标签:ati exit auto 集合 fail writable 编译 测试数据 lin
下面,是版本1。
这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码。这里不多赘述,直接送上代码。
MRUnit是Cloudera公司专为Hadoop MapReduce写的单元测试框架,API非常简洁实用。MRUnit针对不同测试对象使用不同的Driver:
MapDriver:针对单独的Map测试
ReduceDriver:针对单独的Reduce测试
MapReduceDriver:将map和reduce串起来测试
PipelineMapReduceDriver:将多个MapReduce对串志来测试
记得,将这个jar包,放到工程项目里。我这里是在工程项目的根目录下的lib下。
代码版本2
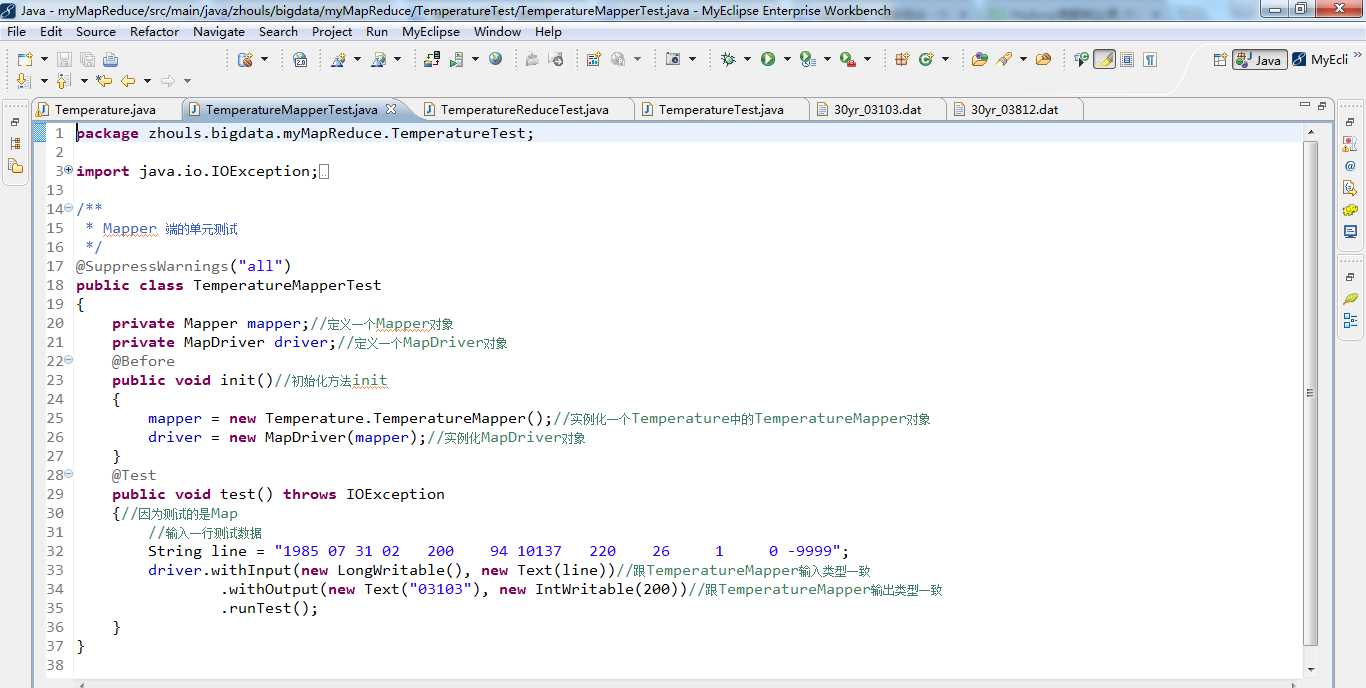
编写TemperatureMapperTest.java的代码。 编译,出现以下,则说明无误。

在test()方法中,withInput的key/value参数分别为偏移量和一行气象数据,其类型要与TemperatureMapper的输入类型一致即为LongWritable和Text。 withOutput的key/value参数分别是我们期望输出的new Text("03103")和new IntWritable(200),我们要达到的测试效果就是我们的期望输出结果与 TemperatureMapper 的实际输出结果一致。
测试方法为 test() 方法,左边的对话框里显示"Runs:1/1,Errors:0,Failures:0",说明 Mapper 测试成功了。
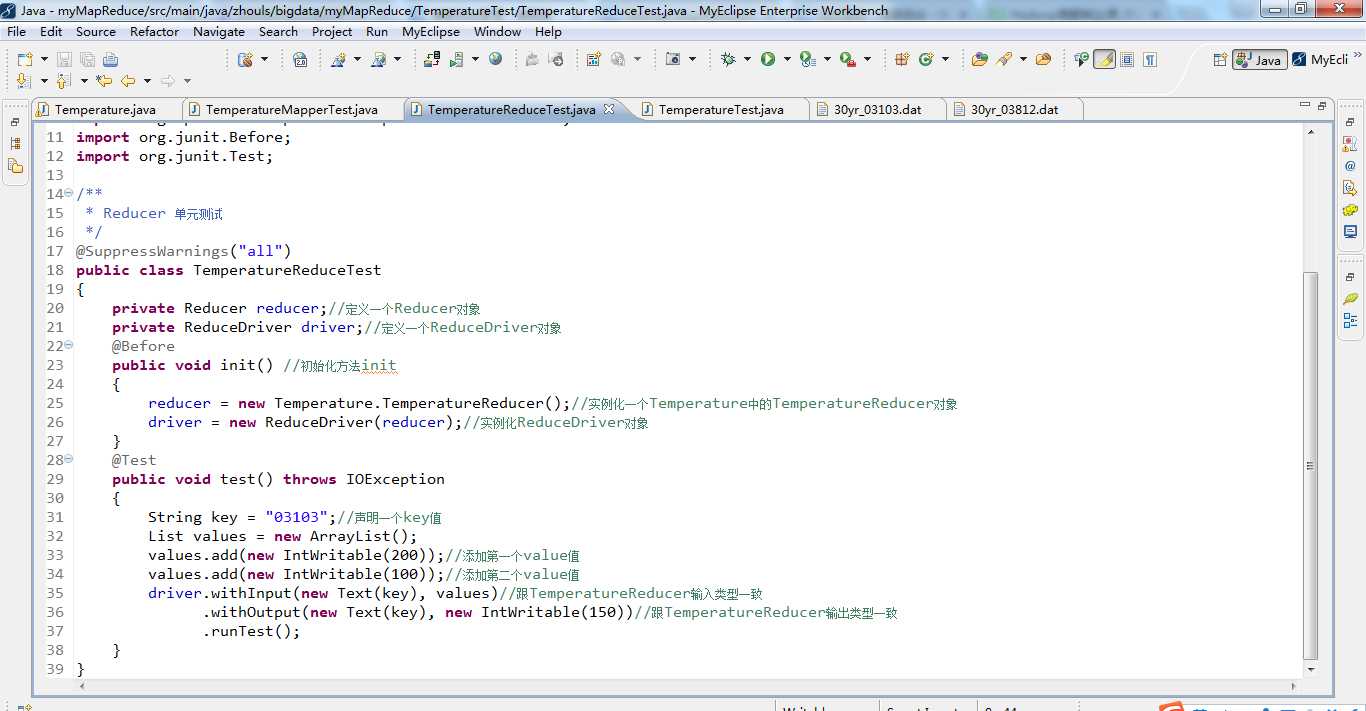
创建TemperatureReduceTest.java,来对Reduce进行测试。
在test()方法中,withInput的key/value参数分别为new Text(key)和List类型的集合values。withOutput 的key/value参数分别是我们所期望输出的new Text(key)和new IntWritable(150),我们要达到的测试效果就是我们的期望输出结果与TemperatureReducer实际输出结果一致。
编写TemperatureReduceTest.java的代码。 编译,出现以下,则说明无误。
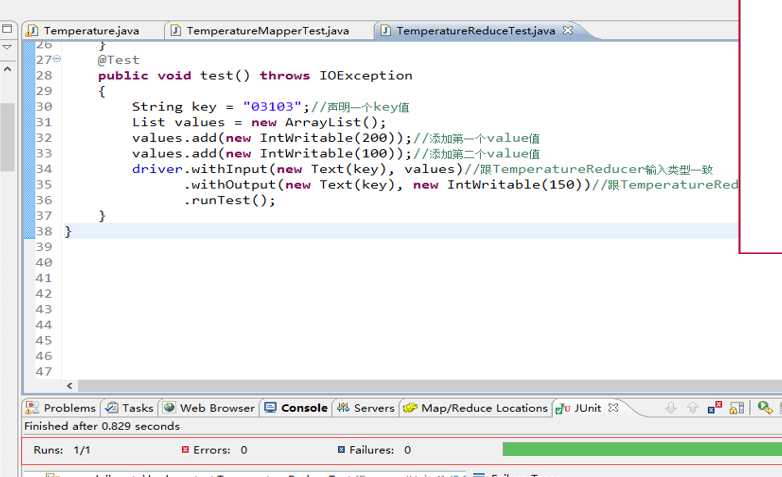
Reducer 端的单元测试,鼠标放在 TemperatureReduceTest 类上右击,选择 Run As ——> JUnit test,运行结果如下所示。
测试方法为 test() 方法,左边的对话框里显示"Runs:1/1,Errors:0,Failures:0",说明 Reducer 测试成功了。
MapReduce 单元测试
把 Mapper 和 Reducer 集成起来的测试案例代码如下。
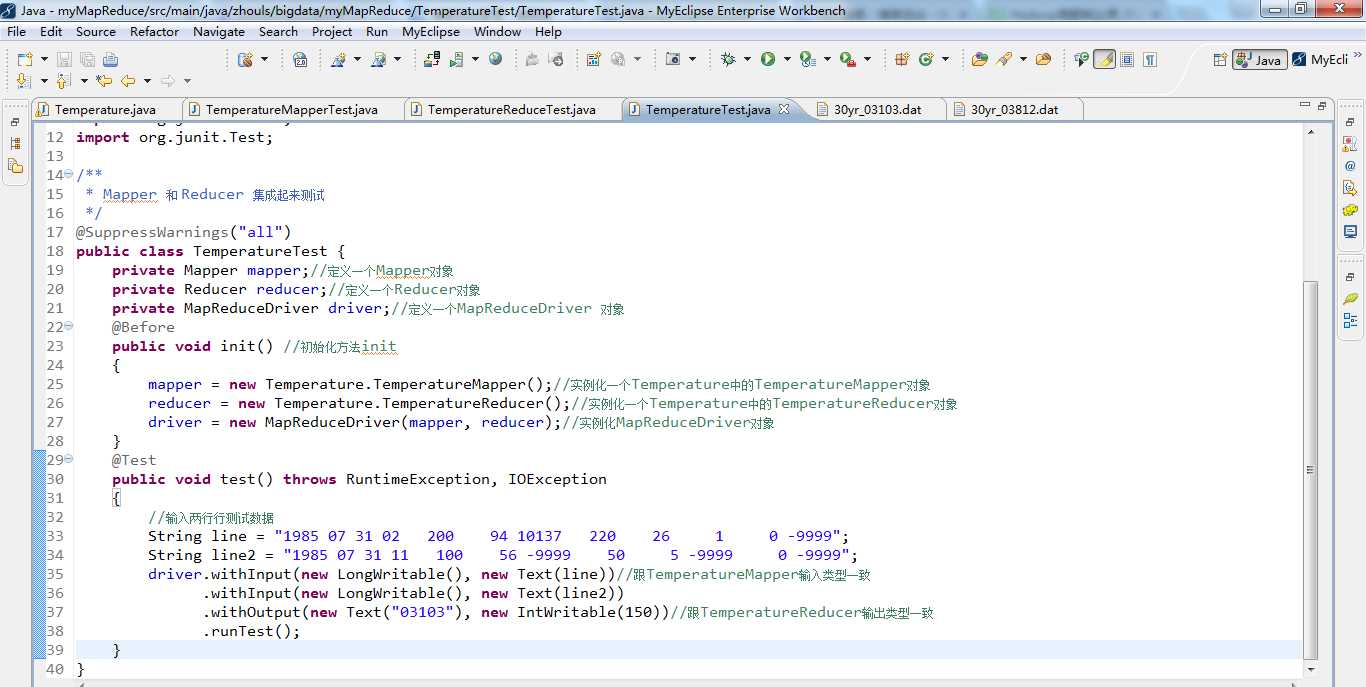
创建TemperatureTest.java,来进行测试。
在 test() 方法中,withInput添加了两行测试数据line和line2,withOutput 的key/value参数分别为我们期望的输出结果new Text("03103")和new IntWritable(150)。我们要达到的测试效果就是我们期望的输出结果与Temperature实际的输出结果一致。
编写TemperatureTest.java的代码。 编译,出现以下,则说明无误。
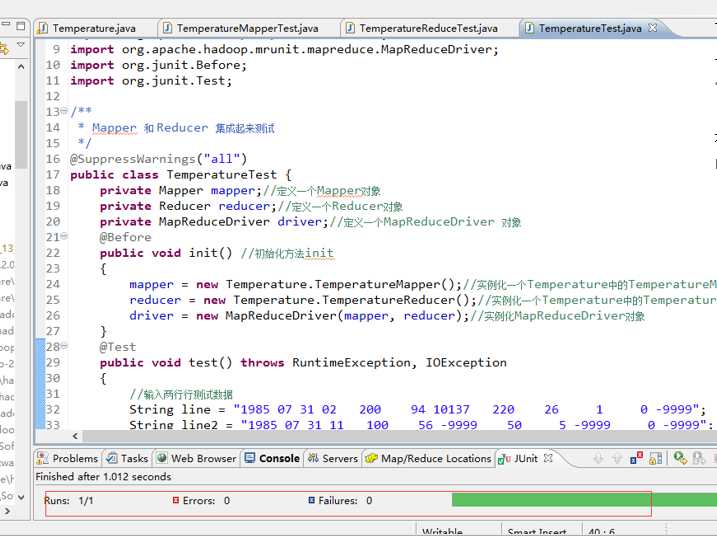
Reducer 端的单元测试,鼠标放在 TemperatureTest.java类上右击,选择 Run As ——> JUnit test,运行结果如下所示。
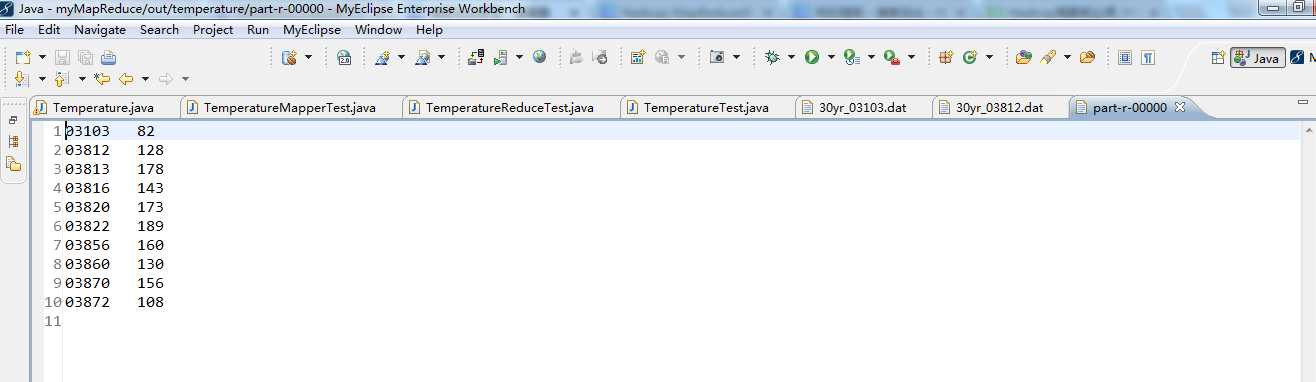
测试方法为 test() 方法,左边的对话框里显示"Runs:1/1,Errors:0,Failures:0",说明 MapReduce 测试成功了。
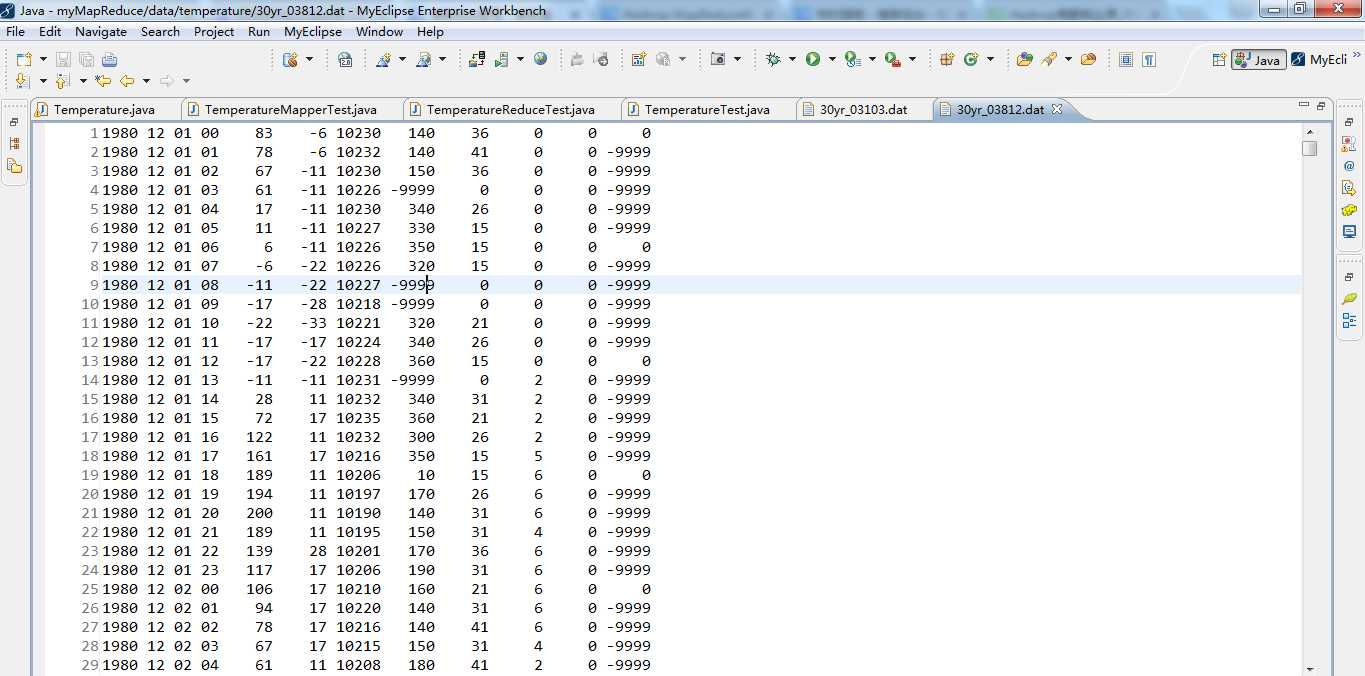
package zhouls.bigdata.myMapReduce.TemperatureTest;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 统计美国每个气象站30年来的平均气温
* 1、编写map()函数
* 2、编写reduce()函数
* 3、编写run()执行方法,负责运行MapReduce作业
* 4、在main()方法中运行程序
*
* @author zhouls
*
*/
//继承Configured类,实现Tool接口
public class Temperature extends Configured implements Tool
{
public static class TemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable>
{ //输入的key,输入的value,输出的key,输出的value
/**
* @function Mapper 解析气象站数据
* @input key=偏移量 value=气象站数据
* @output key=weatherStationId value=temperature
*/
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{ //map()函数还提供了context实例,用于键值对的输出
//第一步,我们将每行气象站数据转换为每行的String类型
String line = value.toString(); //每行气象数据
//第二步:提取气温值
int temperature = Integer.parseInt(line.substring(14, 19).trim());//每小时气温值
//需要转换为整形,截取第14位到19位,把中间的空格去掉。
if (temperature != -9999) //过滤无效数据
{
//第三步:提取气象站编号
//获取输入分片
FileSplit fileSplit = (FileSplit) context.getInputSplit();//提取输入分片,并转换类型
//然后通过文件名称提取气象站编号
String weatherStationId = fileSplit.getPath().getName().substring(5, 10);//通过文件名称提取气象站id
//首先通过文件分片fileSplit来获取文件路径,然后再获取文件名字,然后截取第5位到第10位就可以得到气象站 编号
context.write(new Text(weatherStationId), new IntWritable(temperature));
//气象站编号,气温值
}
}
}
public static class TemperatureReducer extends Reducer< Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable();
//因为气温是IntWritable类型
public void reduce(Text key, Iterable< IntWritable> values,Context context) throws IOException, InterruptedException
{ //reduce输出的key,key的集合,context的实例
//第一步:统计相同气象站的所有气温
int sum = 0;
int count = 0;
for (IntWritable val : values) //for循环来循环同一个气象站的所有气温值
{//对所有气温值累加
sum += val.get();
count++;
}
result.set(sum / count);
context.write(key, result);
}
}
public int run(String[] args) throws Exception
{
// TODO Auto-generated method stub
//第一步:读取配置文件
Configuration conf = new Configuration();//读取配置文件
//第二步:输出路径存在就先删除
Path mypath = new Path(args[1]);//定义输出路径的Path对象,mypath
FileSystem hdfs = mypath.getFileSystem(conf);//通过路径下的getFileSystem来获得文件系统
if (hdfs.isDirectory(mypath))//如果输出路径存在
{
hdfs.delete(mypath, true);//则就删除
}
//第三步:构建job对象
Job job = new Job(conf, "temperature");//新建一个任务,job名字是tempreature
job.setJarByClass(Temperature.class);// 设置主类
//通过job对象来设置主类Temperature.class
//第四步:指定数据的输入路径和输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径,args[0]
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径,args[1]
//第五步:指定Mapper和Reducer
job.setMapperClass(TemperatureMapper.class);// Mapper
job.setReducerClass(TemperatureReducer.class);// Reducer
//第六步:设置map函数和reducer函数的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第七步:提交作业
return job.waitForCompletion(true)?0:1;//提交任务
}
/**
* @function main 方法
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception
{
//第一步
// String[] args0 =
// {
// "hdfs://HadoopMaster:9000/temperature/",
// "hdfs://HadoopMaster:9000/out/temperature/"
// };
String[] args0 =
{
"./data/temperature/",
"./out/temperature/"
};
//第二步
int ec = ToolRunner.run(new Configuration(), new Temperature(), args0);
//第一个参数是读取配置文件,第二个参数是主类Temperature,第三个参数是输如路径和输出路径的属组
System.exit(ec);
}
}
package zhouls.bigdata.myMapReduce.TemperatureTest;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.junit.Before;
import org.junit.Test;
/**
* Mapper 端的单元测试
*/
@SuppressWarnings("all")
public class TemperatureMapperTest
{
private Mapper mapper;//定义一个Mapper对象
private MapDriver driver;//定义一个MapDriver对象
@Before
public void init()//初始化方法init
{
mapper = new Temperature.TemperatureMapper();//实例化一个Temperature中的TemperatureMapper对象
driver = new MapDriver(mapper);//实例化MapDriver对象
}
@Test
public void test() throws IOException
{//因为测试的是Map
//输入一行测试数据
String line = "1985 07 31 02 200 94 10137 220 26 1 0 -9999";
driver.withInput(new LongWritable(), new Text(line))//跟TemperatureMapper输入类型一致
.withOutput(new Text("03103"), new IntWritable(200))//跟TemperatureMapper输出类型一致
.runTest();
}
}
package zhouls.bigdata.myMapReduce.TemperatureTest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;
import org.junit.Before;
import org.junit.Test;
/**
* Reducer 单元测试
*/
@SuppressWarnings("all")
public class TemperatureReduceTest
{
private Reducer reducer;//定义一个Reducer对象
private ReduceDriver driver;//定义一个ReduceDriver对象
@Before
public void init() //初始化方法init
{
reducer = new Temperature.TemperatureReducer();//实例化一个Temperature中的TemperatureReducer对象
driver = new ReduceDriver(reducer);//实例化ReduceDriver对象
}
@Test
public void test() throws IOException
{
String key = "03103";//声明一个key值
List values = new ArrayList();
values.add(new IntWritable(200));//添加第一个value值
values.add(new IntWritable(100));//添加第二个value值
driver.withInput(new Text(key), values)//跟TemperatureReducer输入类型一致
.withOutput(new Text(key), new IntWritable(150))//跟TemperatureReducer输出类型一致
.runTest();
}
}
package zhouls.bigdata.myMapReduce.TemperatureTest;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mrunit.mapreduce.MapReduceDriver;
import org.junit.Before;
import org.junit.Test;
/**
* Mapper 和 Reducer 集成起来测试
*/
@SuppressWarnings("all")
public class TemperatureTest {
private Mapper mapper;//定义一个Mapper对象
private Reducer reducer;//定义一个Reducer对象
private MapReduceDriver driver;//定义一个MapReduceDriver 对象
@Before
public void init() //初始化方法init
{
mapper = new Temperature.TemperatureMapper();//实例化一个Temperature中的TemperatureMapper对象
reducer = new Temperature.TemperatureReducer();//实例化一个Temperature中的TemperatureReducer对象
driver = new MapReduceDriver(mapper, reducer);//实例化MapReduceDriver对象
}
@Test
public void test() throws RuntimeException, IOException
{
//输入两行行测试数据
String line = "1985 07 31 02 200 94 10137 220 26 1 0 -9999";
String line2 = "1985 07 31 11 100 56 -9999 50 5 -9999 0 -9999";
driver.withInput(new LongWritable(), new Text(line))//跟TemperatureMapper输入类型一致
.withInput(new LongWritable(), new Text(line2))
.withOutput(new Text("03103"), new IntWritable(150))//跟TemperatureReducer输出类型一致
.runTest();
}
}
Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(九)
标签:ati exit auto 集合 fail writable 编译 测试数据 lin
原文地址:http://www.cnblogs.com/zlslch/p/6164003.html