标签:数据 poi 表达 分享 color handle 传奇 最大 ima
作业调度的划分算法以及 Task 的最佳位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这也是关系到整个作业有集群中该怎么运行;其次就是数据本地性,Spark 一舨的代码都是链式表达的,这就让一个任务什么时候划分成 Stage,在大数据世界要追求最大化的数据本地性,所有最大化的数据本地性就是在数据计算的时候,数据就在内存中。最后就是 Spark 的实现算法时候的略的怎么样。希望这篇文章能为读者带出以下的启发:
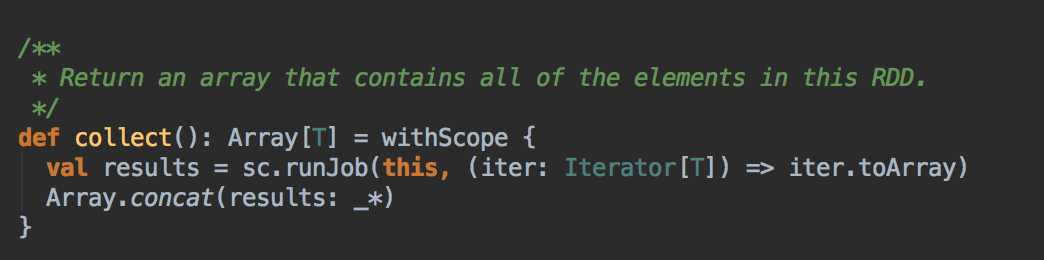

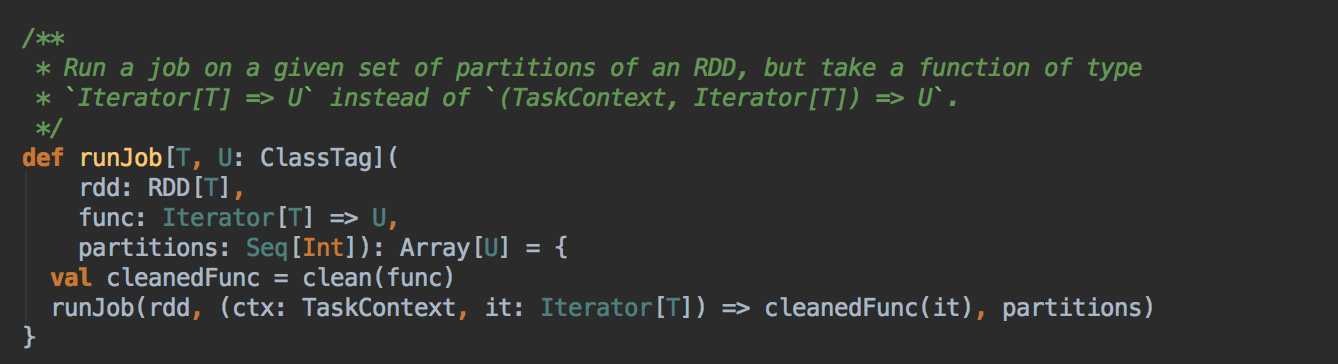
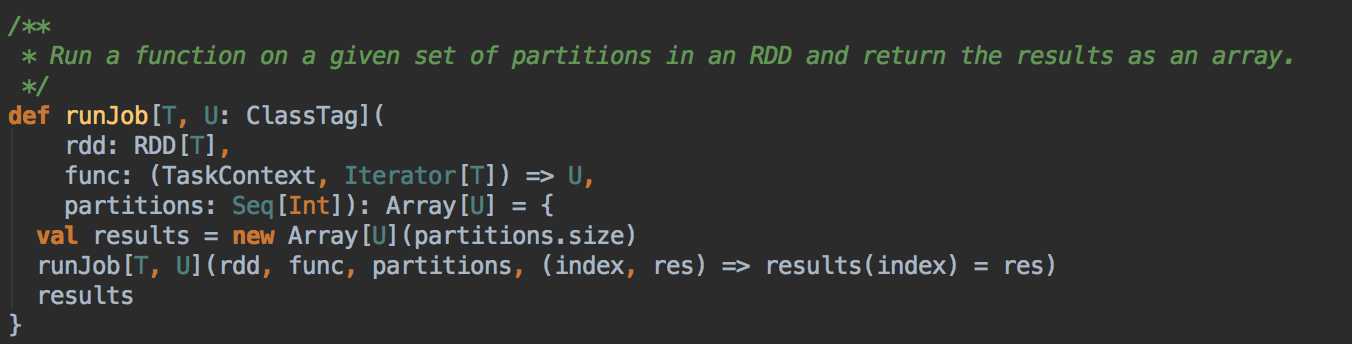
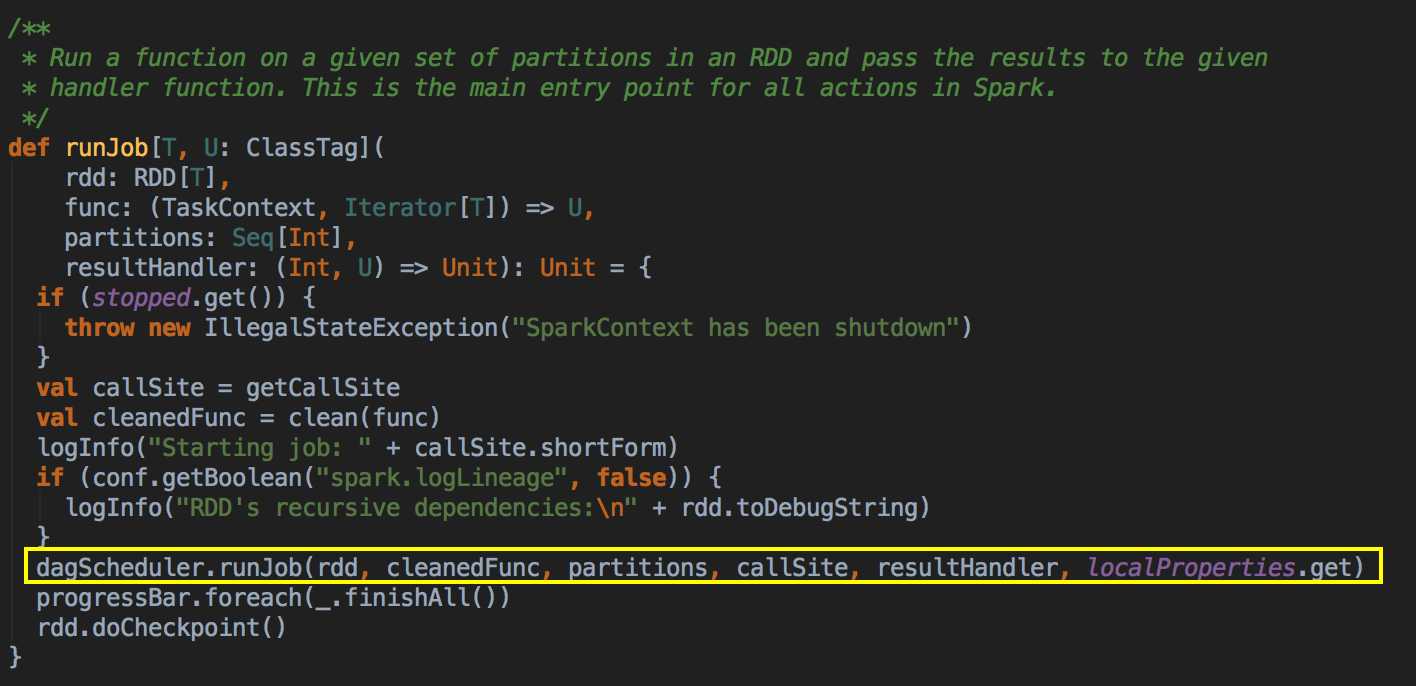
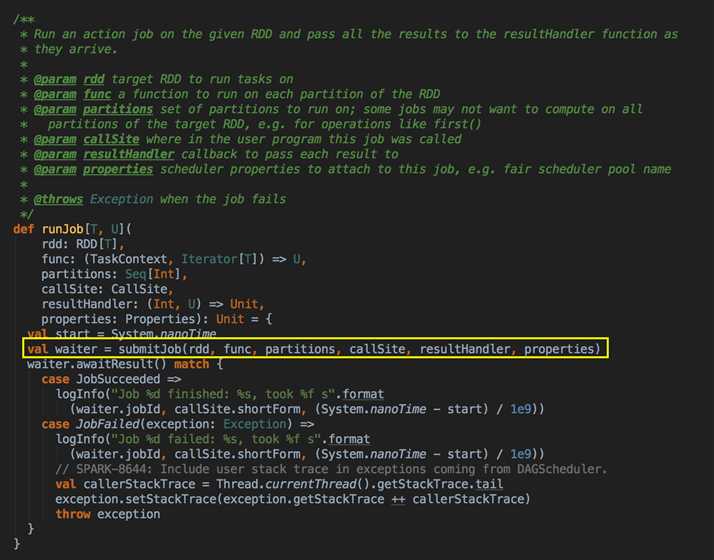
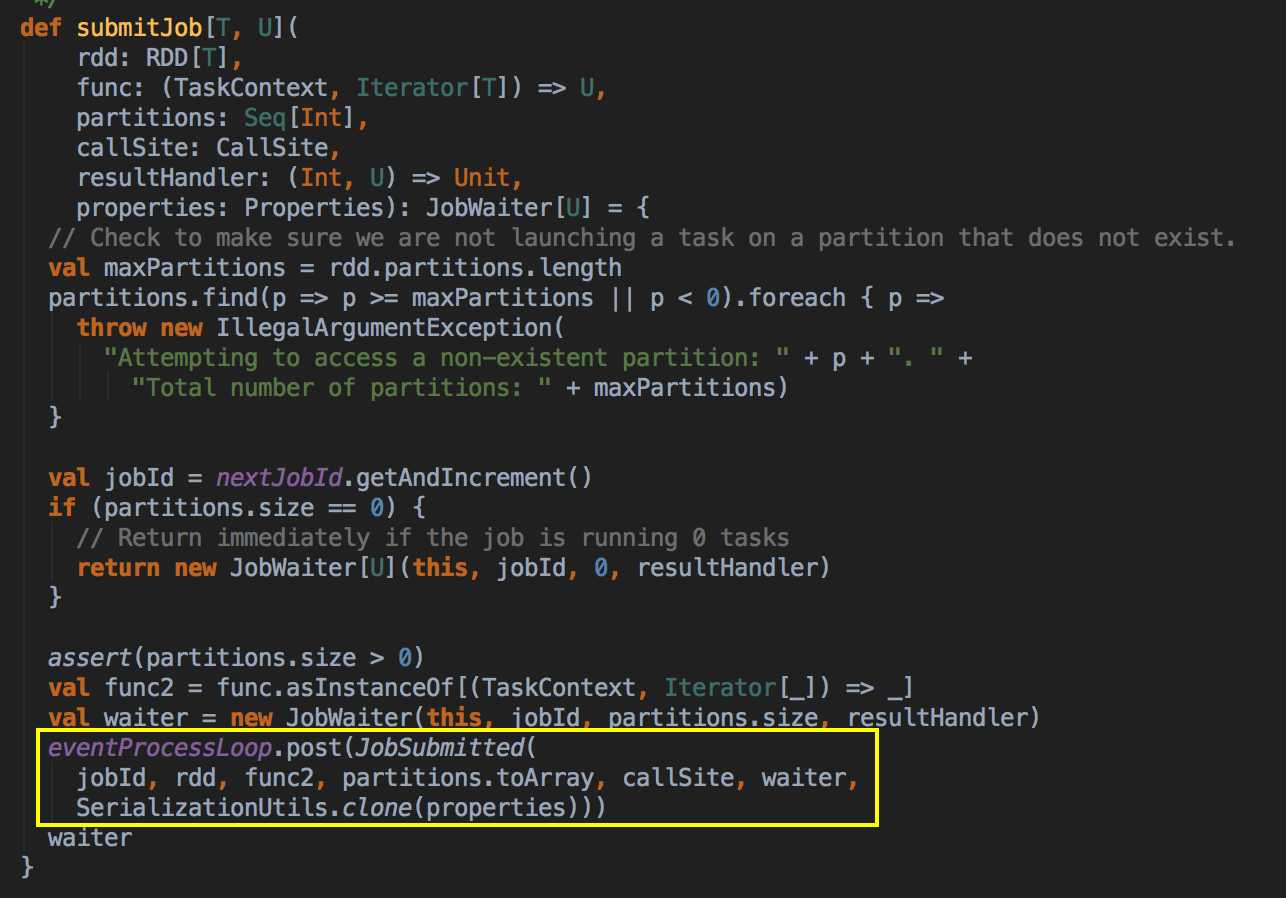
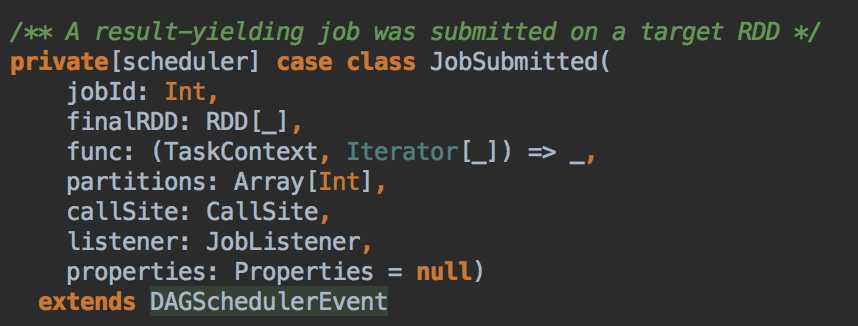
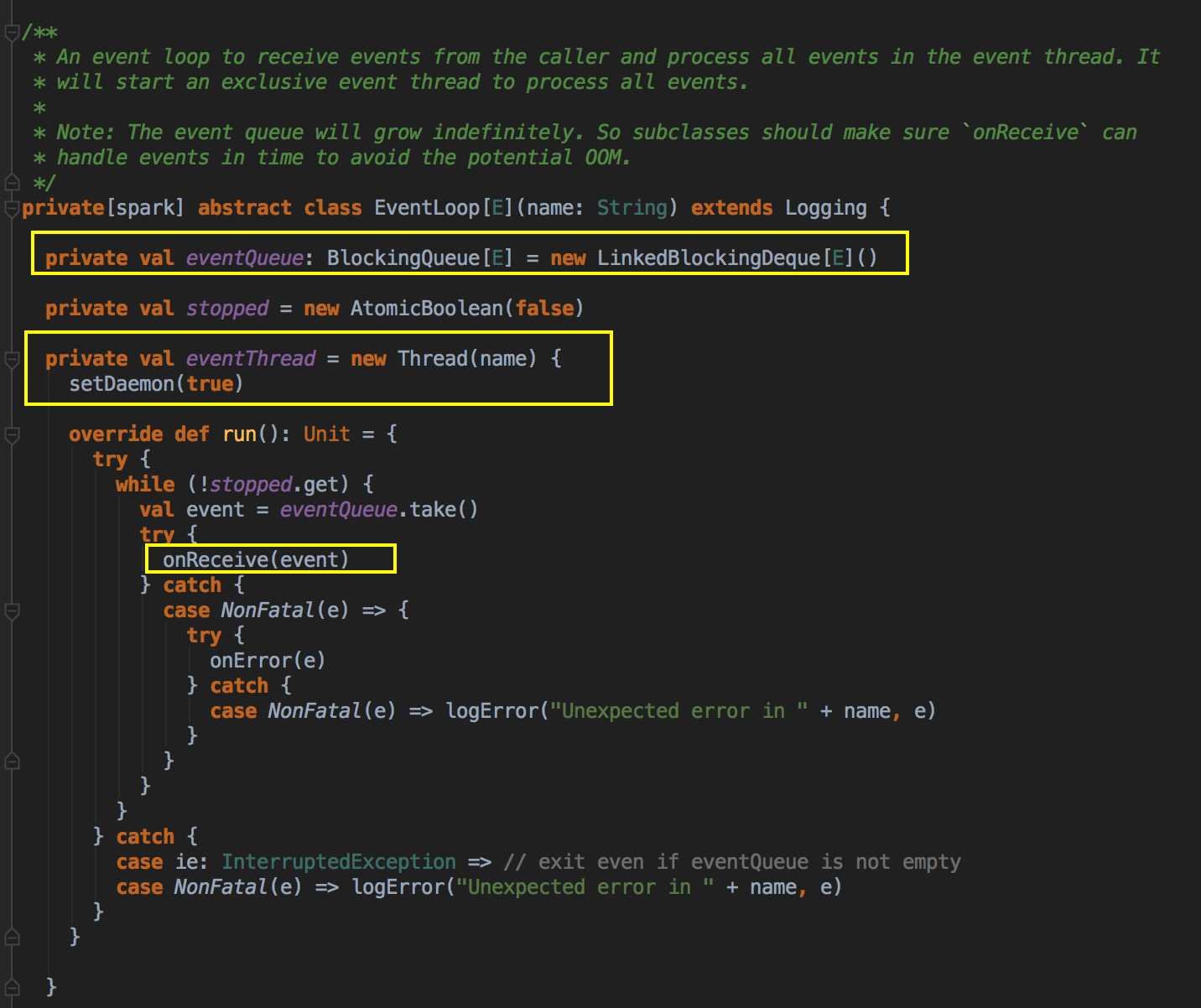
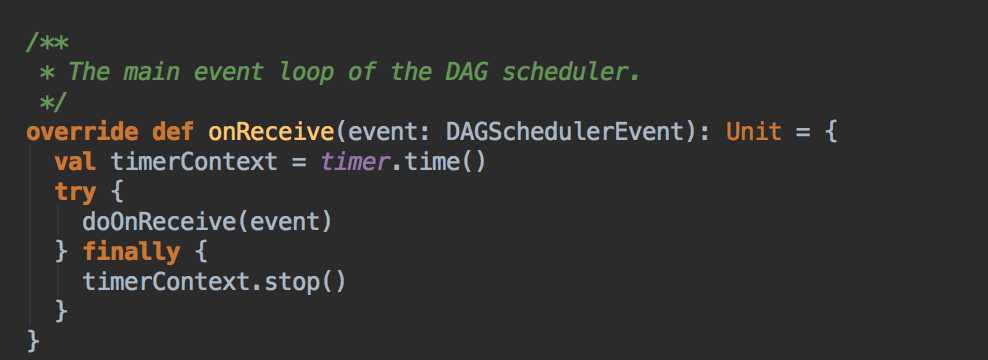
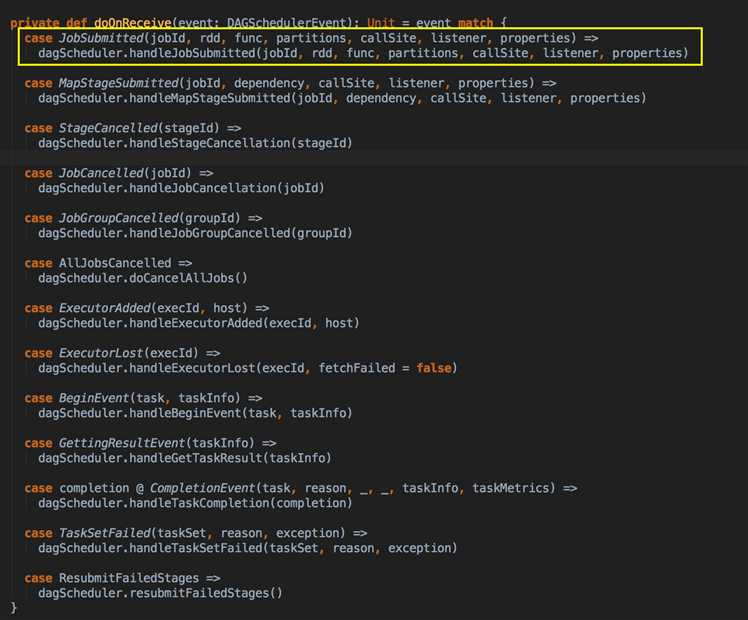
handleJobSubmitted( ) -->
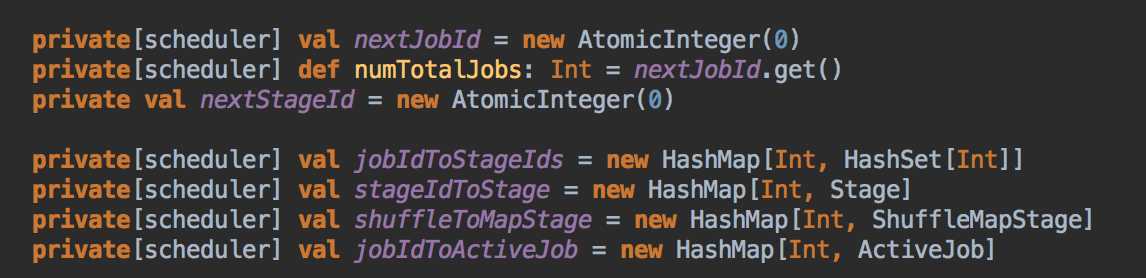
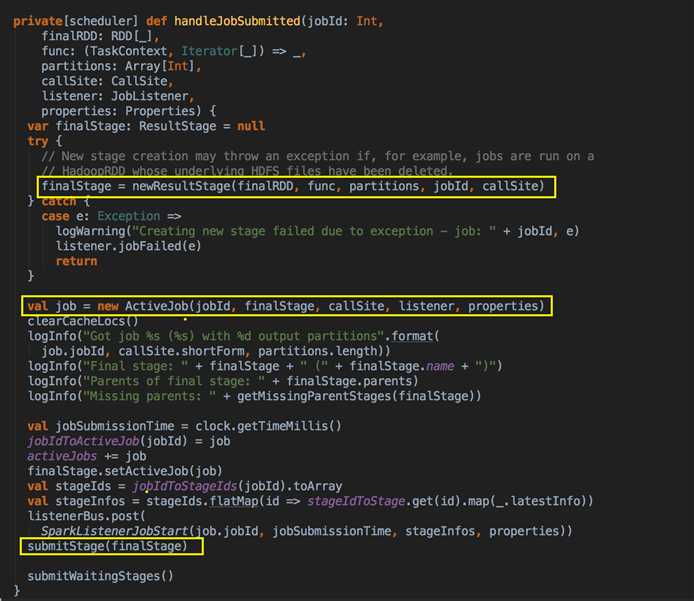
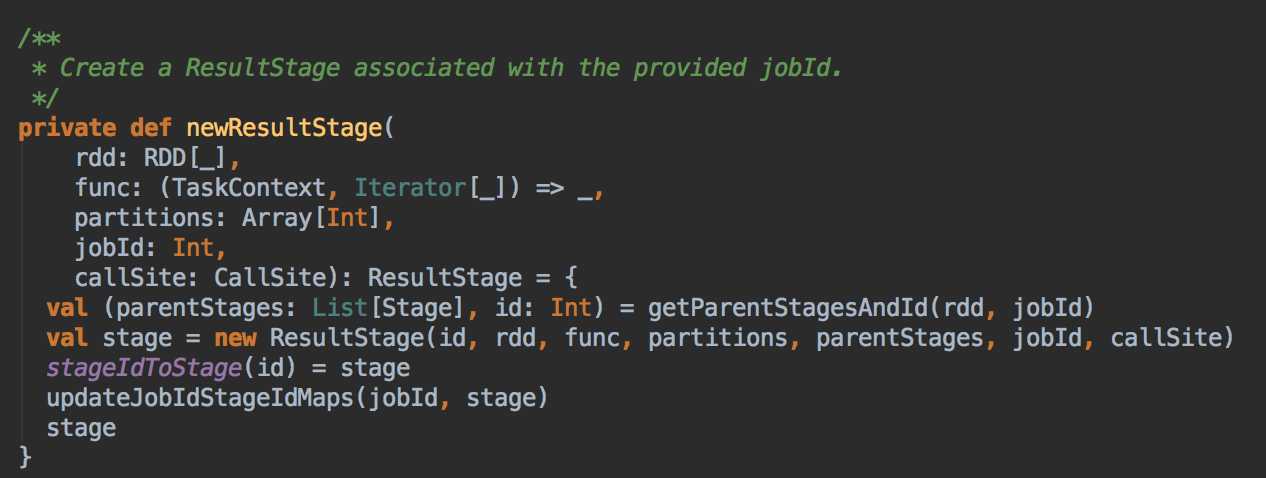
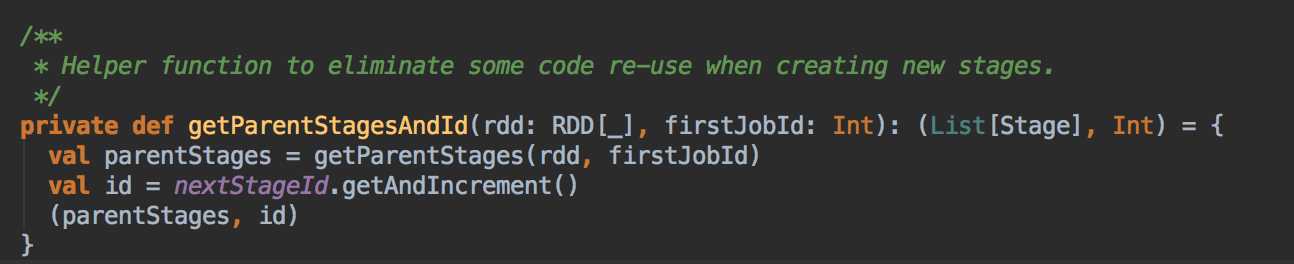
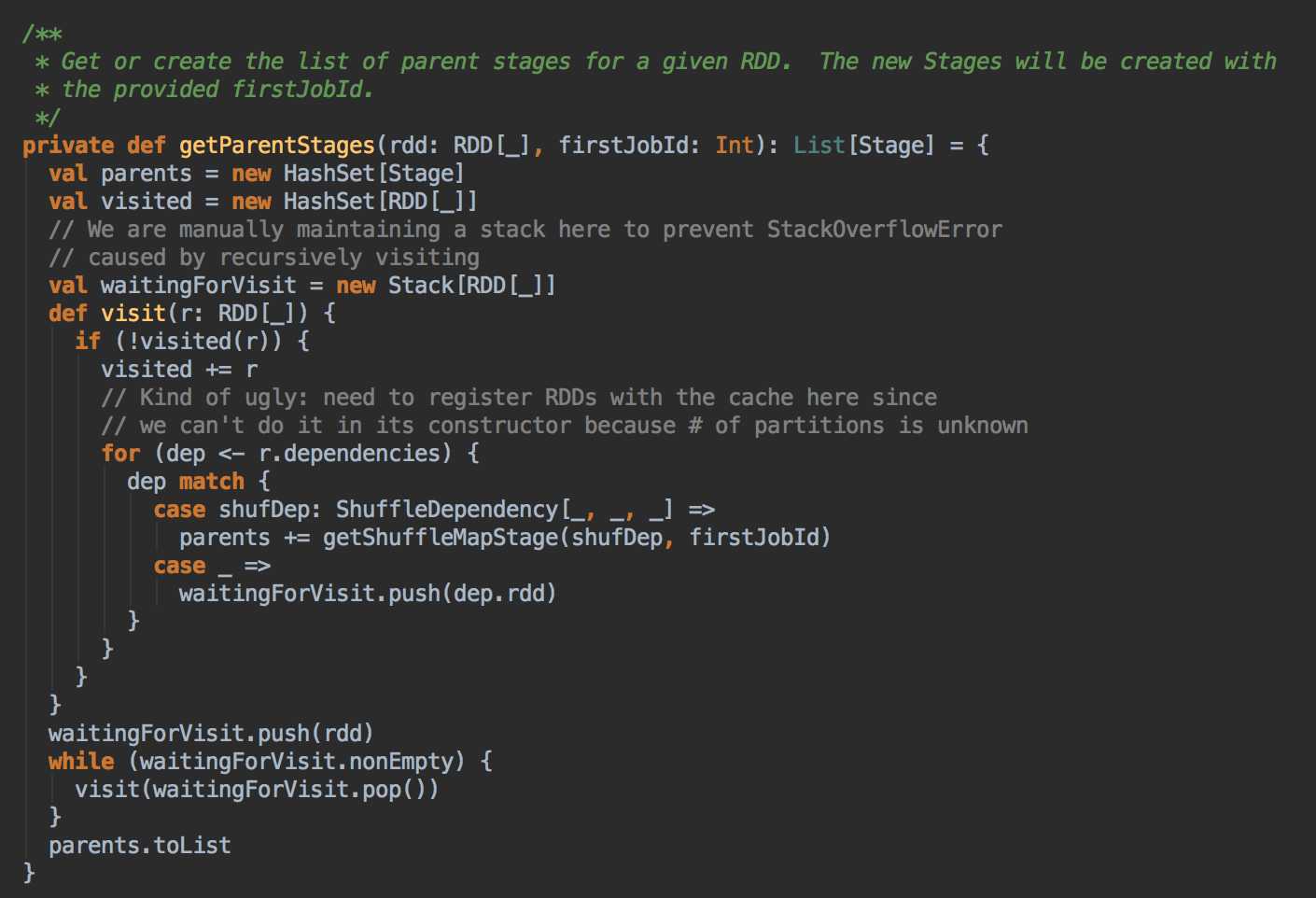
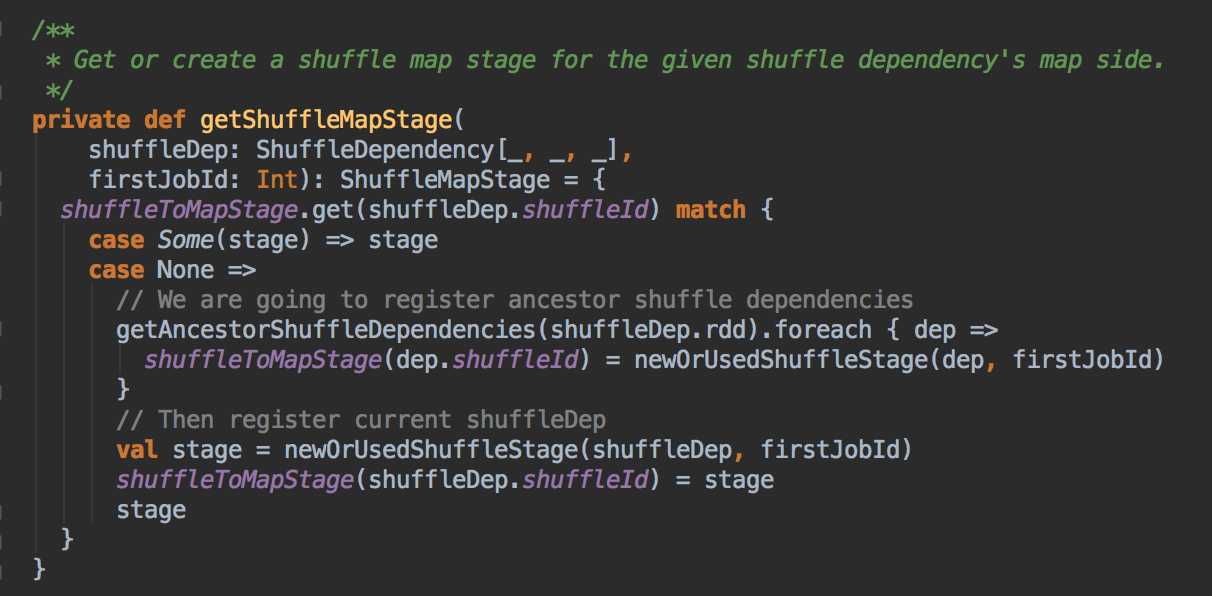
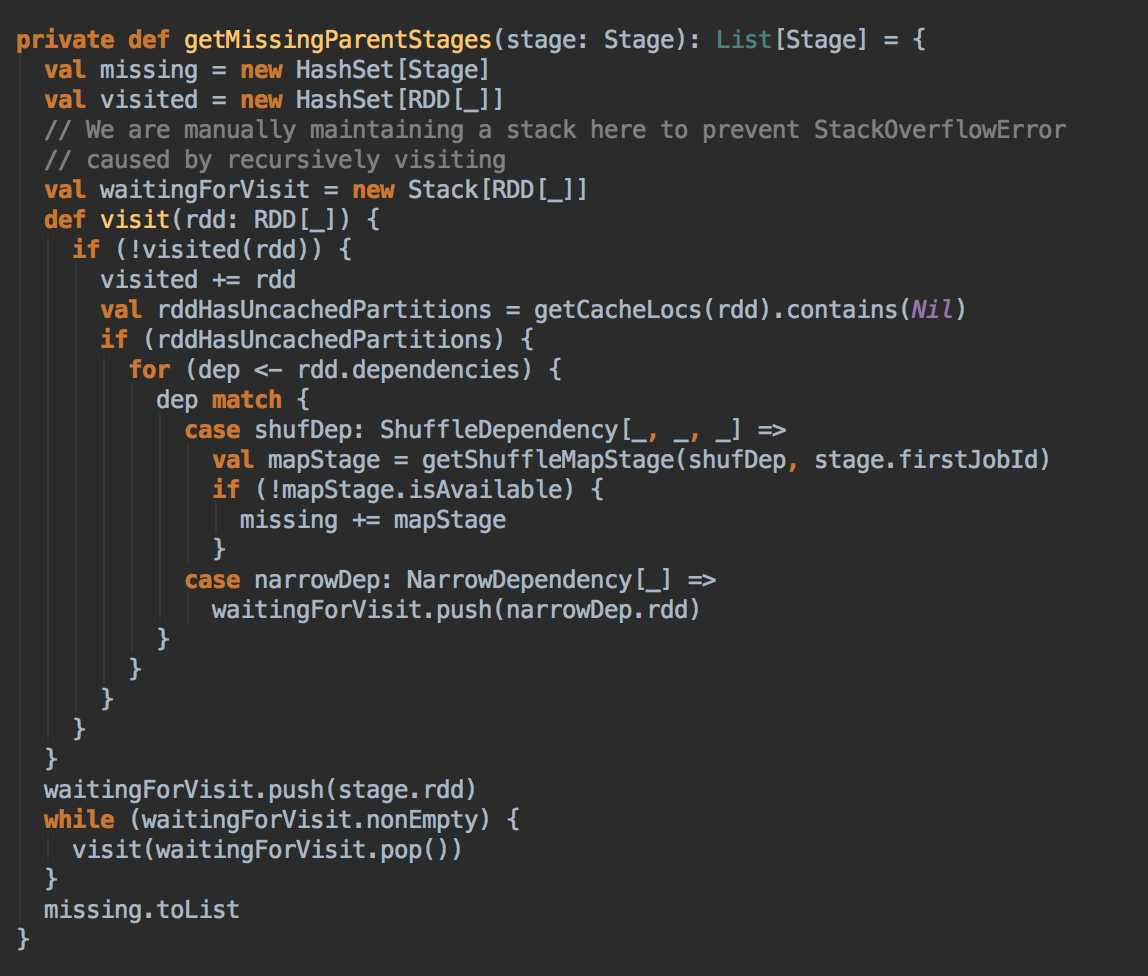
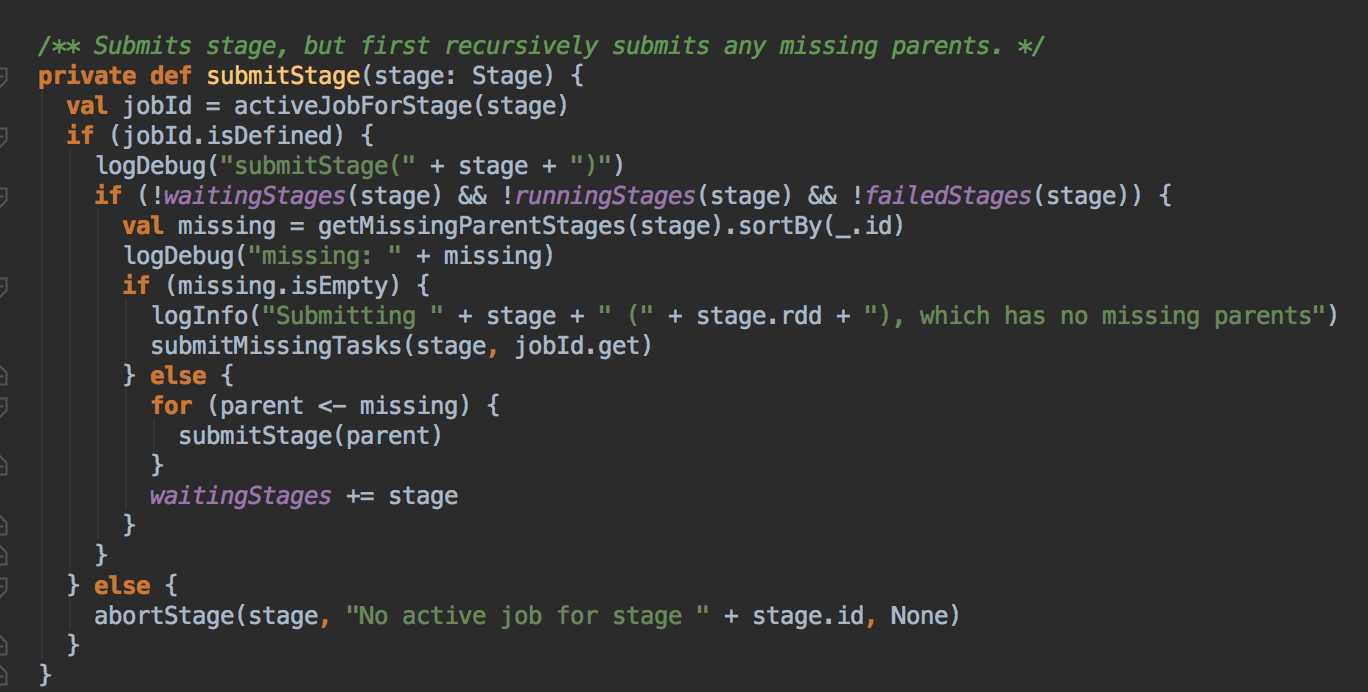
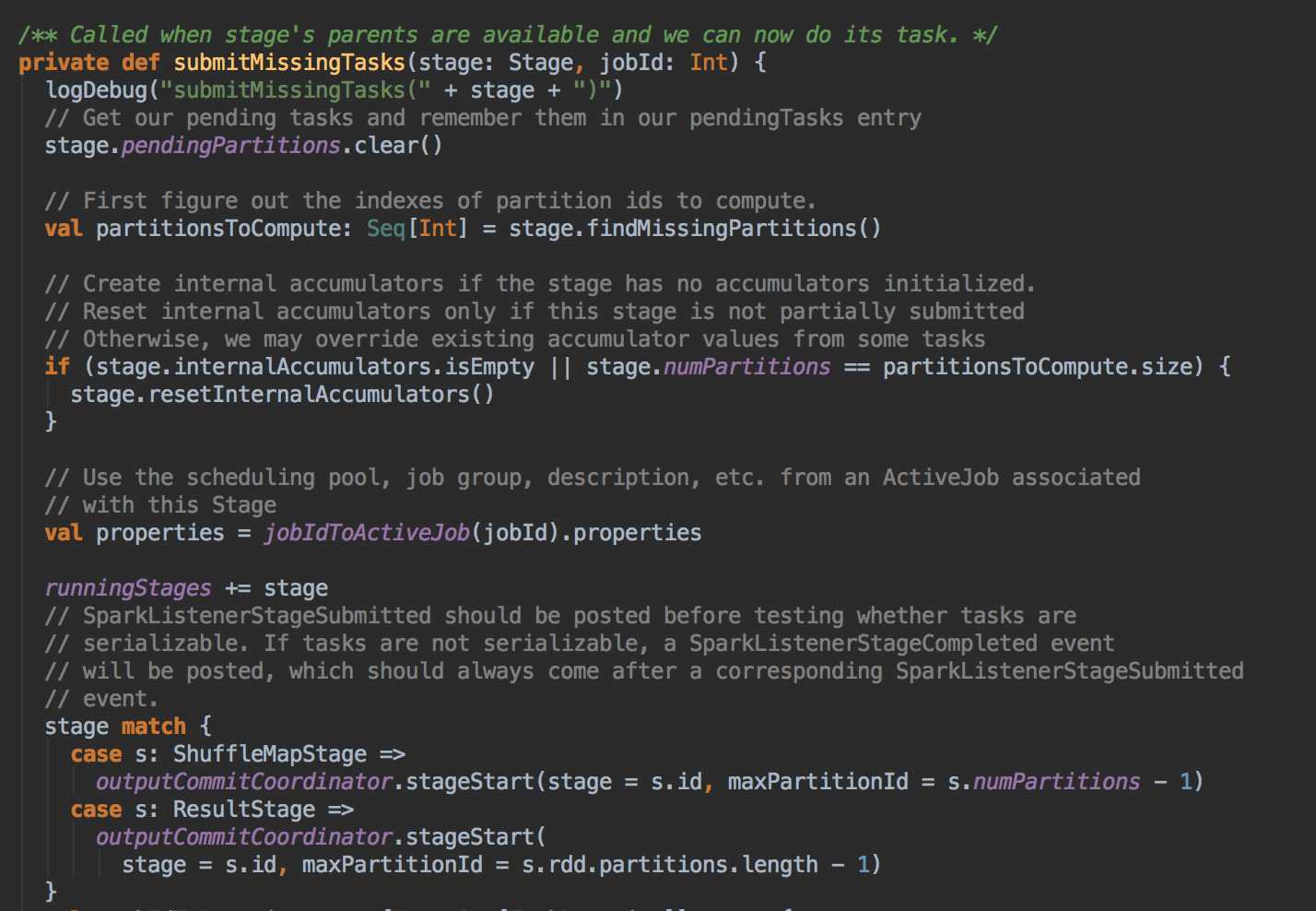
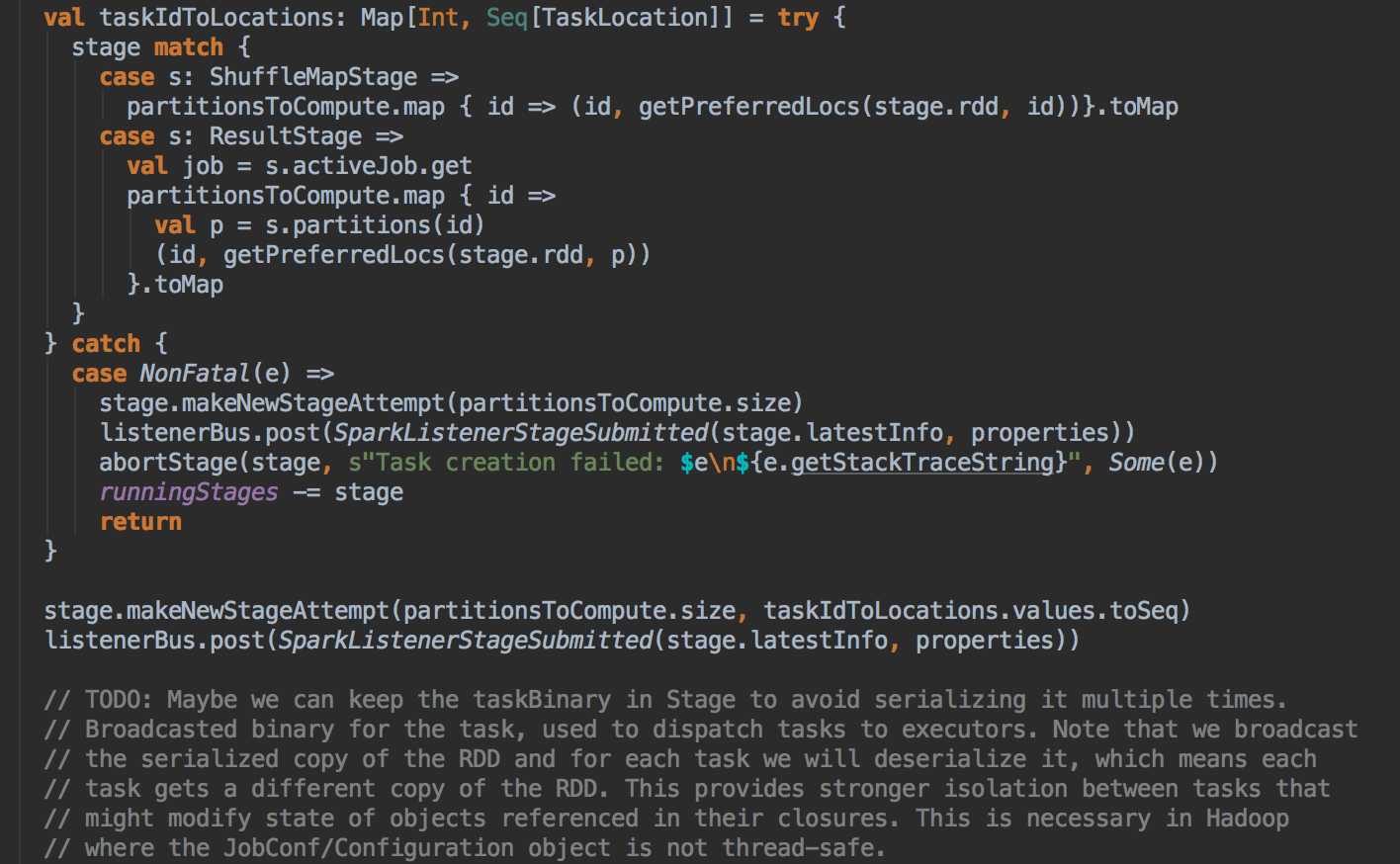
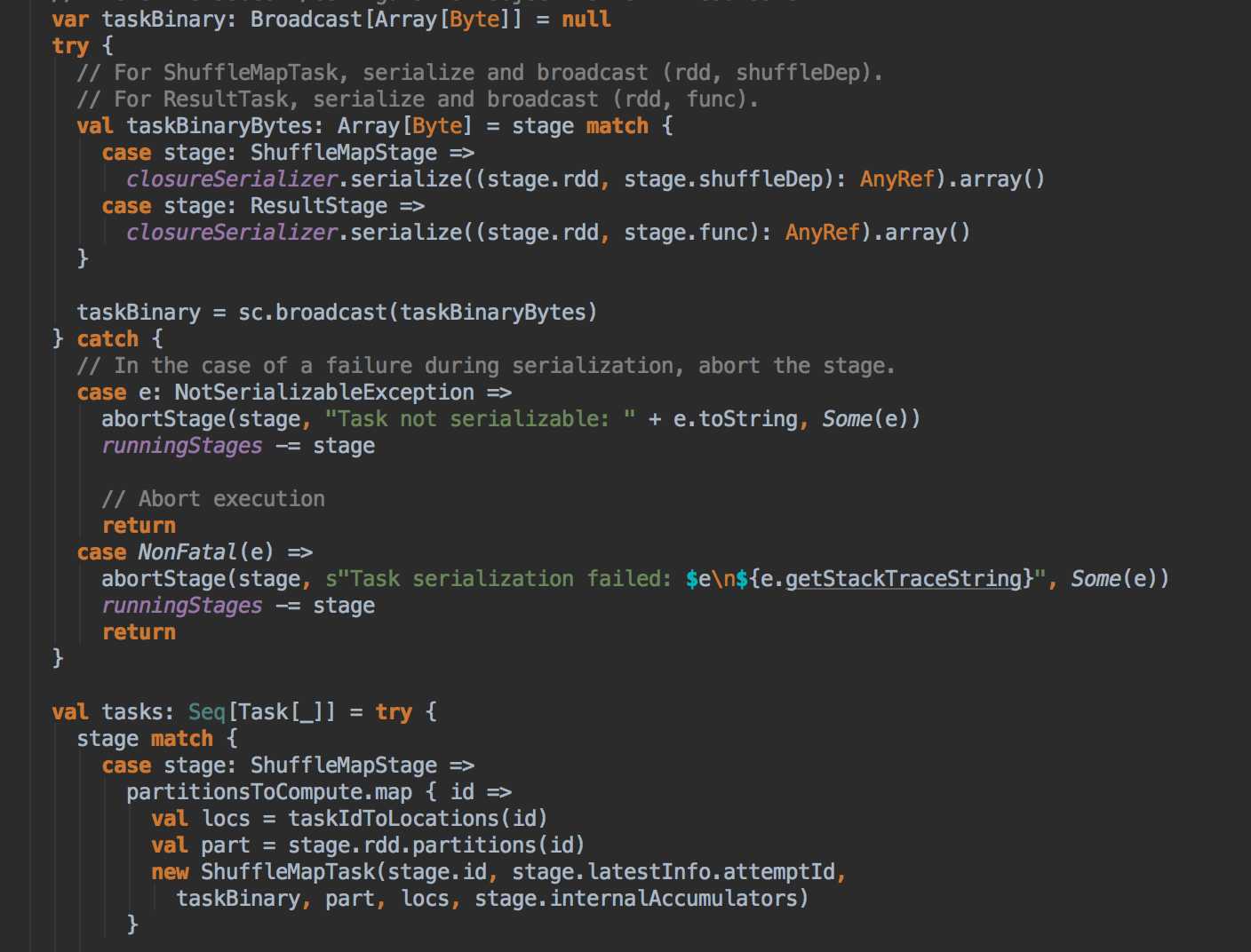
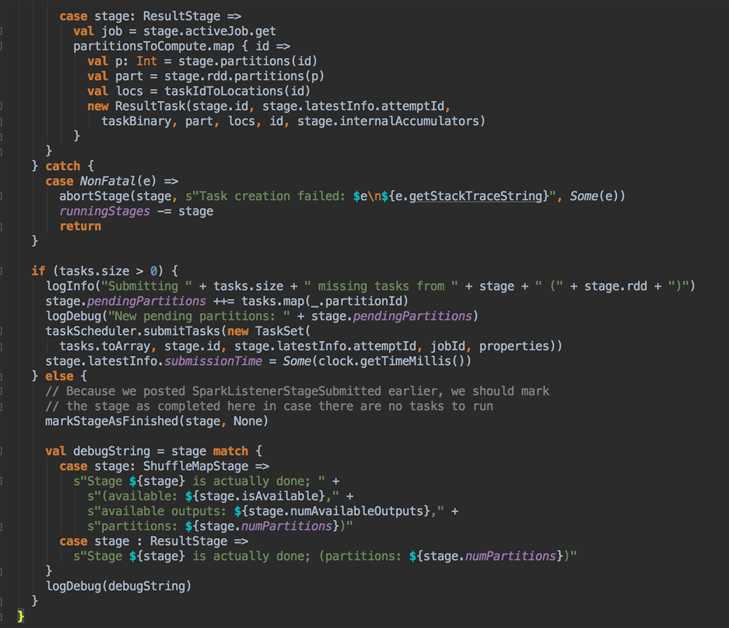

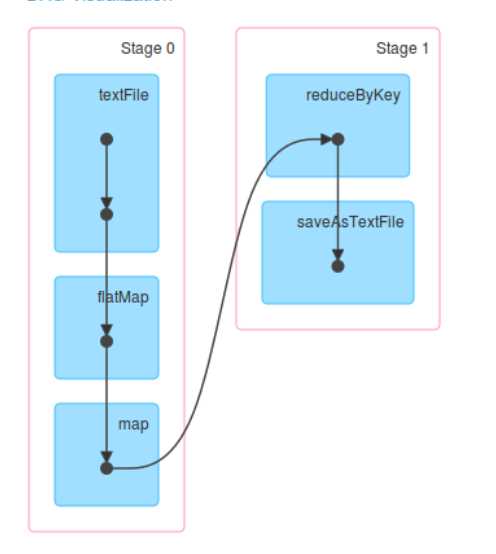
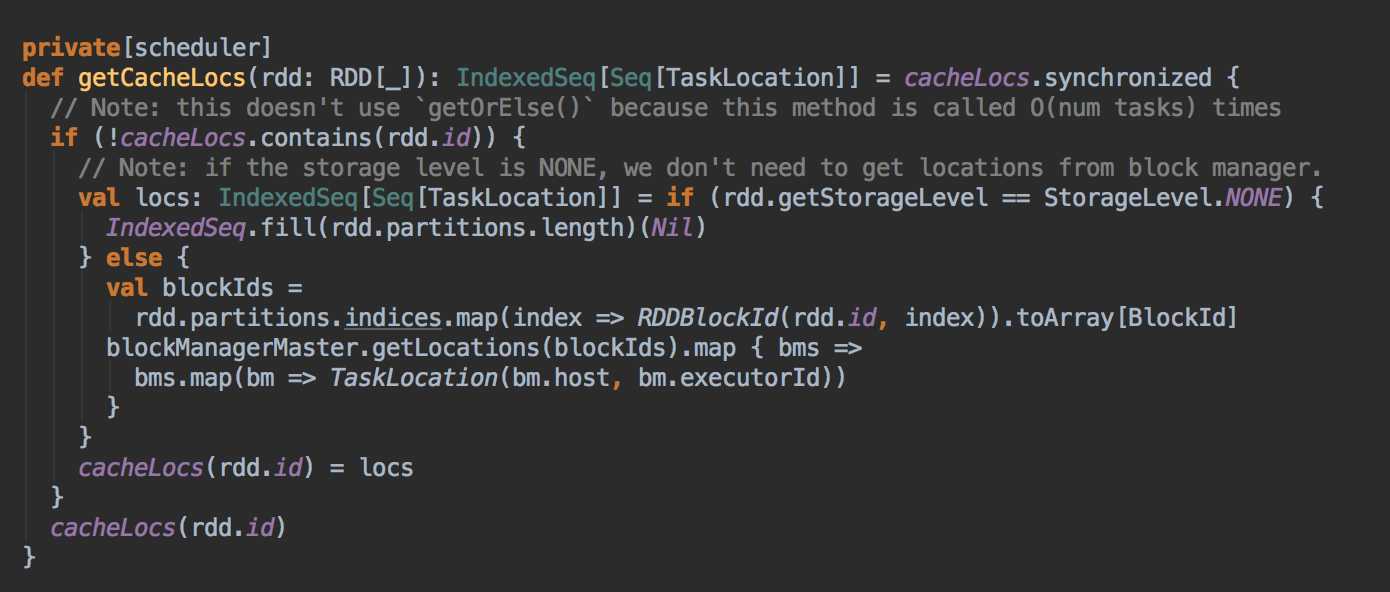
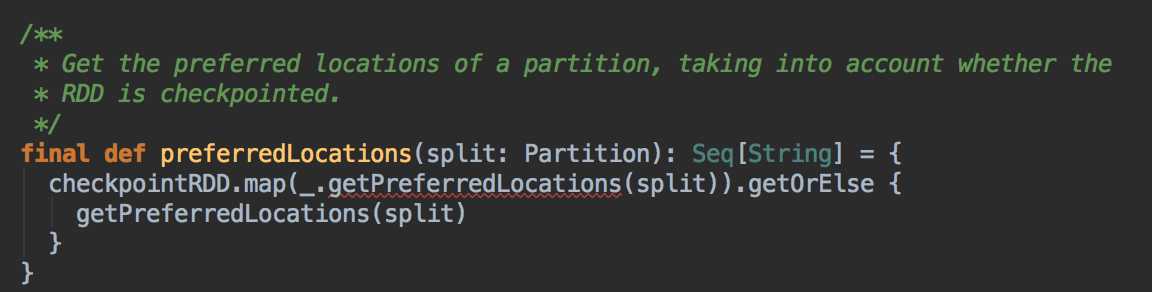
DAGScheduler 计算数据本地性的时候,巧妙的借助了RDD 自身的getPreferredLocations 中的数据,最大化的优化了效率,因为getPreferredLocations 中表明了每个Partition 的数据本地性,虽然当前Partition 可能被persists 或者是checkpoint,但是persists 或者是checkpoint默认情况下肯定是和getPreferredLocations 中的数据本地性是一致的,所以这就更大的优化了Task 的数据本地性算法的显现和效率的优化
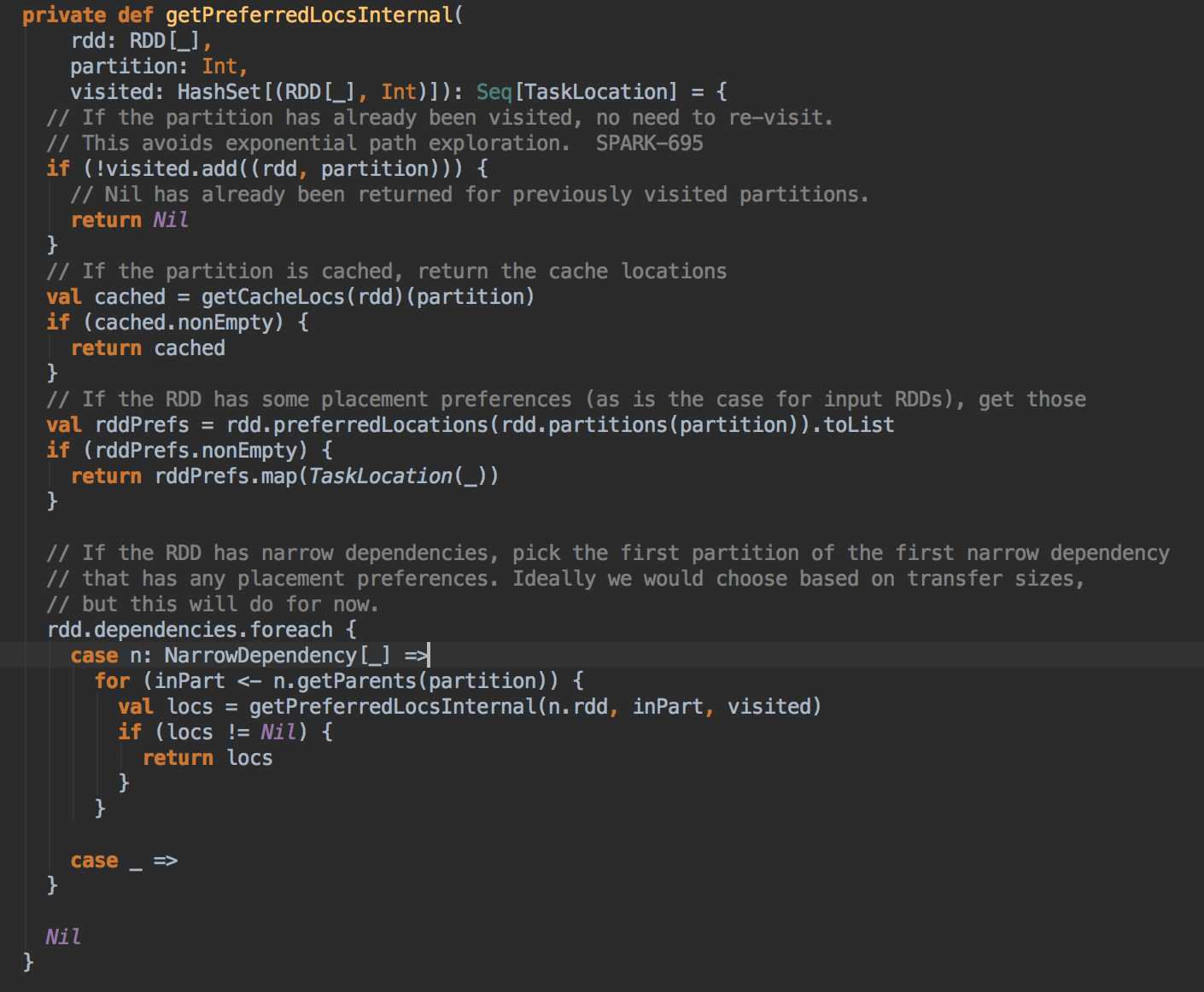
资料来源来至 DT大数据梦工厂 大数据传奇行动 第34课:Stage划分和Task最佳位置算法源码彻底解密
[Spark传奇行动] 第34课:Stage划分和Task最佳位置算法源码彻底解密
标签:数据 poi 表达 分享 color handle 传奇 最大 ima
原文地址:http://www.cnblogs.com/jcchoiling/p/6438435.html