标签:管理器 border 内容 padding elements element node 语言 bottom
---------------siwuxie095
工程名:ReadXML
包名:com.siwuxie095.xml
类名:ReadXML.java
打开资源管理器,在工程 ReadXML 文件夹下,放入
一个 XML 文件:languages.xml
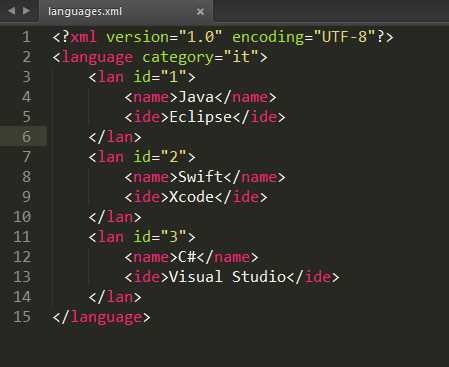
languages.xml 的内容:
工程结构目录如下:
代码:
package com.siwuxie095.xml;
import java.io.File; import java.io.IOException;
import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException;
public class ReadXML { /** * * 使用Java语言实现XML数据的解析 * DOM方式解析 * * @param args */
public static void main(String[] args) {
//创建一个 DocumentBuilderFactory 对象,通过类调用静态方法获取一个新的实例 DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
try {
//通过对象 factory 调用 newDocumentBuilder() 方法,创建一个新的 DocumentBuilder //返回值是 DocumentBuilder 类型,创建对象,接收返回值 //有异常抛出,用 try catch 捕获 DocumentBuilder builder=factory.newDocumentBuilder();
//使用 builder 来创建真正的XML文档 //使用 builder 的 parse()方法,传入文件对象,返回 Document 类型 //(这里是匿名对象,使用相对路径) //创建一个 Document 对象来接收返回值 //(注意:使用 org.w3c.dom 包中的 Document 类) //有异常抛出,用 try catch 捕获 Document document=builder.parse(new File("languages.xml"));
//文档创建完成后,开始读取 // //先读取根元素:languages,创建一个 Element 对象 //(注意:使用 org.w3c.dom 包中的 Element 类) //getDocumentElement() 获取文档元素 即 文档根元素 Element root=document.getDocumentElement(); //获取根元素的属性值 System.out.println("category="+root.getAttribute("category"));
//接着读取根元素的子集元素:lan //getElementsByTagName() 的返回值是 NodeList 类型,即 一个集合 //创建一个 NodeList对象接收返回值 NodeList list=root.getElementsByTagName("lan");
//创建for循环,循环打印 lan 内部的值 //循环次数使用 NodeList 的 getLength() 方法 for (int i = 0; i < list.getLength(); i++) { //创建一个 Element,调用list的item()方法, //传入下标i,按照循环次数获取list中的内容 //但item()的返回值是Node类型,是Element的父类 //父类转子类,需要进行强制转换 Element lan=(Element) list.item(i);
//将 for循环中的元素分隔开 System.out.println("-------------"); //获取属性值 System.out.println("id="+lan.getAttribute("id"));
//获取 lan 中的两个子节点: //name 和 ide,是两个不同的 TagName // //不建议使用下面的方法: //可以使用getElementsByTagName(),但弊端是返回的是一个集合 //两个节点即两个集合,还要从两个集合中分别取第一个值 //(因为已知一个节点只有一项) Element name=(Element) lan.getElementsByTagName("name").item(0); //获取当前节点中的文本内容(字符型数据) //System.out.println("name="+name.getTextContent());
//获取 lan 中的两个子节点,因为lan下的子节点同级,建议使用: //getChildNodes()方法,获取lan下的所有的子节点, //返回值是 NodeList 类型,创建对象接收返回值 NodeList clist=lan.getChildNodes(); for (int j = 0; j < clist.getLength(); j++) { //这里和上面不一样,如果创建Element对象并强转,会报错:类型转换错误 Node c=clist.item(j);
//如果当前的节点是Element对象,才输出 //如果不判断,当前的API在打印时会把每一行后面的空白+回车、缩进符 //当做两个新节点,即获取节点时并不是只获取可见的节点, //对于不可见的数据,同样要作为一个节点读取 if (c instanceof Element) { //获取 name、ide 节点 System.out.println(c.getNodeName()+"="+c.getTextContent()); }
}
}
} catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
} |
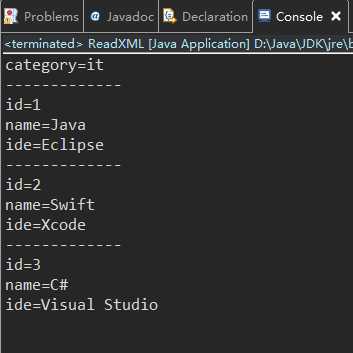
运行一览:
加了 if (c instanceof Element) 判断:
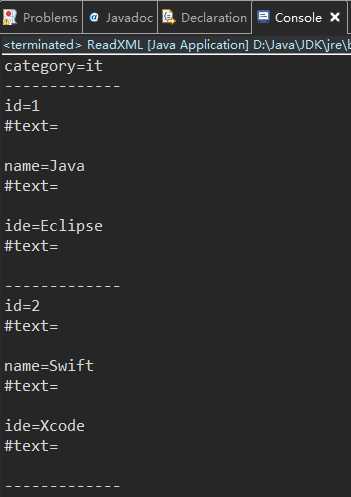
不加 if (c instanceof Element) 判断:
【made by siwuxie095】
标签:管理器 border 内容 padding elements element node 语言 bottom
原文地址:http://www.cnblogs.com/siwuxie095/p/6641652.html