标签:win bsp practice extra sep vector wal and when
Informally, the C parameter is a positive value that controls the penalty for misclassi?ed training examples. A large C parameter tells the SVM to try to classify all the examples correctly. C plays a role similar to 1 , where is the regularization parameter that we were using previously for logistic regression.
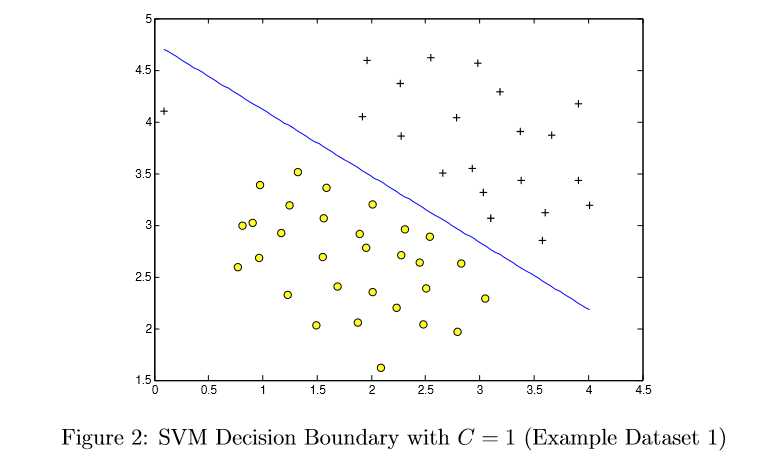
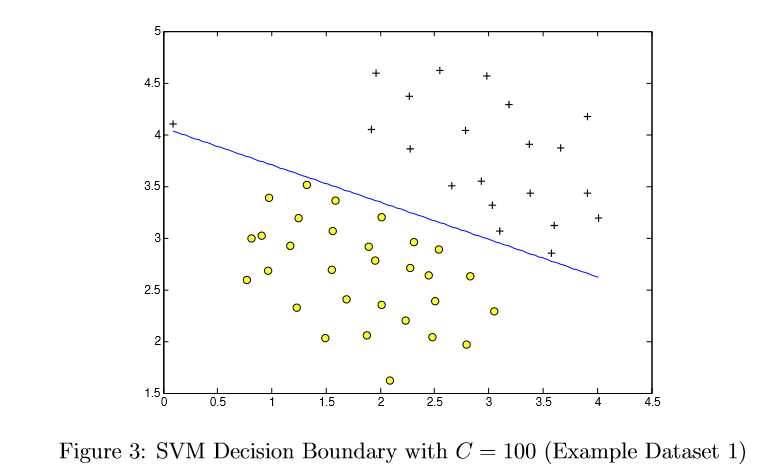
Most SVM software packages (including svmTrain.m) automatically add the extra featurex0 = 1 for you and automatically take care of learning the intercept term ?0. So when passing your training data to the SVM software, there is no need to add this extra feature x0 = 1 yourself. In particular, in Octave/MATLAB your code should be working with training examples x2Rn (rather than x:Rn+1); for example, in the ?rst example dataset x:R2.
To ?nd non-linear decision boundaries with the SVM, we need to ?rst implement a Gaussian kernel. You can think of the Gaussian kernel as a similarity function that measures the “distance” between a pair of examples, (x(i),x (j)). The Gaussian kernel is also parameterized by a bandwidth parameter, , which determines how fast the similarity metric decreases (to 0) as the examples are further apart.
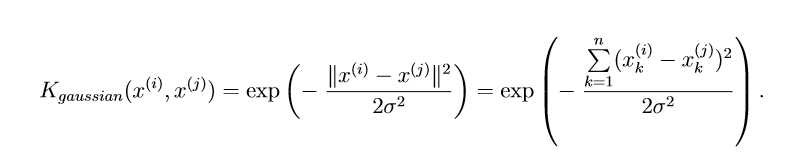
sim=exp(-(x1-x2)‘*(x1-x2)/2/(sigma*sigma));
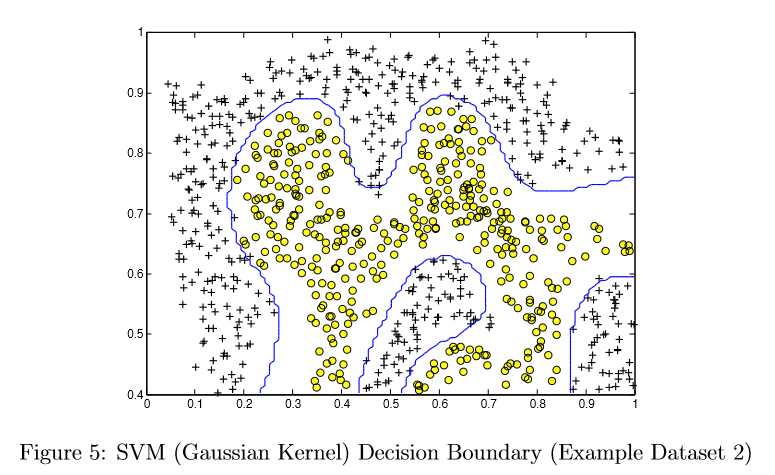
By using the Gaussian kernel with the SVM, you will be able to learn a non-linear decision boundary that can perform reasonably well for the dataset.
Figure 5 shows the decision boundary found by the SVM with a Gaussian kernel. The decision boundary is able to separate most of the positive and negative examples correctly and follows the contours of the dataset well.
use cv to determine the best C and sigma:
params = [0.01, 0.03, 0.1, 0.3 ,1 ,3 ,10, 30]‘;
minErr = 1;
indexC = -1;
indexSigma = -1;
for i = 1:size(params,1)
for j = 1:size(params,1)
C=params(i);
sigma=params(j);
model = svmTrain(X,y,C,@(x1,x2) gaussianKernel(x1,x2,sigma));
predictions = svmPredict(model,Xval);
err = mean(double(predictions~=yval));
if err < minErr
minErr = err;
indexC = i;
indexSigma = j;
end
end
end
C = params(indexC);
sigma = params(indexSigma);
You will be training a classi?er to classify whether a given email, x, is spam (y = 1) or non-spam ( y = 0). In particular, you need to convert each email into a feature vector x 2 Rn. The following parts of the exercise will walk you through how such a feature vector can be constructed from an email.
Therefore, one method often employed in processing emails is to “normalize” these values, so that all URLs are treated the same, all numbers are treated the same, etc. For example, we could replace each URL in the email with the unique string “httpaddr” to indicate that a URL was present.
This has the e?ect of letting the spam classi?er make a classi?cation decision based on whether any URL was present, rather than whether a speci?c URL was present. This typically improves the performance of a spam classi?er, since spammers often randomize the URLs, and thus the odds of seeing any particular URL again in a new piece of spam is very small.

idx = -1;
for i = 1:length(vocabList)
if strcmp(vocalList{i},str) == 1
idx = 1;
break;
end
end
if idx~=-1
word_indices = [word_indices;idx];
end
For this exercise, we have chosen only the most frequently occuring words as our set of words considered (the vocabulary list). Since words that occur rarely in the training set are only in a few emails, they might cause the model to over?t our training set. The complete vocabulary list is in the ?le vocab.txt and also shown in Figure 10. Our vocabulary list was selected by choosing all words which occur at least a 100 times in the spam corpus, resulting in a list of 1899 words. In practice, a vocabulary list with about 10,000 to 50,000 words is often used.
for i = 1:length(word_indices)
x(word_indices(i)) = 1;
end
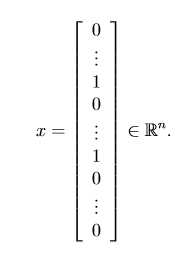
Your task in this optional (ungraded) exercise is to download the original ?les from the public corpus and extract them. After extracting them, you should run the processEmail4 and emailFeatures functions on each email to extract a feature vector from each email. This will allow you to build a dataset X, y of examples. You should then randomly divide up the dataset into a training set, a cross validation set and a test set.
While you are building your own dataset, we also encourage you to try building your own vocabulary list (by selecting the high frequency words that occur in the dataset) and adding any additional features that you think might be useful.
coursera:machine learing--code-3
标签:win bsp practice extra sep vector wal and when
原文地址:http://www.cnblogs.com/kprac/p/6367516.html