标签:并且 mic 自旋 tom spin 状态 body images 返回
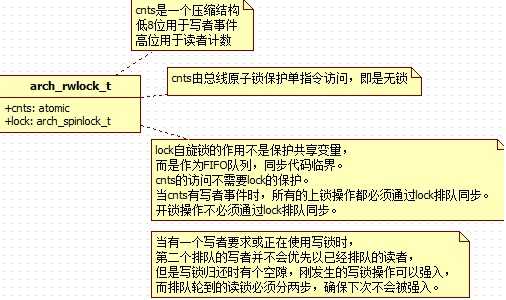
除spinlock外,linux 内核还有一个自旋锁,名为arch_rwlock_t。它的头文件是qrwlock.h,包含在spinlock.h,头文件中对它全称为"Queue read/write lock"。这个锁只使用了两个成员变量就实现了读写锁。一个spinlock,以及一个整形锁变量。而spinlock就是这个Queue。
锁的原理是,当没有写意愿或写锁使用时,任意读锁可以并发。当有写意愿或写锁使用时,一切的读锁和写锁都必须进行排队。
arch_rwlock_t的锁变量虽然只是一个整形,但是却是一个压缩的复合数据。它包含了读锁,写锁。
读锁,为锁变量的高24位。只要读锁操作成功对读锁字段加1,就可以获得读锁。
写锁,为锁变量的低8位,包含3种状态,有写意愿,写锁使用中,以及无。
arch_rwlock_t巧妙地将读锁和写锁压缩在一个整形,可以通过原子指令同时对两个锁进行原子操作。不必另外设计一锁对锁变量操作进行保护。
arch_rwlock_t还巧妙地使用了spinlock的自旋和FIFO排队特性,实现了对读写的排队。
arch_rwlock_t的读操作使用atomic_add和atomic_sub支持多个读者对读锁的修改,并且可以与写操作相容。但当上读锁一瞬后发现有写意愿和写进行,就必须归还读锁,进行排队模式。排队的读锁操作,在轮到的时候也不是一步到位就可以成功上读锁。因为这时,有可能其它CPU刚发生的写锁意愿,尽管有其它读写在排队,但这时这个刚发生写锁意愿的CPU是不被排队所约束的。在这种情况下,读锁是不可以归还的,回这会让同样的情况历史重演,使整个排队阻塞不前。所以这个轮到的排队读锁的CPU必须保持这个读锁,直到横刀插入的写锁释放后,马上通行。
| reader | rwlock | writer |
| 1. 从spinlock排队返回 | read == 0 && write state == 0 | |
| read == 0 && write state == FF | 1. 刚发起写锁操作,atomic_xchg返回的读锁字段仍为0,OK,没有读锁进行 | |
| 2. atomic_add返回,发现写锁字段不为0 | read == 1 && write state == FF | 2. 使用写锁 |
| 3. 自旋等待write state变为0 | ||
| read == 1 && write state == 0 | 3. 归还写锁。即使突然发生的写锁操作也不能横刀断入(steal),只好去排队。 | |
| 4. 马上可以读锁能行。 | ||
| 5. 释放spinlock,使spinlock排队前进。 | ||
arch_rwlock_t的读操作使用atomic_cmpxchg保证只有一个写者完整进行写锁的修改,并且操作与任意读操作不相容,即有任意读操作同时进行,修改都不被接受。当有写意愿或写锁进行时,所有的写锁操作都必须和读锁操作平等地FIFO排队等候。只有在一个写锁操作发现有读锁进行时,进入排队发出写意愿(修改锁变量的写锁字段),这时候这个写锁操作才会成为第一个排队的操作,优先于其它后继的排队的操作。后继的排队的不论读锁或写锁的操作都是平等的。
spinlock不是用来保护锁变量,而是同步临界区queue_read_lock_slowpath以及queue_write_lock_slowpath的,对有写锁操作参与这一事态,进行对锁操作的排队。
标签:并且 mic 自旋 tom spin 状态 body images 返回
原文地址:http://www.cnblogs.com/bbqzsl/p/6740633.html