CurrentThread->Tcb); CidEntry = ExMapHandleToPointer(PspCidTable, ProcessId); if (CidEntry != NULL) { lProcess = (PEPROCESS)CidEntry->Object; if (lProcess->Pcb.Header.Type == ProcessObject && lProcess->GrantedAccess != 0) { if (ObReferenceObjectSafe(lProcess)) { *Process = lProcess; Status = STATUS_SUCCESS; } } ExUnlockHandleTableEntry(PspCidTable, CidEntry); } KeLeaveCriticalRegionThread (&CurrentThread->Tcb); return Status; } //此函数中最关键的一步是根据ExMapHandleToPointer函数获取到了进程PID对应的HANDLE_TABLE_ENTRY结构,进入此函数看下: NTKERNELAPI PHANDLE_TABLE_ENTRY ExMapHandleToPointer ( __in PHANDLE_TABLE HandleTable, __in HANDLE Handle ) /*++ Routine Description: This function maps a handle to a pointer to a handle table entry. If the map operation is successful then the handle table entry is locked when we return. Arguments: HandleTable - Supplies a pointer to a handle table. Handle - Supplies the handle to be mapped to a handle entry. Return Value: If the handle was successfully mapped to a pointer to a handle entry, then the address of the handle table entry is returned as the function value with the entry locked. Otherwise, a value of NULL is returned. --*/ { EXHANDLE LocalHandle; PHANDLE_TABLE_ENTRY HandleTableEntry; PAGED_CODE(); LocalHandle.GenericHandleOverlay = Handle; if ((LocalHandle.Index & (LOWLEVEL_COUNT - 1)) == 0) { return NULL; } // // Translate the input handle to a handle table entry and make // sure it is a valid handle. // HandleTableEntry = ExpLookupHandleTableEntry( HandleTable, LocalHandle ); if ((HandleTableEntry == NULL) || !ExpLockHandleTableEntry( HandleTable, HandleTableEntry)) { // // If we are debugging handle operations then save away the details // if (HandleTable->DebugInfo != NULL) { ExpUpdateDebugInfo(HandleTable, PsGetCurrentThread (), Handle, HANDLE_TRACE_DB_BADREF); } return NULL; } // // Return the locked valid handle table entry // return HandleTableEntry; }
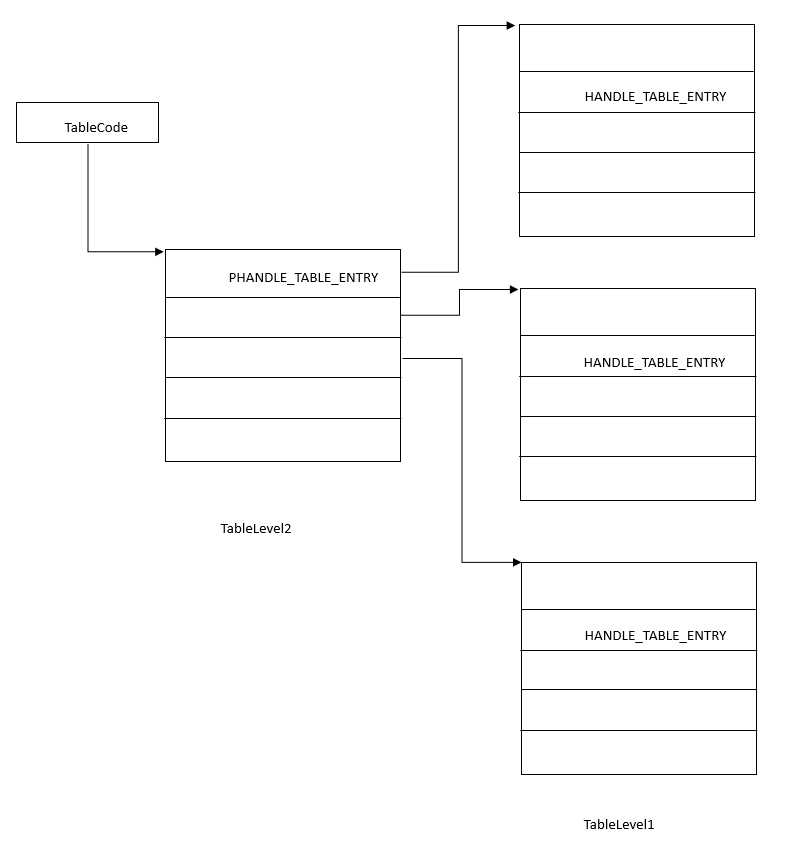
PHANDLE_TABLE_ENTRY ExpLookupHandleTableEntry ( IN PHANDLE_TABLE HandleTable, IN EXHANDLE tHandle ) /*++ Routine Description: This routine looks up and returns the table entry for the specified handle value. Arguments: HandleTable - Supplies the handle table being queried tHandle - Supplies the handle value being queried Return Value: Returns a pointer to the corresponding table entry for the input handle. Or NULL if the handle value is invalid (i.e., too large for the tables current allocation. --*/ { ULONG_PTR i,j,k; ULONG_PTR CapturedTable; ULONG TableLevel; PHANDLE_TABLE_ENTRY Entry = NULL; EXHANDLE Handle; PUCHAR TableLevel1; PUCHAR TableLevel2; PUCHAR TableLevel3; ULONG_PTR MaxHandle; PAGED_CODE(); // // Extract the handle index // Handle = tHandle; Handle.TagBits = 0; MaxHandle = *(volatile ULONG *) &HandleTable->NextHandleNeedingPool;//取下一页的起始索引,在一层句柄表的情况下,这里作为最大索引限制 // // See if this can be a valid handle given the table levels. // if (Handle.Value >= MaxHandle) { return NULL; } // // Now fetch the table address and level bits. We must preserve the // ordering here. // CapturedTable = *(volatile ULONG_PTR *) &HandleTable->TableCode;//获取句柄表的最高层页面的地址。 // // we need to capture the current table. This routine is lock free // so another thread may change the table at HandleTable->TableCode // TableLevel = (ULONG)(CapturedTable & LEVEL_CODE_MASK);//取句柄表级数 CapturedTable = CapturedTable - TableLevel;//这里是为何???? // // The lookup code depends on number of levels we have // switch (TableLevel) { case 0: // // We have a simple index into the array, for a single level // handle table // TableLevel1 = (PUCHAR) CapturedTable; // // The index for this level is already scaled by a factor of 4. Take advantage of this // //注意这里tablelevel1已经不是PHANDLE_TABLE_ENTRY类型而是puchar类型,即相当于一个uchar类型的指针,那么把tablelevel1作为数组地址取值,一个元素就占用一个字节 //因为PID 本身是作为4增长,而一个表项是占用8字节,所以只需要让PID *2即可 Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[Handle.Value * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)]; break; case 1: // // we have a 2 level handle table. We need to get the upper index // and lower index into the array // TableLevel2 = (PUCHAR) CapturedTable; i = Handle.Value % (LOWLEVEL_COUNT * HANDLE_VALUE_INC);//这里取i为实际的PID 在某个句柄表中的偏移 Handle.Value -= i;//然后用值减去这个偏移,得到的应该是整数个句柄表的最后一位PID j = Handle.Value / ((LOWLEVEL_COUNT * HANDLE_VALUE_INC) / sizeof (PHANDLE_TABLE_ENTRY));//用value除以一个句柄表容纳的 TableLevel1 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel2[j];//这里就取二级句柄表的地址 Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[i * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)]; break; case 2: // // We have here a three level handle table. // TableLevel3 = (PUCHAR) CapturedTable; i = Handle.Value % (LOWLEVEL_COUNT * HANDLE_VALUE_INC); Handle.Value -= i; k = Handle.Value / ((LOWLEVEL_COUNT * HANDLE_VALUE_INC) / sizeof (PHANDLE_TABLE_ENTRY)); j = k % (MIDLEVEL_COUNT * sizeof (PHANDLE_TABLE_ENTRY)); k -= j; k /= MIDLEVEL_COUNT; TableLevel2 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel3[k]; TableLevel1 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel2[j]; Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[i * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)]; break; default : _assume (0); } return Entry; }
TableLevel2 = (PUCHAR) CapturedTable; i = Handle.Value % (LOWLEVEL_COUNT * HANDLE_VALUE_INC);//这里取i为实际的PID 在某个句柄表中的偏移 Handle.Value -= i;//然后用值减去这个偏移,得到的应该是整数个句柄表的最后一位PID j = Handle.Value / ((LOWLEVEL_COUNT * HANDLE_VALUE_INC) / sizeof (PHANDLE_TABLE_ENTRY));//用value除以一个句柄表容纳的 TableLevel1 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel2[j];//这里就取二级句柄表的地址 Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[i * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)]; break;
TableLevel1 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel2[j];//这里就取二级句柄表的地址
Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[i * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)];
lProcess = (PEPROCESS)CidEntry->Object;
注意:
这里entry->object是直接取到了对象体,但是在普通的句柄情况下,这里只能取到对象头,最后根据相应的偏移取到对象体,关于对象参考另一篇文章!还有前面红色字体那个地方,笔者的确不晓得什么意思,知道的老师们还请多多指点!
标签:
原文地址:http://www.cnblogs.com/ck1020/p/5889879.html