标签:.com 否则 span 数据采集 images chrome path pytho 技术
本文主要讲解如何在scrapy中使用xpath获取各种你想要的值
使用豆瓣作为例子
https://book.douban.com/tag/%E6%BC%AB%E7%94%BB?start=20&type=T
此处可以配合chrome浏览器的插件 xpath helper配合验证你的xpath是否正确,
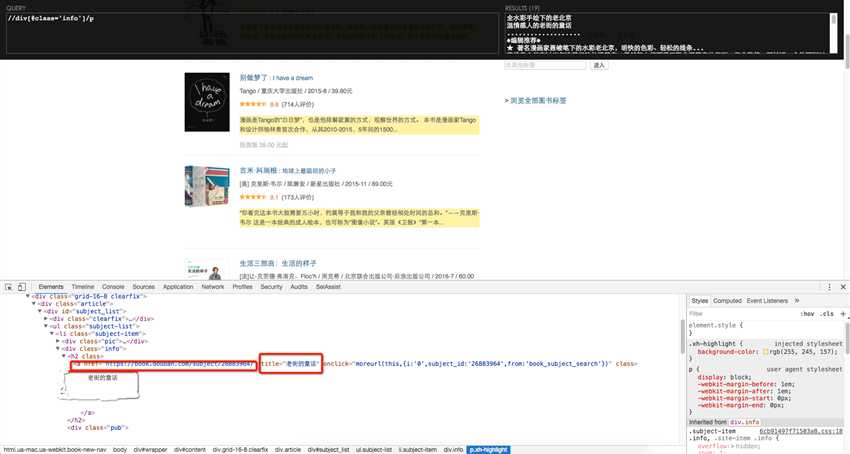
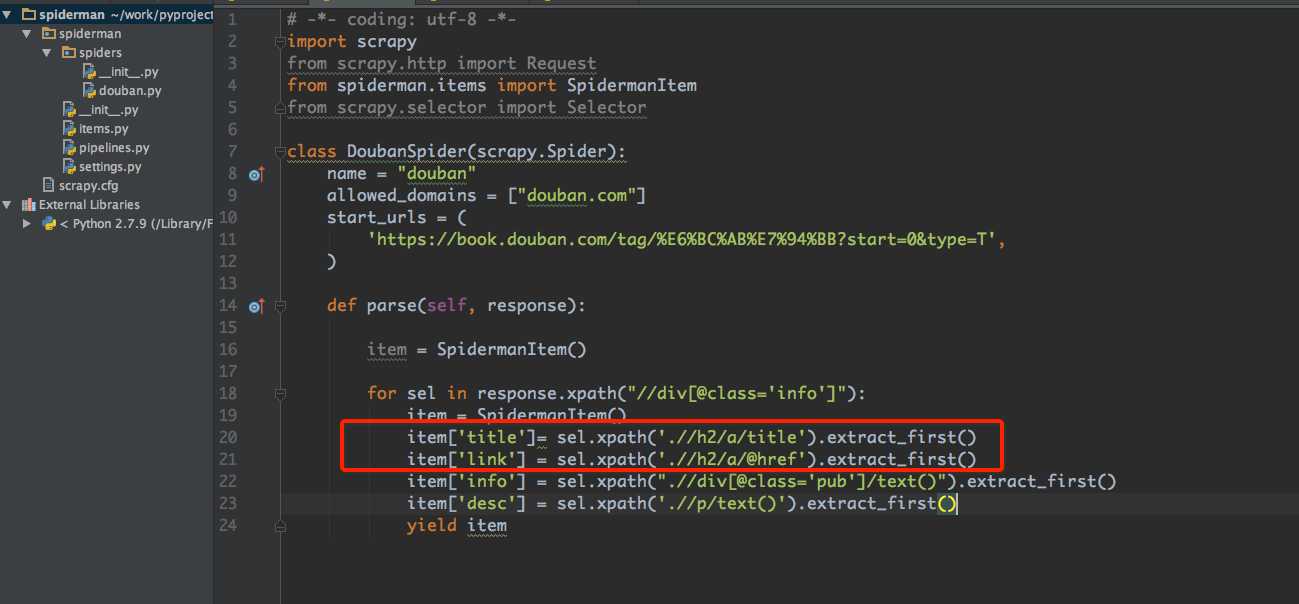
这里我想要获取a标签下的href和a标签中的title , 使用图中红色框内的 extract_first() , 注意这里xpath的语法,前面要加上".",否则会从文档根节点而不是当前节点为起点开始查询
如果想要获取标签内的文本值则使用 /text()即可
标签:.com 否则 span 数据采集 images chrome path pytho 技术
原文地址:http://www.cnblogs.com/jinjidedale/p/6068882.html