标签:[1] ant 行数据 cal 西红柿 tac 管道 _id array
1、mongodb数据表相关
# 显示数据库
show dbs
# 数据库
use ceshi
# 显示表
show tables
# 创建集合
db.createCollection(‘infoB‘)
# 复制数据
db.item_infoA.copyTo(‘infoB‘)
# 使用命令导入json 格式的数据
mongoimport -d database_name -c collection_name inpath/file_name.json
# 使用命令导出json 格式的数据
mongoexport -d database_name -c collection_name -o outputpath/file_name.json
2、常用的update与find函数以及日期相关
from string import punctuation for i in item_info.find().limit(50): print(i[‘province‘]) for i in item_info.find(): if i[‘province‘]: province= [i for i in i[‘province‘] if i not in punctuation] else: province= [‘不明‘] # 下面update函数使用了两个参数,第一个标识要更新哪些数据,第二个标识怎样修改 # ‘_id‘:i[‘_id‘],key:value一一对应,通过这种方式表示要更新每一项 sales.update({‘_id‘:i[‘_id‘]},{‘$set‘:{‘province‘:province}}) # find函数,两个参数,分别包含在{}中,第一个标识要找的条件,是一些键值对,第二个标识需要显示的字段,0不显示,1标识显示 # slice分片 for i in item_info.find({‘pub_date‘:{‘$in‘:[‘2016.01.12‘,‘2016.01.14‘]}},{‘area‘:{‘$slice‘:1},‘_id‘:0,‘price‘:0,‘title‘:0}).limit(300): print(i)
from datetime import date from datetime import timedelta #日期 a = date(2017,1,12) print(a) # 2017-01-12 d = timedelta(days=1) print(d) # 1 day, 0:00:00 def get_all_dates(date1,date2): the_date = date(int(date1.split(‘.‘)[0]),int(date1.split(‘.‘)[1]),int(date1.split(‘.‘)[2])) end_date = date(int(date2.split(‘.‘)[0]),int(date2.split(‘.‘)[1]),int(date2.split(‘.‘)[2])) days = timedelta(days=1) while the_date <= end_date: yield (the_date.strftime(‘%Y.%m.%d‘)) the_date = the_date + days for i in get_all_dates(‘2017.01.02‘,‘2017.01.12‘): print(i)
3、相关数据格式
西红柿 蔬菜 山东 2.8 新 1500 kg 2017-1-11 卷心菜 蔬菜 河北 1.5 鲜 1000 kg 2017-1-9 玉米 粮食 辽宁 0.8 新 1580 kg 2016-11-25 大豆 粮食 山东 1.1 新 1000 kg 2017-1-8 卷心菜 蔬菜 河北 1.5 鲜 2705 kg 2017-1-9 玉米 粮食 辽宁 0.8 新 1669 kg 2016-11-25 大米 粮食 浙江 0.7 新 2115 kg 2016-11-28 大米 粮食 江苏 0.8 新 2151 kg 2016-11-15 西瓜 水果 山东 0.5 鲜 1518 kg 2016-10-1 山楂 水果 山东 2.5 鲜 1116 kg 2016-9-1 茄子 蔬菜 江苏 1.1 鲜 1500 kg 2016-9-15 小麦 粮食 河北 1.2 新 1695 kg 2016-9-1 葡萄 水果 山东 2.1 鲜 1719 kg 2016-9-17
4 、按照产品分类计算销售额
import charts
def data_gen(cates): pipeline = [ {‘$match‘:{‘$and‘:[ {‘category‘:{‘$in‘:cates}}, {‘province‘:{‘$nin‘:[‘江苏‘]}} ]}}, {‘$group‘:{‘_id‘:‘$category‘,‘sum_sales‘:{‘$sum‘:{ ‘$multiply‘:[‘$price‘,‘$quantity‘] }}}}, {‘$sort‘:{‘sum_sales‘:1}} ] for i in salesnew.aggregate(pipeline): data = { ‘name‘: i[‘_id‘], ‘data‘: [i[‘sum_sales‘]], ‘type‘: ‘column‘ } yield data for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘]): print(i) series = [i for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘])] options = { ‘chart‘ : {‘zoomType‘:‘xy‘}, ‘title‘ : {‘text‘: ‘销售金额‘}, ‘subtitle‘: {‘text‘: ‘图表‘}, ‘yAxis‘ : {‘title‘: {‘text‘: ‘金额‘}} } charts.plot(series,options=options,show=‘inline‘)
结果:
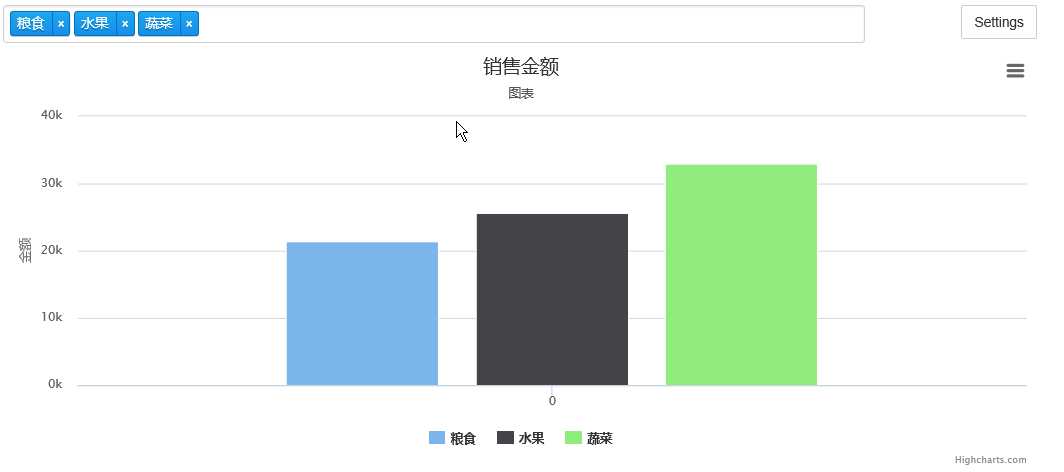
值得注意的一点,在管道中不好进行数据类型的转换,所以最好存入mongodb中的数据是正确的数据类型。
关于数据类型的转换参考文章 how to convert string to numerical values in mongodb 地址:http://stackoverflow.com/questions/29487351/how-to-convert-string-to-numerical-values-in-mongodb
#代码: db.my_collection.find({moop : {$exists : true}}).forEach( function(obj) { obj.moop = new NumberInt( obj.moop ); db.my_collection.save(obj); } );
5、计算每个每个月的销售数量
def data_gen(cates): pipeline = [ { ‘$project‘ : { ‘quantity‘: 1,‘province‘: 1,‘saledate‘: 1,‘category‘:1,‘ymstring‘ : { ‘$concat‘: [ {‘$arrayElemAt‘: [ {‘$split‘: [‘$saledate‘, ‘-‘]}, 0 ]},‘-‘, {‘$arrayElemAt‘: [ {‘$split‘: [‘$saledate‘, ‘-‘]}, 1 ]}] }}}, {‘$match‘:{‘$and‘:[ {‘category‘:{‘$in‘:cates}}, {‘province‘:{‘$nin‘:[‘江苏‘]}} ]}}, {‘$group‘:{‘_id‘:‘$ymstring‘ ,‘sum_quantity‘:{‘$sum‘:‘$quantity‘}}}, {‘$sort‘:{‘sum_quantity‘:1}} ] for i in salesnew.aggregate(pipeline): yield i for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘]): print(i)
# 结果 {‘_id‘: ‘2016-10‘, ‘sum_quantity‘: 1518} {‘_id‘: ‘2016-8‘, ‘sum_quantity‘: 4350} {‘_id‘: ‘2016-12‘, ‘sum_quantity‘: 8223} {‘_id‘: ‘2016-11‘, ‘sum_quantity‘: 11283} {‘_id‘: ‘2016-9‘, ‘sum_quantity‘: 12037} {‘_id‘: ‘2017-1‘, ‘sum_quantity‘: 12394}
各个函数的相关参考 https://docs.mongodb.com/manual/reference/operator/aggregation/
语句: ‘$concat‘: [ {‘$arrayElemAt‘: [ {‘$split‘: [‘$saledate‘, ‘-‘]}, 0 ]}, ‘-‘, {‘$arrayElemAt‘: [ {‘$split‘: [‘$saledate‘, ‘-‘]}, 1 ]} ] 解释如下: # 分组 ‘$split‘: [‘$saledate‘, ‘-‘] # 数组中的元素,语法:$arrayElemAt: [ <array>, <idx> ] # 因为$split也是函数,所以用{}来包含 ‘$arrayElemAt‘: [ {‘$split‘: [‘$saledate‘, ‘-‘]}, 0 ] ‘$arrayElemAt‘: [ {‘$split‘: [‘$saledate‘, ‘-‘]}, 1 ] # 最后,用$concat函数连接,语法{ $concat: [ <expression1>, <expression2>, ... ] } # 同样,由于$arrayElemAt函数,所以用{}来包含{‘$arrayElemAt‘: [ ‘arrayname‘, 0 ]},否则,不需要{}
#以下两个函数作用相同,区别在于,第一个‘$slice在$group中,第二个在$project中
$slice可以指定从第几个元素开始分片
{ $slice: [ <array>, <position>, <n> ] }
{ $slice: [ <array>, <n> ] }
def data_gen(cates): pipeline = [ { ‘$project‘ : { ‘quantity‘: 1,‘province‘: 1,‘saledate‘: 1,‘category‘:1,‘ymarray‘ : { ‘$split‘: [‘$saledate‘, ‘-‘] }}}, {‘$match‘:{‘$and‘:[ {‘category‘:{‘$in‘:cates}}, {‘province‘:{‘$nin‘:[‘江苏‘]}} ]}}, {‘$group‘:{‘_id‘:{ ‘$slice‘: [‘$ymarray‘,2] },‘sum_quantity‘:{‘$sum‘:‘$quantity‘}}}, {‘$sort‘:{‘sum_quantity‘:1}} ] for i in salesnew.aggregate(pipeline): print(‘ymarray‘) yield i for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘]): print(i) { ‘$slice‘:[ {‘$split‘: [‘$saledate‘, ‘-‘]},2 ]}
def data_gen(cates): pipeline = [ { ‘$project‘ : { ‘quantity‘: 1,‘province‘: 1,‘saledate‘: 1,‘category‘:1,‘ymarray‘ : { ‘$slice‘:[ {‘$split‘: [‘$saledate‘, ‘-‘]},2 ]} }}, {‘$match‘:{‘$and‘:[ {‘category‘:{‘$in‘:cates}}, {‘province‘:{‘$nin‘:[‘江苏‘]}} ]}}, {‘$group‘:{‘_id‘:‘$ymarray‘,‘sum_quantity‘:{‘$sum‘:‘$quantity‘}}}, {‘$sort‘:{‘sum_quantity‘:1}} ] for i in salesnew.aggregate(pipeline): yield i for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘]): print(i)
# 结果 {‘_id‘: [‘2016‘, ‘10‘], ‘sum_quantity‘: 1518} {‘_id‘: [‘2016‘, ‘8‘], ‘sum_quantity‘: 4350} {‘_id‘: [‘2016‘, ‘12‘], ‘sum_quantity‘: 8223} {‘_id‘: [‘2016‘, ‘11‘], ‘sum_quantity‘: 11283} {‘_id‘: [‘2016‘, ‘9‘], ‘sum_quantity‘: 12037} {‘_id‘: [‘2017‘, ‘1‘], ‘sum_quantity‘: 12394}
6、计算每个月的销售额
def data_gen(cates): pipeline = [ { ‘$project‘ : { ‘quantity‘: 1,‘province‘: 1,‘saledate‘: 1,‘category‘:1 , ‘price‘:1}}, {‘$match‘:{‘$and‘:[ {‘category‘:{‘$in‘:cates}}, {‘province‘:{‘$nin‘:[‘江苏‘]}} ]}}, # 先统计每天的销售额,注意$multiply函数的用法 {‘$group‘:{‘_id‘:‘$saledate‘,‘sum_quantity‘:{‘$sum‘:{ ‘$multiply‘:[‘$price‘,‘$quantity‘] }}}}, # 在上面的基础上继续分组,构造月份作为分组依据,注意上面的$saledate变为$_id,sum_quantity变为$sum_quantity,前面有$符号 {‘$group‘:{‘_id‘:{‘$concat‘: [ {‘$arrayElemAt‘: [ {‘$split‘: [‘$_id‘, ‘-‘]}, 0 ]},‘-‘, {‘$arrayElemAt‘: [ {‘$split‘: [‘$_id‘, ‘-‘]}, 1 ]}]},‘sumend‘:{‘$sum‘:‘$sum_quantity‘}}}, {‘$sort‘:{‘sumend‘:1}} ] for i in salesnew.aggregate(pipeline): data = { ‘name‘: i[‘_id‘], ‘data‘: [i[‘sumend‘]], ‘type‘: ‘column‘ } yield data for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘]): print(i) series = [i for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘])] options = { ‘chart‘ : {‘zoomType‘:‘xy‘}, ‘title‘ : {‘text‘: ‘销售数量‘}, ‘subtitle‘: {‘text‘: ‘图表‘}, ‘yAxis‘ : {‘title‘: {‘text‘: ‘数量‘}} } charts.plot(series,options=options,show=‘inline‘)
def data_gen(cates): pipeline = [ { ‘$project‘ : { ‘quantity‘: 1,‘province‘: 1,‘saledate‘: 1,‘category‘:1 , ‘price‘:1 }}, {‘$match‘:{‘$and‘:[ {‘category‘:{‘$in‘:cates}}, {‘province‘:{‘$nin‘:[‘江苏‘]}} ]}}, {‘$group‘:{‘_id‘:‘$saledate‘,‘sum_quantity‘:{‘$sum‘:{ ‘$multiply‘:[‘$price‘,‘$quantity‘] }}}}, # 不同之处在于这里构建了一个新字段,注意各个字段是基于上一步的sum_quantity,_id,即上面的$saledate,使用$contat时,用$_id {‘$project‘ : { ‘sum_quantity‘: 1,‘_id‘: 1, ‘ym‘: {‘$concat‘: [ {‘$arrayElemAt‘: [ {‘$split‘: [‘$_id‘, ‘-‘]}, 0 ]},‘-‘, {‘$arrayElemAt‘: [ {‘$split‘: [‘$_id‘, ‘-‘]}, 1 ]}] } }}, {‘$group‘:{‘_id‘:‘$ym‘,‘sumend‘:{‘$sum‘:‘$sum_quantity‘}}}, {‘$sort‘:{‘sumend‘:1}} ] for i in salesnew.aggregate(pipeline): data = { ‘name‘: i[‘_id‘], ‘data‘: [i[‘sumend‘]], ‘type‘: ‘column‘ } yield data for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘]): print(i) series = [i for i in data_gen([‘水果‘,‘蔬菜‘,‘粮食‘])] options = { ‘chart‘ : {‘zoomType‘:‘xy‘}, ‘title‘ : {‘text‘: ‘销售额‘}, ‘subtitle‘: {‘text‘: ‘图表‘}, ‘yAxis‘ : {‘title‘: {‘text‘: ‘金额‘}} } charts.plot(series,options=options,show=‘inline‘)
#
{‘name‘: ‘2016-10‘, ‘data‘: [759.0], ‘type‘: ‘column‘} {‘name‘: ‘2016-11‘, ‘data‘: [12369.8], ‘type‘: ‘column‘} {‘name‘: ‘2016-12‘, ‘data‘: [12566.1], ‘type‘: ‘column‘} {‘name‘: ‘2016-8‘, ‘data‘: [6535.2], ‘type‘: ‘column‘} {‘name‘: ‘2016-9‘, ‘data‘: [22804.2], ‘type‘: ‘column‘} {‘name‘: ‘2017-1‘, ‘data‘: [24873.3], ‘type‘: ‘column‘}
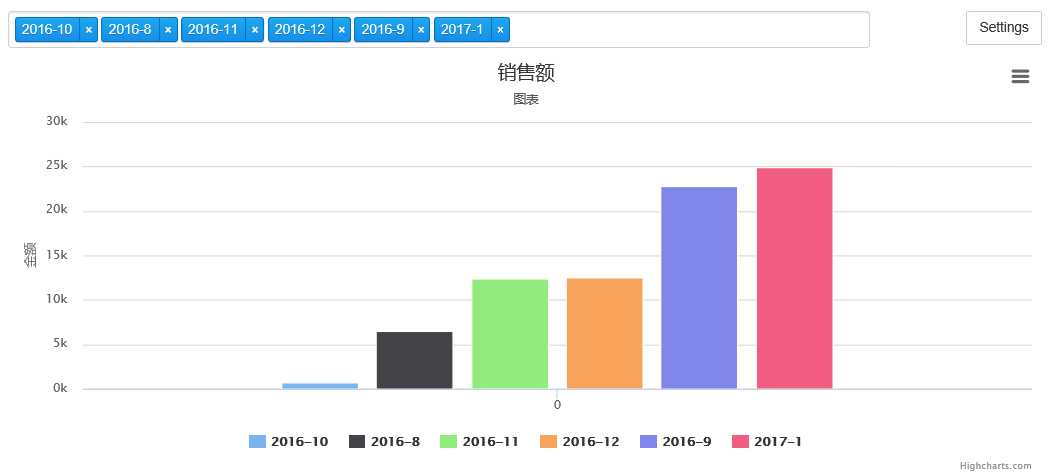
highcharts 参考:
http://www.highcharts.com/
标签:[1] ant 行数据 cal 西红柿 tac 管道 _id array
原文地址:http://www.cnblogs.com/learn21cn/p/6281422.html