标签:ade eric 名称 流程 query document ted 地址 range
lucene是Apache的一个全文检索工具,使用lucene能快速实现全文检索功能。
Lucene是一个工具包,你可以调用它的函数, 但它不能独立运行,不单独对外提供服务。
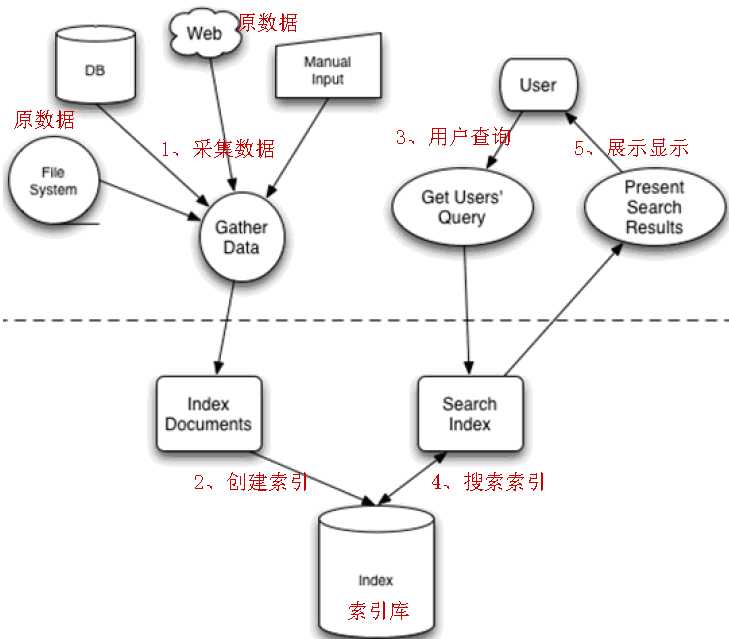
需要进行全文检索的内容的格式是丰富多样的,有视频、mp3、图片、文档等。对于这些格式不同的数据,需要采集并封装到lucene文档对象Document,形成统一的文档, 才能进行查询。
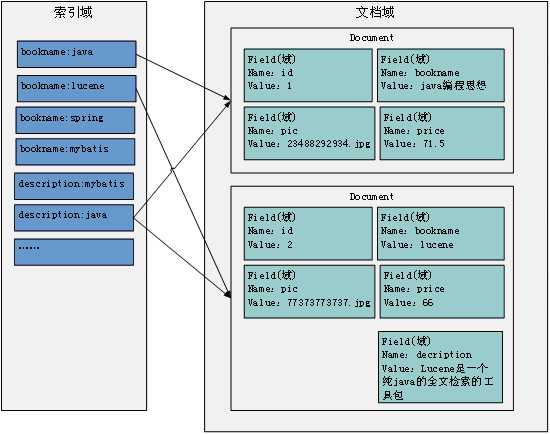
· 文档域
采集到的信息通过Document对象存储,进一步说是通过Document对象中field域来存储。比如:数据库中一条记录会存储在一个Document对象中,而数据库中一列会存储成Document中一个field域。
· 分词
按某种意义对field域中的内容进行分割。
· 过滤
将分好的词进行过滤,比如去掉标点符号、大写转小写、词型还原(复数转单数、过去式转成现在式)、停用词(this a等无意义词)过滤。
· 词Term
一个Reader字符流, 经过Lucene的分词、过滤, 生成语汇单词。 相同Field中拆分出来的相同单词对应着相同的词term。不同的Field中拆分出来的相同的单词对应不同的term。例如:图书信息里面,图书名称中的java和图书描述中的java对应着不同的term。
· 索引域
索引域内容是经过lucene分词之后存储的。索引域主要为了搜索使用。
· 倒排索引结构
传统搜索方法是先扫描文件,然后根据文件内容中匹配搜索关键字,这种方法叫顺序扫描方法,数据量大时搜索很慢。
lucene的倒排索引结构能通过部分内容(关键词)找文档。倒排索引结构也叫反向索引结构,包括索引和文档两部分。索引即词汇表,它负责匹配搜索关键字,由于索引内容量有限且采用固定优化算法,搜索速度很快,找到了索引中的term,建立索引时term与文档相关联,就能找到相关文档。
用代码说明如何创建索引更加直观
public class IndexManager { @Test public void createIndex() throws Exception { // 采集数据, 这里是从数据库 BookDao dao = new BookDaoImpl(); List<Book> list = dao.queryBooks(); // 封装到Document对象中 List<Document> docList = new ArrayList<>(); Document document = null;
for (Book book : list) { document = new Document(); // 创建field, filed类型详解见下 // 不分词、索引、存储 Field id = new StringField("id", book.getId().toString(), Store.YES); // store:如果是yes,则说明存储到文档域中 // 分词、索引、存储 Field name = new TextField("name", book.getName(), Store.YES); // 分词、索引、存储 Field price = new FloatField("price", book.getPrice(), Store.YES); // 不分词、不索引、存储 Field pic = new StoredField("pic", book.getPic()); // 分词、索引、不存储 Field description = new TextField("description", book.getDescription(), Store.NO); // 建立索引时设置boost值, 能改变查询结果优先级(default:1.0f) if (book.getId() == 4) description.setBoost(100f);
// 将field域设置到Document对象中 document.add(id); document.add(name); document.add(price); document.add(pic); document.add(description); docList.add(document); } // 定义索引目录流, 指定索引库保存地址. FSDirectory:文件系统中存储; RAMDirectory:内存中存储 File indexDir = new File("D:\\index\\"); Directory directory = FSDirectory.open(indexDir);
// 创建分词器和基本配置. StandardAnalyzer标准分词器 Analyzer analyzer = new StandardAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
// 创建IndexWriter, 需要目录流+设置 IndexWriter writer = new IndexWriter(directory, config); // 通过IndexWriter将Document写入到索引库中 for (Document doc : docList) { writer.addDocument(doc); } // 关闭writer writer.close(); } }
关于lucene中field对象的几种属性
Tokenized: 是否对该field存储的内容进行分词
分词是为了索引;而不分词不代表不索引,这里是将整个内容进行索引。
举例:
分词 : 商品名称、商品描述、商品价格
不分词 : 商品id
Indexed: 是否将分好的词进行索引
索引是为了搜索。不索引即意味着不对该field域进行搜索。
Stored: 是否将field域中的内容存储到文档域中()
存储为了在搜索结果页面显示值用的; 不存储意味着在搜索结果页面不能获取该field域的值。
举例:
存储 : 商品名称、商品价格、商品id、商品图片地址
不存储 : 商品描述。商品描述不需要在搜索页面显示。但如果需要商品描述,可以根据搜索出的商品ID去数据库中查询。
以下是lucene中常用field类的属性
| Field类 | 数据类型 |
Tokenized 是否分词 |
Indexed 是否索引 |
Stored 是否存储 |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) |
字符串 或 流 |
Y | Y | 自定义 |
| LongField(FieldName, FieldValue, Store.YES) 数字类型举例 | long | Y | Y | 自定义 |
| StringField(FieldName, FieldValue, Store.YES) | 字符串 | N | Y | 自定义 |
| StoredField(FieldName, FieldValue) |
重载方法, 支持多种类型 |
N | N | Y |
public class IndexSearch { @Test public void indexSearch() throws Exception { // 创建QueryParser // 第一参数:设置默认!搜索域的名称; 第二参数:分词器(搜索与索引的分词器需相同) QueryParser parser = new QueryParser("description", new StandardAnalyzer()); // 创建query对象 (关键字AND一定要大写), 语句指定了查询的域 Query query = parser.parse("description:java AND lucene"); doSearch(query); } private void doSearch(Query query) { try { // 创建IndexReader, 需要目录流 File indexDir = new File("D:\\index\\"); Directory directory = FSDirectory.open(indexDir); IndexReader reader = DirectoryReader.open(directory); // 创建IndexSearcher IndexSearcher searcher = new IndexSearcher(reader); // 通过searcher来搜索索引库 // 通过IndexSearcher搜索索引库. 第二参数:选出头N条记录 TopDocs topDocs = searcher.search(query, 10); // 打分文档(和排序有关). 另, topDocs.totalHits能获得匹配查询条件的总记录数 ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { // 获取文档ID int docId = scoreDoc.doc; // 通过文档ID获取文档 Document doc = searcher.doc(docId); System.out.println("商品ID:" + doc.get("id")); System.out.println("商品名称:" + doc.get("name")); System.out.println("商品价格:" + doc.get("price")); System.out.println("商品图片地址:" + doc.get("pic")); } // 关闭资源 reader.close(); } catch (IOException e) { e.printStackTrace(); } } }
需要说明的是lucene的查询语句
同SQL语句一样,lucene全文检索也有固定的语法
1.最基本的有比如:AND, OR, NOT 等
举个例子,用户想找一个description中包括java关键字和lucene关键字的文档
它对应的查询语句:description:java AND lucene
2.范围查询
域名+“:”+[最小值 TO 最大值]
例如:size:[1 TO 1000]
3.+, -, 空格
1)+cond1 +cond2:等同于and
例如:+filename:apache +content:apache
2)cond1 cond2:等同于or
例如:filename:apache content:apache
3)-cond1 cond2:必须不满足第一个条件,必须满足第二个条件
例如:-filename:apache content:apache
4)+cond1 cond2:必须满足第一个条件,忽略第二个条件
例如:+filename:apache content:apache
查询除了通过QueryParser来创建查询对象(QueryParser、MultiFieldQueryParser), 还可以用Query的子类(TermQuery、NumericRangeQuery、BooleanQuery)
QueryParser的方式可以输入lucene的查询语法、可以指定分词器; 而Query子类不能输入lucene的查询语法,不需要指定分词器
Query子类用到了词term, term是最小的lucene分析的最小的片段。
对范围查询来说, QueryParser不支持对数字范围的搜索,它支持的是字符串范围。数字范围搜索建议使用NumericRangeQuery。
public class IndexSearch { @Test public void termQuery() { // 创建TermQuery对象 Query query = new TermQuery(new Term("description", "java")); doSearch(query); } @Test public void numericRangeQuery() { // 创建NumericRangeQuery对象 // 参数:域的名称、最小值、最大值、是否包含最小值、是否包含最大值 Query query = NumericRangeQuery.newFloatRange("price", 55f, 60f, true, false); doSearch(query); } @Test public void booleanQuery() { // 创建BooleanQuery BooleanQuery query = new BooleanQuery(); // 创建TermQuery对象 Query q1 = new TermQuery(new Term("description", "lucene")); // 创建NumericRangeQuery对象 Query q2 = NumericRangeQuery.newFloatRange("price", 55f, 60f, true, false); // 组合关系代表的意思如下: // 1、MUST和MUST: 与, 交集 // 2、SHOULD与SHOULD: 或, 并集 // 3、MUST A和MUST_NOT B: 包含前者不包含后者 A-B // 4、SHOULD A与MUST B相当于MUST B, SHOULD失去作用 // 5、SHOUlD与MUST_NOT相当于MUST与MUST_NOT // 6、MUST_NOT和MUST_NOT无意义 query.add(q1, Occur.MUST_NOT); query.add(q2, Occur.MUST_NOT); doSearch(query); } @Test public void multiFieldQueryParser() throws Exception { // 创建MultiFieldQueryParser // 设置默认!搜索域(多个) String[] fields = {"name", "description"}; Analyzer analyzer = new StandardAnalyzer(); //查询也可以有分词器, 例如查询"lucene java" //搜索时设置boost值, 改变查询结果优先级 Map<String, Float> boosts = new HashMap<String, Float>(); boosts.put("name", 200f); MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, analyzer, boosts); Query query1 = parser.parse("name:lucene OR description:lucene"); Query query2 = parser.parse("lucene"); // 设置了默认搜索域, 等效于query1 doSearch(query2); } }
即索引的增删改
public class IndexManager { // 增或改 @Test public void updateIndex() throws Exception { // 创建IndexWriter Directory directory = FSDirectory.open(new File("D:\\index\\")); Analyzer analyzer = new StandardAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); IndexWriter writer = new IndexWriter(directory, config); // 创建一个新的Document Document doc = new Document(); doc.add(new TextField("name", "lisi", Store.YES)); // 更新Document. 第一个参数:指定查询条件; 第二个参数:修改后的对象 // 能查询出结果,则先删除,再添加Document对象; 没有查询出结果,则新增一个Document writer.updateDocument(new Term("name", "zhangsan"), doc); writer.close(); } // 删 @Test public void deleteIndex() throws Exception { // 创建IndexWriter Directory directory = FSDirectory.open(new File("D:\\index\\")); Analyzer analyzer = new StandardAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); IndexWriter writer = new IndexWriter(directory, config); // 先根据Term查询, 再删除 // 删除索引文档记录, 建议用唯一键删, 否则可能会删除多条记录. writer.deleteAll删除全部索引 writer.deleteDocuments(new Term("id", "1")); writer.close(); } }
标签:ade eric 名称 流程 query document ted 地址 range
原文地址:http://www.cnblogs.com/myJavaEE/p/6669941.html