标签:频率 无法 框架 存在 字符 操作码 copy 多播 foo
HTTP并不是独自运行在网上的。很多协议都会在HTTP报文的传输过程中对其数据进行管理。HTTP只关心旅程的端点(发送者和接收者),但在包含有镜像服务器、Web代理和缓存的网络世界中,HTTP报文的目的地不一定是直接可达的
重定向技术通常可以用来确定报文是否终结于某个代理、缓存或服务器集群中某台特定的服务器。重定向技术可以将报文发送到客户端没有显式请求的地方去。本文将详细介绍重定向技术以及负载均衡
由于HTTP应用程序需要可靠地执行HTTP事务,最小化时延,并且节约网络带宽,所以在现代网络中重定向是普遍存在的
出于这些原因,Web内容通常分布在很多地方。这么做是出于可靠性的考虑。这样,如果一个位置出问题了,还有其他的可用,如果客户端能去访问较近的资源,就可以更快地收到所请求的内容,以降低响应时间;将目标服务器分散,还可以减少网络拥塞。可以将重定向当作一组有助于找到“最佳”分布式内容的技术
大多数重定向部署都包含某些形式的负载均衡。也就是说,它们可以将输入报文的负载分摊到一组服务器中去。反之,因为输入报文一定会在分担负荷的服务器之间进行某种分布,所以任意形式的负载均衡都包含了重定向
从客户端向目标发送HTTP请求,目标对其进行处理的角度来看,服务器、代理、缓存和网关对客户端来说都是服务器。很多重定向技术都可用于服务器、代理、缓存和网关,因为它们具有共同的,与服务器类似的特征。其他一些重定向技术是专门为特定类型的端点设计的,没有通用性
Web服务器会根据每个IP来处理请求。将请求分摊到复制的服务器中去,就意味着应该把对某特定URL的每条请求都发送到最佳的Web服务器上去(最靠近客户端的、或负载最轻的或采用其他优化策略选择的服务器)。重定向到某台服务器就像将所有需要给汽车加油的司机都送到最近的加油站去一样
代理希望根据每个协议来处理请求。在理想情况下,某个代理附近的所有HTTP流量都应该通过这个代理传输。比如,如果某代理缓存靠近各种不同的客户端,那么理想情况下,所有请求都应流经这个代理缓存,因为代理缓存上会存储常用的文档,可以直接提供,从而避免通过更长、更昂贵的路径连接到原始服务器。重定向到代理就像从一条主要通路(无论它通往何处)上将流量分流到一条本地快捷路径上去一样
重定向的目标是尽快地将HTTP报文发送到可用的Web服务器上去。在穿过因特网的路径上,HTTP报文传输的方向会受到HTTP应用程序和报文经由的路由设备的影响
配置创建客户端报文的浏览器应用程序,使其将报文发送给代理服务器;DNS解析程序会选择用于报文寻址的IP地址。对不同物理地域的不同客户端来说,这个IP地址可能不同;报文经过网络传输时,会被划分为一些带有地址的分组,交换机和路由器会检查分组中的TCP/IP地址,并据此来确定分组的发送路线;Web服务器可以通过HTTP重定向将请求反弹给不同的Web服务器;浏览器配罝、DNS、TCP/IP路由以及HTTP都提供了重定向报文机制
[注意]有些方法,比如浏览器配置,只有在将流量重定向到代理的时候才有意义,而其他一些方法(比如DNS重定向),则可用于将流量发送给任意服务器
重写向方法包括通用重定向、代理重定向及缓存重定向等
可以通过通用重定向方法将流量重定向到不同的(可能更优的)服务器,或者通过代理来转发流量。具体来说,包括HTTP重定向、DNS重定向、任播寻址、IP MAC转发以及IP地址转发
【HTTP 重定向】
Web服务器可以将短的重定向报文发回给客户端,告诉他们去其他地方试试。有些Web站点会将HTTP重定向作为一种简单的负载均衡形式来使用。处理重定向的服务器(重定向服务器)找到可用的负载最小的内容服务器,并将浏览器重定向到那台服务器上去
对广泛分布的Web站点来说,确定“最佳”的可用服务器会更复杂一些,不仅要考虑到服务器的负载,还要考虑到浏览器和服务器之间的因特网距离。与其他一些形式的重定向相比,HTTP重定向的优点之一就是重定向服务器知道客户端的IP地址,理论上来讲,它可以做出更合理的选择
下面是HTTP重定向的工作过程
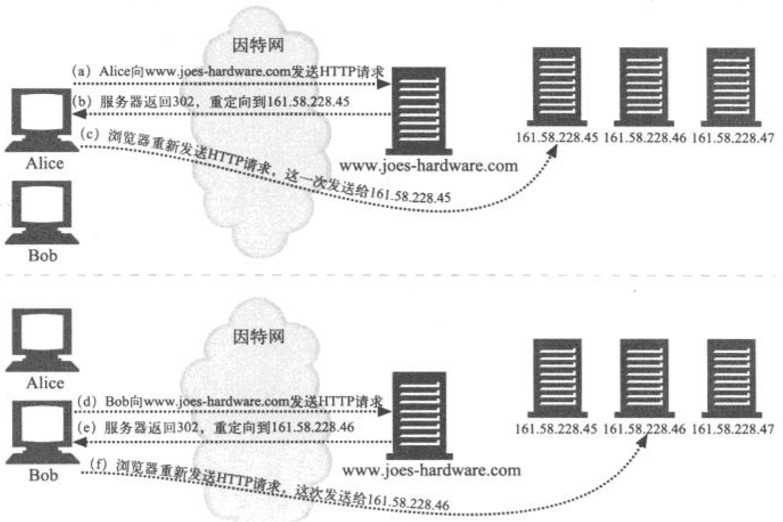
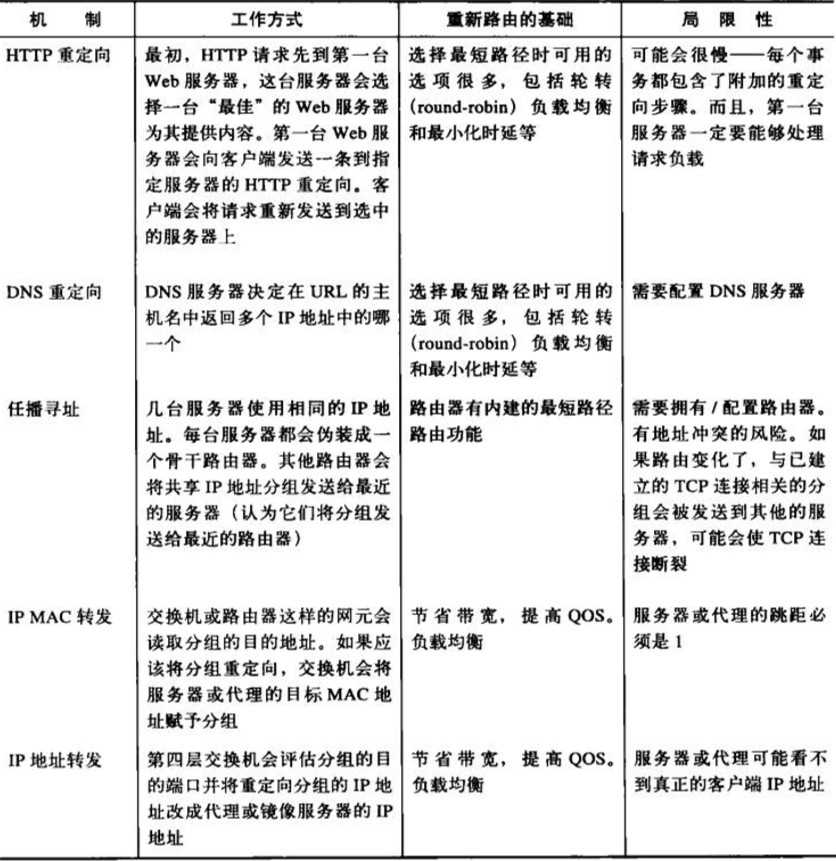
在图a中,Alice向www.joes-hardware.com发送了一条请求
GET /hammers.html HTTP/1.0 Host: www.joes-hardware.com User-Agent: Mozilla/4.51 [en] (X11; U; IRIX 6.2 IP22)
在图b中,服务器没有回送带有HTTP状态码200的Web页面主体,而是回送了一个带有HTTP状态码302的重定向报文
HTTP/1.0 302 Redirect Server: Stronghold/2.4.2 Apache/1.3.6 Location: http://161.58.228.45/hammers.html
现在,在图c中,浏览器会用重定向URL重新发送请求,这次会发送给主机161.58.228.45
GET /hammers.html HTTP/1.0 Host: 161.58.228.45 User-Agent: Mozilla/4.51 [en] (X11; U; IRIX 6.2 IP22)
另一个客户端可能会被重定向到另一台服务器上去。在图d-f中,Bob的请求会被重定向到161.58.228.46
HTTP重定向可以在服务器间导引请求,但它有以下几个缺点:需要原始服务器进行大量处理来判断要重定向到哪台服务器上去。有时,发布重定向所需的处理量几乎与提供页面本身所需的处理量一样;增加了用户时延,因为访问页面时要进行两次往返;如果重定向服务器出故障,站点就会瘫痪
由于存在这些弱点,HTTP重定向通常都会与其他一种或多种重定向技术结合使用
【DNS重定向】
每次客户端试图访问Joe的五金商店的网站时,都必须将域名www.joes-hardware.com解析为IP地址。DNS解析程序可能是客户端自己的操作系统,可能是客户端网络中的一台DNS服务器,或者是一台远距离的DNS服务器
DNS允许将几个IP地址关联到一个域中,可以配置DNS解析程序,或对其进行编程,以返回可变的IP地址。解析程序返回IP地址时所基于的原则可以很简单(轮转),也可以很复杂(比如查看几台服务器上的负载,并返回负载最轻的服务器的IP地址)
在下图中,Joe为www.joes-hardware.com运行了4台服务器。DNS服务器要决定为www.joes-hardware.com返回4个IP地址中的哪一个。最简单的DNS决策算法就是轮转
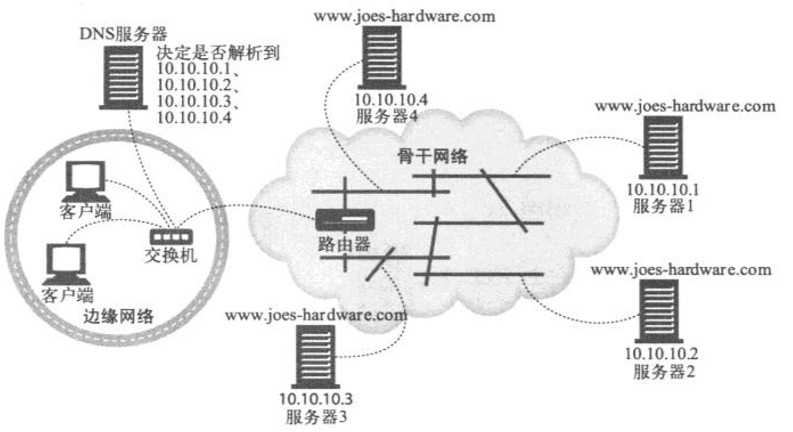
1、DNS轮转
DNS轮转是最常见的重定向技术之一也是最简单的重定向技术之一。DNS轮转使用了DNS主机名解析中的一项特性,在Web服务器集群中平衡负载。这是一种单纯的负载均衡策略,没有考虑任何与客户端和服务器的相对位置,或者服务器当前负载有关的因素
我们来看看CNN.com实际上都做了些什么。我们用Unix中的工具nslookup来查找与CNN.com相关的IP地址。下面给出了结果

% nslookup www.cnn.com Name: cnn.com Addresses: 207.25.71.9, 207.25.71.12, 207.25.71.20, 207.25.71.22, 207.25.71.23, 207.25.71.24, 207.25.71.25, 207.25.71.26, 207.25.71.27, 207.25.71.28, 207.25.71.29, 207.25.71.30, 207.25.71.82, 207.25.71.199, 207.25.71.245, 207.25.71.246 Aliases: www.cnn.com
网站www.cnn.com实际上是20个不同的IP地址组成的集群。每个IP地址通常都意味着一台不同的物理服务器
2、多个地址及轮转地址的循环
大多数DNS客户端只会使用多地址集中的第一个地址。为了均衡负载,大多数DNS服务器都会在每次完成查询之后对地址进行轮转。这种地址轮转通常称作DNS轮转
例如,对www.crni.com进行三次连续的DNS查找可能会返回下面给出的IP地址轮转列表
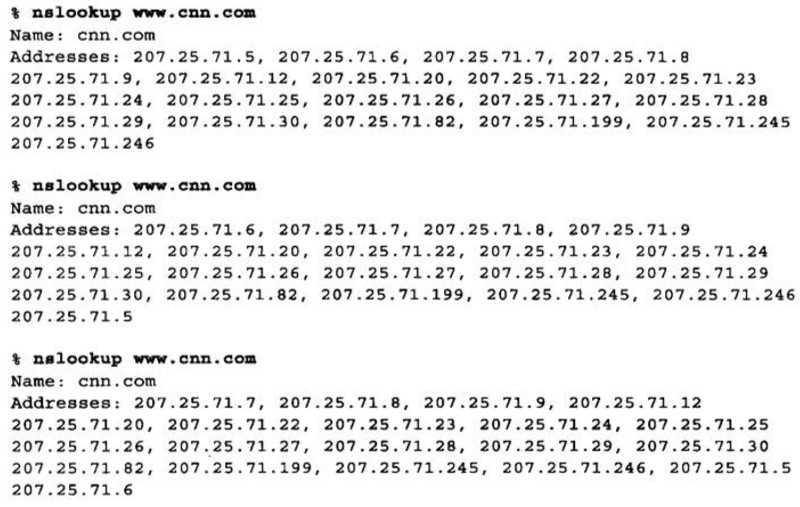
第一次DNS查找时的第一个地址为207.25.71.5;第二次DNS查找时的第一个地址为207.25.71.6;第三次DNS查找时的第一个地址为207.25.71.7
3、用来平衡负载的DNS轮转
由于大多数DNS客户端只使用第一个地址,所以DNS轮转可以在多台服务器间提供负载均衡。如果DNS没有对地址进行轮转,大部分客户端就总是会将负载发送给第一台服务器
下图说明了DNS轮转循环是如何平衡负载的
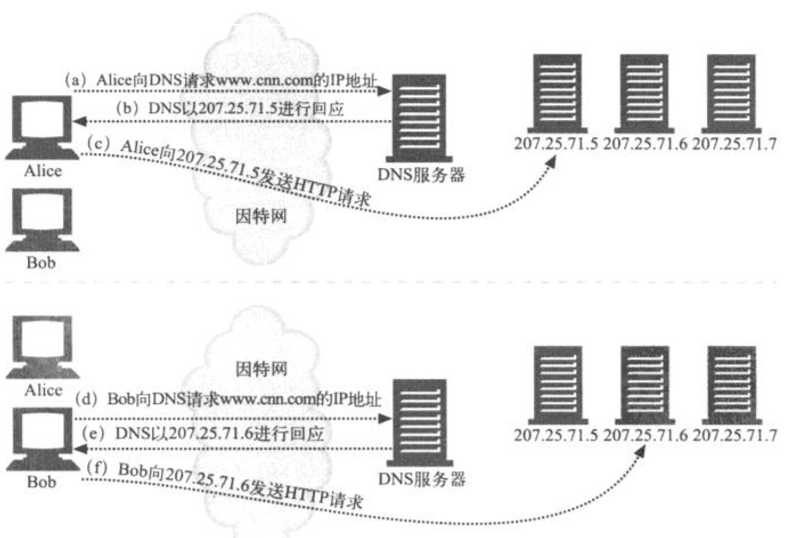
Alice试图连接www.cnn.com时,会用DNS查找IP地址,得到207.25.71.5作 为第一个1P地址。在图c中,Alice连接到Web服务器207.25.71.5
Bob随后试图连接www.cnn.com时,也会用DNS查找IP地址,但由于地址列表在Alice上次请求的基础上轮转了一个位置,所以他会得到一个不同的结果。Bob得到207.25.71.6作为第一个IP地址,在图f中它连接到了这台服务器上
4、 DNS缓存带来的影响
DNS对服务器的每次查询都会得到不同的服务器地址序列,所以DNS地址轮转会将负载分摊。但是这种负载均衡并不完美,因为DNS查找的结果可能会被记住,并被各种应用程序、操作系统和一些简易的子DNS服务器重用。很多Web浏览器都会对主机进行DNS查找,然后一次次地使用相同的地址,以减少DNS查找的开销,而且有些服务器也更愿意保持与同一台客户端的联系。另外,很多操作系统都会自动进行DNS查找,并将结果缓存,但并不会对地址进行轮转。因此,DNS轮转通常都不会平衡单个客户端的负载——一个客户端通常会在很长时间内连接到一台服务器上
尽管DNS没有对单个客户端的事务进行跨服务器副本的处理,但在分散多个客户端的总负荷方面它做得相当好。只要有大量具有相同需求的客户端,就可以将负载合理地分散到各个服务器上去
5、其他基于DNS的重定向算法
前面讨论了DNS是如何对每条请求进行地址列表轮转的。但是,有些增强的DNS服务器会使用其他一些技术来选择地址的顺序
a、负载均衡算法
有些DNS服务器会跟踪Web服务器上的负载,将负载最轻的Web服务器放在列表的最前面
b、邻接路由算法
Web服务器集群在地理上分散时,DNS服务器会尝试着将用户导向最近的Web 服务器
c、故障屏蔽算法
DNS服务器可以监视网络的状况,并将请求绕过出现服务中断或其他故障的 地方
通常,运行复杂服务器跟踪算法的DNS服务器就是在内容提供者控制之下的一个权威服务器
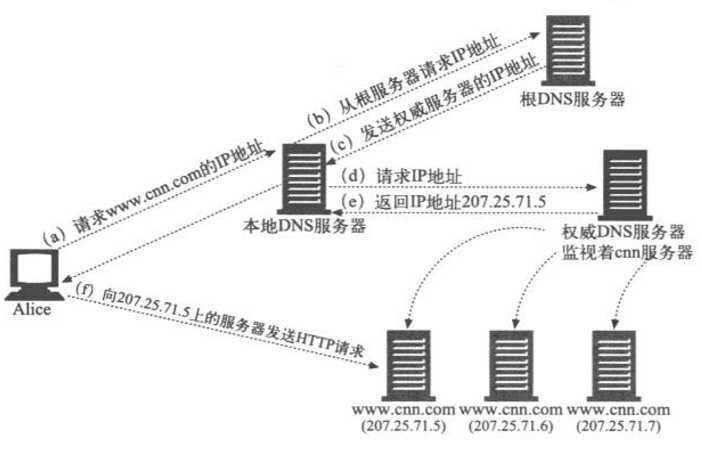
有一些分布式主机服务会使用这个DNS重定向模型。对于那些要查找附近服务器的服务来说,这个模型的一个缺点就是,权威DNS服务器只能用本地DNS服务器的IP地址,而不能用客户端的IP地址来做决定
【任播寻址】
在任播寻址中,几个地理上分散的Web服务器拥有完全相同的IP地址,而且会通过骨干路由器的“最短路径”路由功能将客户端的请求发送给离它最近的服务器
要使这种方法工作,每台服务器都要向邻近的骨干路由器广告,表明自己是一台路由器。Web服务器会通过路由器通信协议与其邻近的骨干路由器通信。骨干路由器收到发送给任播地址的分组时,会(像平常一样)寻找接受那个IP地址的最近的 “路由器”。由于服务器是将自己作为那个地址的路由器广告出去的,所以骨干路由器会将分组发送给服务器
下图中,三台服务器为同一个IP地址10.10.10.1服务。洛杉矶(LA)服务器将此地址广告给LA路由器,纽约(NY)服务器同样将此地址广告给NY路由器,以此类推。服务器会通过路由器协议与路由器进行通信。路由器会将目标为10.10.10.1的客户端请求自动地转发到广告这个地址的最近的服务器上去。对IP地址10.10.10.1的请求会被转发给服务器3
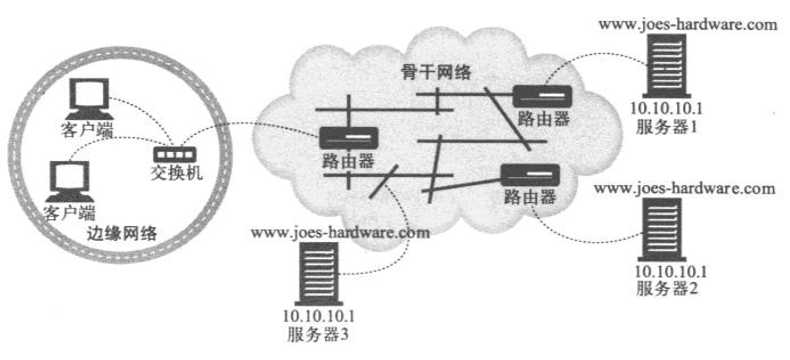
任播寻址仍然是项实验性技术。要使用分布式任播技术,服务器就必须“使用路由器语言”,而且路由器必须能够处理可能出现的地址冲突,因为因特网地址基本上都是假定一台服务器只有一个地址的。(如果没有正确地实现,可能会造成很严重的 “路由泄露”问题。)分布式任播是一种新兴技术,可以为那些自己控制骨干网络的内容提供商提供一种解决方案
【IP MAC转发】
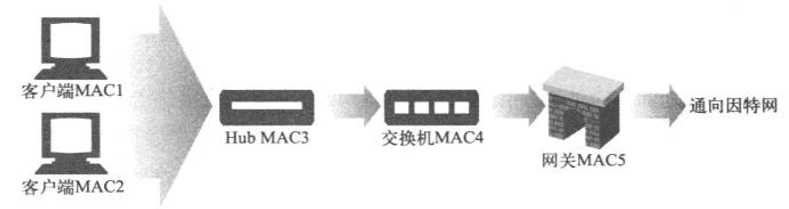
在以太网中,HTTP报文都是以携带地址的数据分组的形式发送的。每个分组都有一个第四层地址,由源IP地址、目的IP地址以及TCP端口号组成,它是第四层设备所关注的地址。每个分组还有一个第二层地址,MAC(Media Access Control,媒体访问控制)地址,这是第二层设备(通常是交换机和Hub)所关注的地址。第二层设备的任务是接收具有特定输入MAC地址的分组,然后将其转发到特定的输出MAC地址上去
比如,下图交换机的程序会将来自MAC地址MAC3的所有流量都发送到MAC地址MAC4上去
第四层交换机能够检测出第四层地址(IP地址和TCP端口号),并据此来选择路由。比如,一台第四层交换机可以将所有目的为端口80的Web流量都发送到某个代理上去。在下图中,编写交换机程序,将MAC3上所有端口80的流量都转发到MAC6(代理缓存)上去。MAC3上所有其他流量都会被转发到MAC5上去
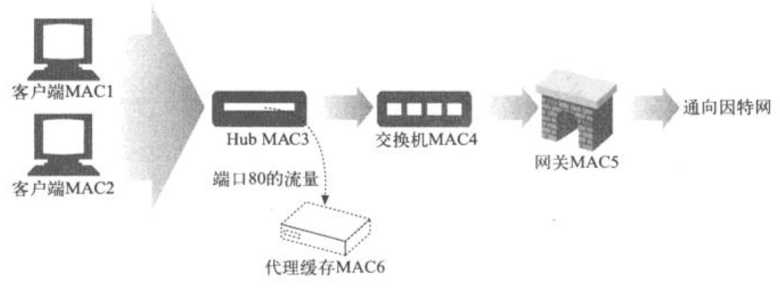
通常,如果缓存中有所请求的HTTP内容,而且是新鲜的,那么就由代理缓存来提供内容。否则,代理缓存就会代表客户端向此内容的原始服务器发送一条HTTP请求。交换机会将端口80的请求从代理(MAC6)发送给因特网网关(MAC5)
支持MAC转发的第四层交换机通常会将请求转发给几个代理缓存,并在它们之间平衡负载。类似地,也可以将HTTP流量转发给备用HTTP服务器。因为MAC地址转发只是点对点的,所以服务器或代理只能位于离交换机一跳远的地方
【IP地址转发】
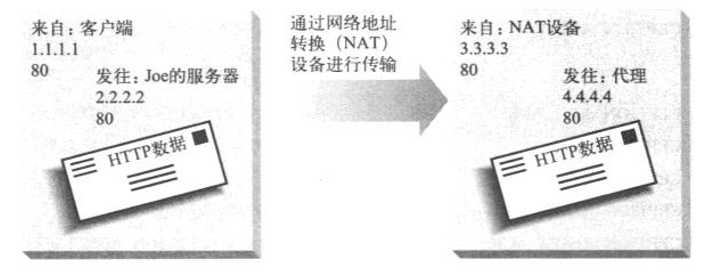
在IP地址转发中,交换机或其他第四层设备会检测输入分组中的TCP/IP地址,并通过修改目的IP地址(不是目的MAC地址),对分组进行相应的转发。与MAC转发相比,这么做的优点是目标服务器不需要位于一跳远的地方;只需要位于交换机的上游就行了,而且通常第三层的端到端因特网路由都会将分组传送到正确的地方。这种类型的转发也被称为NAT(Network Address Translation,网络地址转换)
但还有一个问题,就是对称路由。从客户端接受输入TCP连接的交换机管理着连接,交换机必须通过那条TCP连接将响应回送给客户端。这样,所有来自目标服务器或代理的响应都必须返回给交换机
有以下两种方式可以控制响应的返回路径
1、将分组的源IP地址改成交换机的IP地址。通过这种方式,无论交换机和服务器之间采用何种网络配置,响应分组都会被发送给交换机。这种方式被称为完全NAT(full NAT),其中的IP转发设备会对目的IP地址和源IP地址都进行转换
这样做的缺点是服务器不知道客户端的IP地址,那种需要认证和计费的Web服务器无法获知客户端的IP地址
2、如果源IP地址仍然是客户端的IP地址,就要确保(从硬件的角度来看)没有从服务器到客户端的直接路由(绕过交换机的)。这种方式有时被称为半NAT(half NAT)。这种方法的优点是服务器知道客户端的IP地址,但缺点是要对客户端和服务器之间的整个网络都有某种程度的控制
【网元控制协议】
NECP(Network Element Control Protocol,网元控制协议)允许网元(NE,路由器和交换机等负责转发IP分组的设备)与服务器元素(SE,Web服务器和代理缓存等提供应用层请求的设备)进行交互。NECP并未显式提供对负载均衡的支持,它只是为SE提供了一种发送负载均衡信息给NE的方式,这样NE就可以在它认为合适的情况下进行负载均衡了。与WCCP一样,NECP也提供了几种转发分组的方式:MAC转发、GRE封装和NAT
NECP支持例外。SE可以决定它不能为某些特定的源IP地址提供服务,并将这些地址发送给NE。然后,NE可以将来自这些IP地址的请求转发给原始服务器
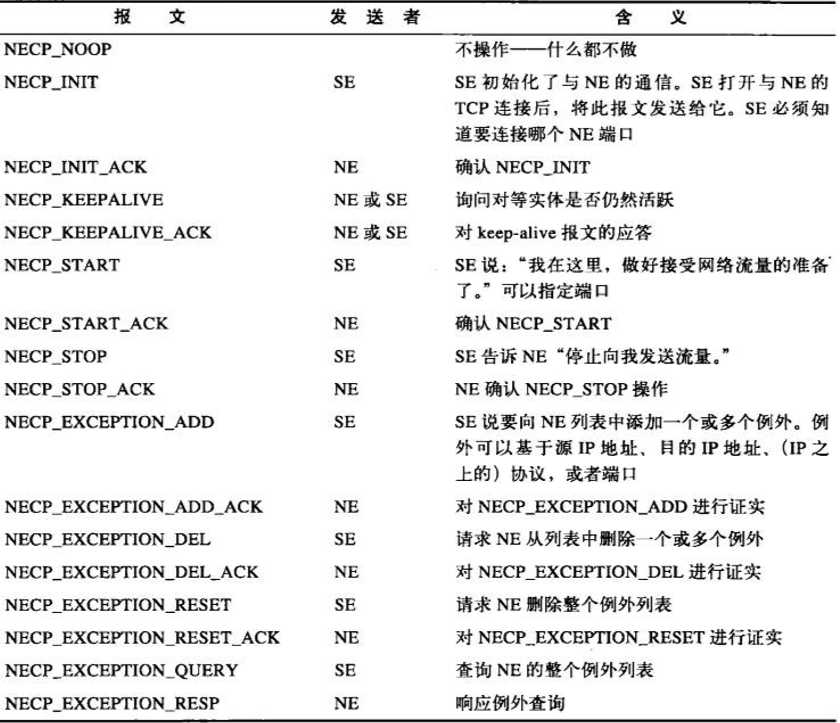
下表描述了NECP报文
到目前为止,我们已经讨论过通用的重定向方法了。出于潜在的安全考虑,内容也可能需要通过各种代理来访问,或者网络中可能有一个客户端可利用的代理缓存,因为获取已缓存的内容很可能要比直接连接到原始服务器快得多
但Web浏览器客户端怎么才会知道要连接到某个代理上去呢?可以用3种方法来判断:显式浏览器配置、动态自动配置以及透明拦截
代理可以顺次将客户端请求重定向到另一个代理上去。比如,没有缓存此内容的代理缓存可能会选择将客户端重定向到另一个代理缓存。这样一来,响应就会来自与客户端请求资源的地址不同的另外一个地址,所以,我们还会讨论几种用于对等代理——缓存重定向的协议:ICP、CARP和HTCP
【显式浏览器配置】
大多数浏览器都可以配置为从代理服务器上获取内容——浏览器中有一个下拉菜单,用户可以在这个菜单中输入代理的名字或IP地址以及端口号。然后浏览器的所有请求都可以发送给这个代理。有些服务提供商不允许用户配置普通浏览器来使用代理,它们会要求用户下载事先配置好的浏览器。这些浏览器知道所要使用的代理的地址
显式浏览器配置有以下两个主要的缺点:
1、配置为使用代理的浏览器,即使在代理无法响应的情况下,也不会去联系原始服务器。如果代理崩溃了,或者没有正确配置浏览器,用户就会遇到连接方面的问题
2、对网络架构进行修改,并将这些修改通知给所有的终端用户都是很困难的。如果服务提供商要添加更多的代理服务器,或者使其中一些退出服务,用户都要修改浏览器代理设置
【代理自动配置】
显式配置浏览器使其联系特定的代理,这样会限制网络架构方面的变动,因为它是靠用户来介入并重新配置浏览器的。自动配置方式可以动态配置浏览器,连接到正确的代理服务器,以解决这个问题。这种方法已经实现了,被称为代理自动配 置(PAC)协议。PAC是网景公司定义的,网景公司的Navigator和微软的IE浏览器都支持此协议
PAC的基本思想是让浏览器去获取一个称为PAC的特殊文件,这个文件说明了每个URL所关联的代理。必须配置浏览器,为这个PAC文件关联一个特定的服务器。这样,浏览器每次重启的时候都可以获取这个PAC文件了
PAC文件是个JavaScript文件,其中必须定义函数:
function FindProxyForURL(url, host)
如下所示,浏览器要为请求的每条URL调用这个函数:
return_value = FindProxyForURL(url_of_request, host_in_url);
其返回值为一个字符串,用来说明浏览器应该到哪里请求这个URL。返回值可以是所关联的代理名称列表(比如,PROXY proxy1.domain.com, PROXY proxy2.domain.com),或者是字符串"DIRECT",这个字符串说明浏览器应该绕开所有的代理,直接连接原始服务器
下图给出了浏览器对PAC文件的请求以及响应此请求的操作顺序。在本例中,服务器回送了带有JavaScript程序的PAC文件。JavaScript程序中有一个FindProxyForURL函数,用来告知浏览器,如果所请求的URL的主机位于netscape.com域中,就直接与原始服务器联系,所有其他请求都连接到proxy1.joes-cache.com。浏览器会为它所请求的每个URL调用这个函数,并根据此函数返回的结果进行连接
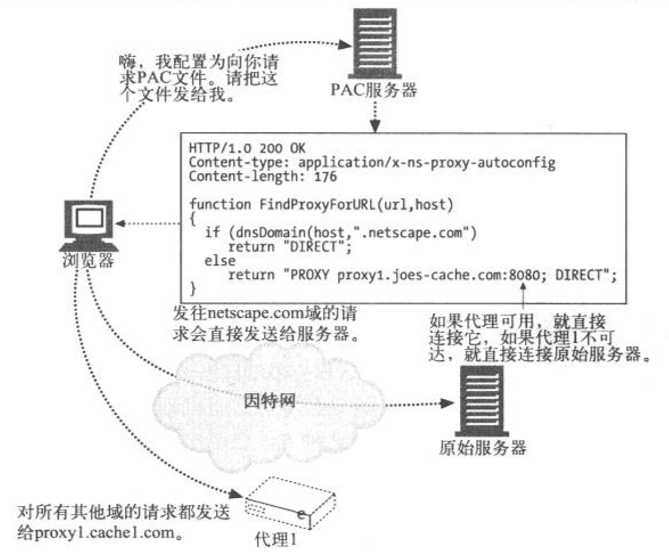
PAC协议是相当强大的:JavaScript程序可以请求浏览器根据大量与主机名相关的参数来选择代理,比如DNS地址和子网,甚至星期几或具体时间。只要服务器中的PAC文件保持更新,能反映代理位置的变化,PAC就允许浏览器根据网络结构的变化自动与合适的代理进行联系
PAC存在的主要问题是必须要对浏览器进行配置,让它知道要从哪个服务器获取PAC文件,因此它就是一个全自动配置的系统。就像那些预配置浏览器一样,现在一些主要的ISP都在使用PAC
【Web代理自动发现协议】
WPAD(Web代理自动发现协议)的目标是在不要求终端用户手工配置代理设置,
而且不依赖透明流量拦截的情况下,为Web浏览器提供一种发现并使用附近代理的方式。由于可供选择的发现协议有很多,而且不同浏览器的代理使用配置也存在差异,因此定义Web代理自动发现协议时,普通的问題会被复杂化
1、PAC文件自动发现
WPAD允许HTTP客户端定位一个PAC文件,并使用这个PAC文件找到适当的代理服务器的名字。WPAD不能直接确定代理服务器的名字,因为这样就无法使用PAC文件提供的附加功能了(负载均衡,请求路由到一组服务器上去,故障时自动转移到备用代理服务器等)
如下图所示,WPAD协议发现了PAC文件URL,这个URL也被称为配置URL(CURL)。PAC文件执行了一个JavaScript程序,这个程序会返回合适的代理服务器地址
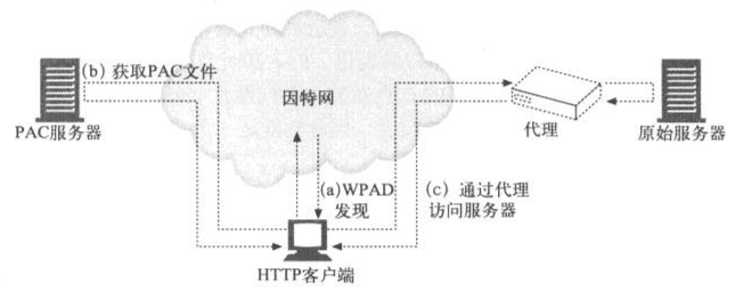
实现WPAD协议的HTTP客户端用WPAD找到PAC文件的CURL,根据这个CURL获取PAC文件(又名配置文件或CFILE),执行PAC文件来确定代理服务器,向PAC文件返回的那个代理服务器发送HTTP请求
2、WPAD算法
WPAD使用了一系列资源发现技术来确定适当的PAC文件CURL。并不是所有的组织都可以使用所有技术的,所以WPAD指定了多种发现技术。在成功获得CURL之前,WPAD客户端会一个个地尝试每种技术
当前的WPAD规范按序定义了下列技术:DHCP(动态主机配置协议)、SLP(服务定位协议)、DNS知名主机名、DNS SRV记录、DNS TXT记录中提供的服务URL
在这5种机制中,要求WPAD客户端必须支持DHCP和DNS知名主机名技术
WPAD客户端会按顺序用上面提供的发现机制发送一系列资源发现请求。客户端只会尝试它们所支持的机制。只要某次发现尝试成功了,客户端就会用得到的信息来构建PAC CURL
如果从那个CURL上成功获取到PAC文件,这个过程就结束了。如果没有,客户端就从它在预定义的资源发现请求系列里中断的地方开始恢复。如果尝试了所有的发现机制后,都没有获取到PAC文件,WPAD协议就失败了,客户端会配置为不使用代理服务器
客户端首先会尝试DHCP,然后是SLP。如果没有获取到PAC文件,客户端会继续执行那些基于DNS的机制
客户端会在DNS SRV、知名主机名和DNS TXT记录等方法中循环多次。每次都使DNS查询的QNAME变得越来越不具体。通过这种方式,客户端就可以定位出尽可能具体的配置信息,但也可能会转而使用一些不太具体的信息。每次DNS查找都会在QNAME前加上wpad,用以说明请求的资源类型
考虑主机名为johns-desktop.development.foo.com的客户端。下面是一个完整的WPAD客户端会执行的发现尝试顺序:DHCP;SLP;用QNAME=wpad.development.foo.com 进行DNS A查找;用QNAME=wpad.development.foo.com进行DNS SRV查找;用QNAME=wpad.devdopment.foo.com进行DNS TXT查找;用QNAME=wpad.foo.com进行DNS A查找;用QNAME=wpad.foo.com进行 DNS SRV 查找;用QNAME=wpad.foo.com进行DNS TXT查找
3、用DHCP进行CURL发现
要使用这种机制,就必须将CURL存储在WPAD客户端吋以查询的DHCP服务器上。WPAD客户端可以通过向DHCP服务器发送DHCP查询来获取CURL。(如果DHCP服务器中配置了这种信息),就可以在DHCP可选代码252中获取CURL。所有WPAD客户端实现都必须支持DHCP
如果WPAD客户端已经在其初始化过程中执行了DHCP查询,DHCP服务器可能就已经提供了那个值。如果无法通过客户端OS API获得这个值,客户端就向DHCP服务器发送一条DHCPINFORM报文,以获取这个值
WPAD的DHCP可选代码252为STRING类型,可以是任意长度。这个字符串中包含了一个指向适当PAC文件的URL。比如:
"http://server.domain/proxyconfig.pac"
4、DNS A记录查找
要让这种机制工作,就必须将合适的代理服务器的IP地址存储在WPAD客户端可以查询的DNS服务器上。WPAD客户端会向DNS服务器发送一个A记录查询,以获取CURL。成功查询的结果中会包含合适的代理服务器的IP地址
WPAD客户端实现必须支持这种机制。这应该是很简单的,因为它只要求基本的DNS A记录查找。对WPAD来说,规范使用了“wpad”的“知名别名”来进行Web代理自动发现
客户端执行了下列DNS查找:
QNAME=wpad.TGTDOM., QCLASS=IN, QTYPE=A
成功的查找中包含了IP地址,WPAD客户端根据这个地址构建CURL
5、获取PAC文件
只要创建了候选的CURL,WPAD客户端通常都会向CURL发送一条GET请求。发出请求时,WPAD客户端必须要发送一些带有适当CFILE格式信息的Accept首部,这些CFILE格式都是它们所能处理的。比如:
Accept: application/x-ns-proxy-autoconfig
而且,如果CURL的结果是要进行重定向,客户端就必须跟随这些重定向到其最终目的地
6、何时执行WPAD
至少要在出现以下情况的时候进行Web代理自动发现:
a、在Web客户端启动的时候——WPAD只在第一个实例启动的时候执行。后面的实例会继承这种设置
b、只要有来自网络栈的通知,就说明客户端主机的IP地址改变了
哪个选项在其环境中有意义,Web客户端就可以选择哪个。而且,客户端还必须根据HTTP的过期时间,为之前下载的PAC文件的过期时间尝试一个发现周期。PAC文件过期时,客户端遵循过期时间,重新运行WPAD过程是很重要的
如果PAC文件没有提供替换方案,在当前配置的代理失效的情况下,客户端还可以选择重新运行WPAD过程
只要客户端决定使当前的PAC文件失效,就必须重新运行整个WPAD协议,以确保它会发现当前正确的CURL。具体来说,就是协议不能有条件地获取PAC文件的If-Modified-Since
WPAD协议广播与/或多播通信可能需要大量的网络环回时间。WPAD协议的激活频率不应该高于上面指定的频率(比如在每次获取URL时进行一次)
7、WPAD欺骗
WPAD的IE5实现允许Web客户端在没有用户干预的情况下,自动检测代理设置。WPAD使用的算法会在全称域名前加上主机名“Wpad”,并会逐渐刪除子域名,直到它找到能够响应主机名的WPAD服务器,或到达第三级域名。比如,域a.b.microsoft.com中的Web客户端会先查询wpad.a.b.microsoft、wpad.b.microsoft.com,然后再查询wpad.microsoft.com
这样会暴露出一个安全漏洞,因为在国际应用(及其他特定的配置)中,第三级域名可能是不可信的。恶意用户可以建立一个WPAD服务器,并提供他选中的代理配置命令。后继(5.01及以后)的IE版本修正了这个问题
8、超时
WPAD会经过多个级别的发现,客户端必须确保每个阶段都有时限保证。可能的情况下,将每个阶段都限制在10秒以内是比较合理的,但实现者可能会选择其他更适合其网络特性的值。比如,运行在无线网络上的设备实现,由于带宽较低或时延较长,可能就会使用更大的时限
9、管理者的考虑
管理者至少应该在其环境中配置DHCP或DNS A记录查找方式中的一种,因为只有这两种方式是所有兼容客户端都必须实现的。除此之外,通过配置环境使其支持搜索列表中顺序靠前的机制,可以缩短客户端的启动时间
使用这种协议结构的主要动力之一是支持客户端定位附近的代理服务器。在很多环境中,都会有多个代理服务器(工作组、公司网关,ISP、骨干网等)
在WPAD框架结构中,可以在很多地方确定代理服务器是否“邻近”:
a、不同子网DHCP服务器会返回不同答案。还可以根据客户端的cipaddr字段或客户端标识符选项作出决定
b、可以对DNS服务器进行配置,使其为不同的域名后缀(比如,QNAME wpad.marketing.bigcorp.com和wpad.development.bigcorp.com)返回不同的SRV/A/TXT资源记录(RR)
c、处理CURL请求的Web服务器会根据user-Agent首部、Accept首部、客户端IP地址/子网/主机名、附近代理服务器的拓扑分布等作出决定。可能由处理CURL的CGI可执行文件进行这种处理。如前所述,甚至可能是某个处理CURL请求的代理服务器来作出这些决定
d、PAC文件的表达能力可能足以在客户端运行时从一组候选的代理服务器中进行选择。CARP就是在此基础上实现缓存阵列的。PAC文件可以计算出到一组候选代理服务器的网络距离(或其他合理的度量方式),并选择“最近”或“响应最积极”的服务器,这并不是什么不可思议的事情
我们已经讨论过一些将流量重定向到通用服务器的技术,以及一些将流量导向代理或网关的专用技术了。下面会介绍一些更复杂的、用于缓存代理服务器的重定向技术。这些技术要尽量做到可靠、高效且能感知内容——这样可以将请求分配到可能包含特定内容的位置上去,因此比前面讨论过的那些协议更复杂
【WCCP重定向】
Cisco系统公司开发的WCCP可以使路由器将Web流量重定向到代理缓存中去。WCCP负责路由器和缓存服务器之间的通信,这样路由器就可以对缓存进行验证(确保它们已启动且正在运行),在缓存之间进行负载均衡,并将特定类型的流量发送给特定的缓存了。WCCP版本2(WCCP2)是个开放的协议。下面探讨WCCP2
1、WCCP重定向工作流程
下面是WCCP重定向在HTTP上工作过程的概述(WCCP对其他协议的重定向过程也是类似的):启动包含了一些支持WCCP的路由器和缓存的网络,这些路由器和缓存之间可以相互通信;一组路由器及其目标缓存构成一个WCCP服务组。服务组的配置说明了要将何种流量发往何处、流量是如何发送的以及如何在服务组的缓存之间进行负载均衡;如果服务组配置为重定向HTTP流量,服务组中的路由器就会将HTTP请求发送给服务组中的缓存;HTTP请求抵达服务组中的路由器时,路由器会(根据对请求IP地址的散列,或者“掩码/值”的配对策略)选择服务组中的某个缓存为请求提供服务;路由器向缓存发送请求分组,可以用缓存的IP地址来封装分组,也可以通过IP MAC转发来实现;如果缓存无法为请求提供服务,就将分组返回给路由器进行普通的转发;服务组中的成员会互相交换心跳报文,不断验证对方的可用性
2、WCCP2报文
WCCP2报文有4种,如下表所示
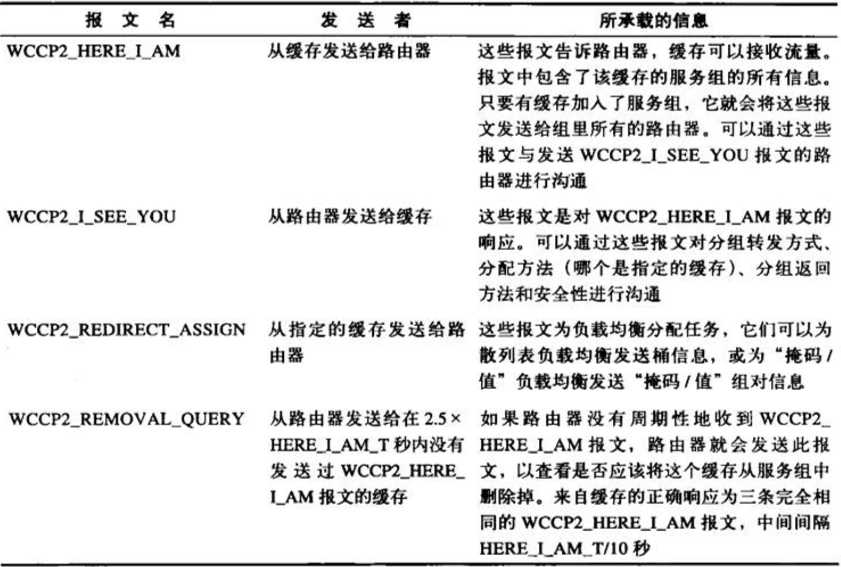
WCCP2_HERE_I_AM的报文格式为
Security Info Component Service Info Component Web-cache Identity Info Component Web-cache View Info Component Capability Info Component(可选) Command Extension Component(可选)
WCCP2_I_SEE_YOU的报文格式为
WCCP Message Header Security Info Component Service Info Component Router Identity Info Component Router View Info Component Capability Info Component(可选) Command Extension Component(可选)
WCCP2_REDIRECT_ASSIGN 的报文格式为
WCCP Message Header Security Info Component Service Info Component Assignment Info Component, or Alternate Assignment Component
WCCP2_REMOVAL_QUERY 的报文格式为
WCCP Message Header Security Info Component Service Info Component Router Query Info Component
3、报文组件
每条WCCP2报文都由一个首部和一些组件构成。WCCP首部信息包含报文类型(Here I Am、I See You、Assignment或Removal Query)、WCCP版本和报文长度(不包括首部的长度)
每个组件都以一个描述组件类型和长度的4字节首部开始。组件长度不包括组件首部的长度。报文组件如下表所述


4、服务组
服务组(service group)由一组支持WCCP的路由器和缓存组成,它们之间可以交换WCCP报文。路由器会向服务组中的缓存发送Web流量。服务组的配置确定了如何将流量分配到服务组的缓存中去。路由器和缓存会在Here I Am和I See You报文中交换服务组的配置信息
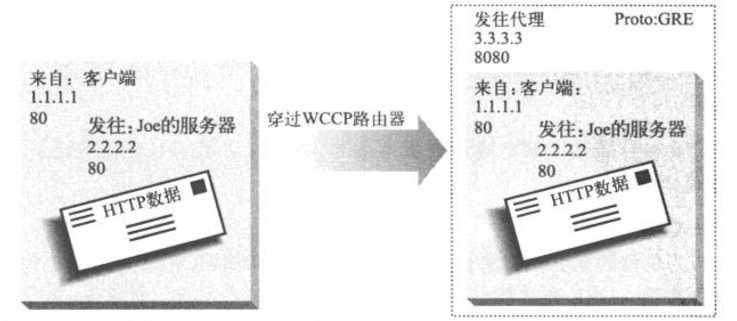
5、GRE分组封装
支持WCCP的路由器会用服务器的IP地址将HTTP分组封装起来,将其重定向到特定的服务器上去。分组封装中还包含了IP首部的proto字段,用来说明通用路由器封装(GRE)。proto字段的存在告诉接收代理,它有一个封装的分组。分组被封装起来,客户端的IP地址就不会丢失了。下图显示了GRE分组的封装过程
6、WCCP的负载均衡
除了路由功能之外,WCCP路由器还可以在几个接收服务器之间进行负载均衡。WCCP路由器及其接收服务器会交换心跳报文(heartbeat message),以便相互通知自己处于启动运行状态。如果某特定接收服务器停止发送心跳报文,WCCP路由器就会将请求流最直接发送到因特网上,而不会将其重定向给那个节点。节点重新提供服务时,WCCP路由器会再次开始接收心跳报文,并继续向节点发送请求流量
【因特网缓存协议】
ICP (因特网缓存协议)允许缓存在其兄弟缓存中查找命中内容。如果某个缓存中没有HTTP报文所请求的内容,它可以查明内容是否在附近的兄弟缓存中,如果在,就从那里获取内容,以避免查询原始服务器而带来的更多开销。可以把ICP当作一个缓存集群协议。HTTP请求报文的最终目的地可以通过一系列的ICP查询确定,从这个角度来说,它就是一个重定向协议
ICP是一个对象发现协议。它会同时去询问附近的多个缓存,看看它们的缓存中是否有特定的URL。附近的缓存如果有那个URL的话,就会返回一个简短的报文HIT,如果没有,就返回MISS。然后,缓存就可以打开一条到拥有此对象的邻居缓存的HTTP连接了
ICP是很简单直接的。ICP报文是一个以网络字节序表示的32位封装结构,这样更便于进行解析。为了提高效率,可以由UDP数据报承载其报文。UDP是一种不可靠的因特网协议,说明在传输的过程中数据可能会被破坏,因此使用ICP的程序要具有超时功能,以检测丢失的数据报
下面简要描述一下ICP报文中的部分信息
a、Opcode(操作码)
Opcode是个8位的二进制值,用以描述ICP报文的含义。基本的opcode包括ICP_OP_QUERY请求报文和ICP_OP_HIT和ICP_OP_MISS响应报文
b、版本
8位的版本号描述了ICP协议的版本编号。Squid使用的ICP版本记录在RFC 2186第2版中
c、报文长度
以字节为单位的ICP报文总长。因为只有16位,所以ICP报文的长度不能超过16383字节。URL通常都小于16KB,如果超过这个长度,很多Web应用程序就无法处理它了
d、请求编号
支持ICP的缓存会用请求编号来记录多个同时发起的请求和响应。ICP应答报文数必须与触发应答的ICP请求报文数相同
e、选项
32位的ICP选项字段是个包含了若干标记的位矢量,这些标记吋用来修改ICP的行为。ICPv2定义了两个标记,这两个标记都会修改ICP_OP_QUERY请求。ICP_FLAG_HIT_OBJ标记用来启动或禁止在ICP响应中返回文档数据。ICP_FLAG_SRC_RTT标记请求由兄弟缓存测量的、到原始服务器的环回时间的估计值
f、可选数据
保留了32位的可选数据用于可选特性。ICPv2使用了可选数据的低16位来装载从兄弟缓存到原始服务器的可选环回时间的估计值
g、发送端主机地址
承载了报文发送端32位IP地址的著名字段。实际中并未使用
h、净荷
净荷内容的变化取决于报文的类型。对ICP_OP_QUERY来说,净荷是一个4字节的原始请求端主机地址,后面跟着一个由NUL结尾的URL。对ICP_OP_HIT_OBJ来说,净荷是一个由NUL结尾的URL,后面跟着一个16位的对象长度,接着是对象数据
【缓存阵列路由协议】
代理服务器通过拦截来自单个用户的请求,提供所请求Web对象的缓存副本,极大地降低了发往因特网的流量。但随着用户数的增加,大量流量可能会使代理服务器自身超载
对此问题的一种解决方案就是使用多个代理服务器将负载分散到一组服务器上。CARP(缓存阵列路由协议)是微软公司和网景公司提出的一个标准,通过这个协议来管理一组代理服务器,使这组代理服务器对用户来说就像一个逻辑缓存一样
CARP是ICP的一个替代品。CARP和ICP都允许管理者通过使用多个代理服务器来提高性能。下面讨论CARP与ICP的区别,用CARP代替ICP的优缺点以及
CARP协议实现上的一些技术细节
ICP中出现缓存未命中时,代理服务器会用ICP报文格式来查询附近的缓存,以确定Web对象是否存在。附近的缓存会以HIT或MISS进行响应,请求代理服务器会用这些响应来选择能够获取到对象的最适当的位置。如果ICP代理服务器是以层次结构排列的,未命中的查询会被提交给其父代理。下图以图形方式显示了如何通过ICP来解决命中和未命中的问题
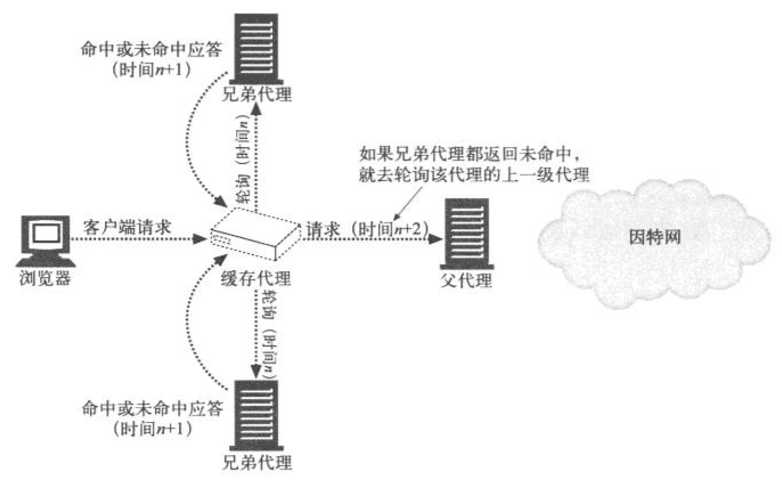
[注意]通过ICP协议连接起来的每个代理服务器都是将内容进行了冗余镜像的独立缓存服务器,这就说明在不同的代理服务器之间复制Web对象条目是可行的。相反,用CARP连接起来的一组服务器会被当作一个大型的服务器,其中每个组件服务器都只包含全部缓存文档中的一部分。通过对某个Web对象的URL应用散列函数,CARP就可以将此对象映射到特定的代理服务器上去。每个Web对象都有一个唯一的家,所以我们可以通过单次查找确定对象的位置,而无须去查询集合中配置的每个代理服务器。下图总结了CARP重定向的方式
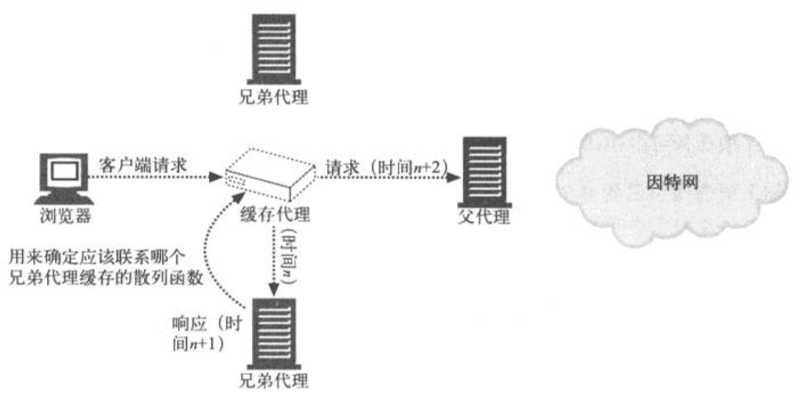
作为客户端和代理服务器中间人的缓存代理可以在各个代理服务器之间分配负载,但这项功能也可以由客户端自身提供。可以配置浏览器,以插件的形式计算散列函数,来确定应该把请求发送给哪个代理服务器
CARP对代理服务器做出的确定性解析说明它无须向所有邻居发送查询,这也就意味着这种方法所需发送的缓存间报文会比较少。随着越来越多的代理服务器添加到配置系统中来,缓存系统集群的规模会变得相当大。但CARP的一个缺点就是,如果某个代理服务器不可用了,就要重新修改散列表以反映这种变化,而且必须重新配置现存代理服务器上的内容。如果代理服务器经常崩溃的话,这么做的开销可能会很高。相反,ICP代理服务器中存在的冗余内容就表示它不需要重新配置。另一个潜在的问题是,由于CARP是个新协议,CARP集群中可能不会包含那些现存的、只运行ICP协议的代理服务器
CARP重定向方法要完成下列任务:保存一个参与CARP的代理服务器列表。周期性地查询这些代理服务器,看看它们是否仍然活跃;为每个参与的代理服务器计算一个散列函数。散列函数的返回值要考虑此代理所能处理的负载量;定义一个独立的散列函数,这个函数会根据所请求Web对象的URL返回一个数字;将URL散列函数的结果代入代理服务器的散列函数,得到一个数字阵列。这些数字中的最大值决定了要为这个URL使用的代理服务器。由于算出来的值是确定的,所以对同一个Web对象的后继请求会被转发给同一台代理服务器
以上4项任务可以由浏览器、插件执行,也可以在一个中间服务器上计算。为每个代理服务器集群创建一个表,表中列出了集群中的所有服务器。表中的每个条目都应该包含全局参数的相关的信息。比如,负载因子、生存时间(TTL)、倒计数值和应该以何频率查询成员之类的全局参数。负载因子说明机器可以处理多少负载,这取决于那台机器的CPU速度和硬盘容量。可以通过RPC接口对此表进行远程维护。只要表中的字段被RPC修改了,就可以使其对下游的客户端和代理可见,或将其发布给它们。这项发布工作是在HTTP中进行的,这样,所有的客户端或代理服务器就都可以在不引入另一种代理间协议的基础上消化表格信息了。客户端和代理服务器只用了一个知名URL来获取这张表
所使用的散列函数必须能够确保Web对象在参与的代理服务器间是统计分布的。应该用代理服务器的负载因子来确定分配给那台代理的Web对象的统计概率
总之,CARP协议允许将一组代理服务器看成单个的集群缓存,而不是(像ICP中那样的)一组相互合作但又相互独立的缓存服务器。确定的请求解析路径会在一跳内找到某个特定的Web对象的家。这样会降低ICP在一组代理服务器中查找Web对象时常会产生的代理间流量。CARP还可以避免在不同的代理服务器上存储Web对象的多个副本的问题,这样做的优点是缓存系统集群的Web对象存储容量较大,缺点是任意一个代理的故障都要改写现存代理的部分缓存内容
【超文本缓存协议】
前面我们讨论了ICP,这个协议允许代理缓存向兄弟缓存查询文件是否存在。但设计ICP时考虑的是HTTP/0.9协议。因此,向兄弟缓存查询资源是否存在时,只允许缓存发送URL。HTTP版本1.0和1.1引入了很多新的请求首部,这些首部可以和URL一起用来确定文件是否匹配。因此,只在请求中发送URL可能无法得到精确的响应
HTCP(超文本缓存协议)允许兄弟缓存之间通过URL和所有的请求及响应首部 来相互查询文档是否存在,以降低错误命中的可能。而且HTCP允许兄弟缓存监视或请求在对方的缓存中添加或删除所选中的文档,并修改对方已缓存文档的缓存策略
HTCP事务是另一个对象发现协议。如果附近的缓存中有这个文档,发起请求的缓存可以打开一条到此缓存的HTTP连接,以获取那个文档的副本。ICP和HTCP事务之间的区别体现在请求和响应细节上
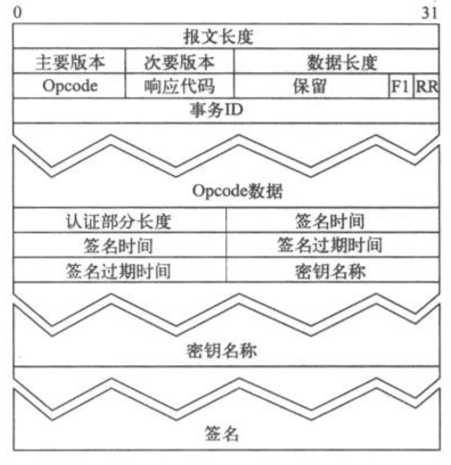
HTCP报文的结构如下图所示,首部中包含了报文的长度和报文版本。数据部分开始是数据长度,包含了opcode、响应代码、一些标记及ID,最后是实际的数据。可选的认证部分跟在Data小节的后面
报文字段的详细内容如下所述
a、首部
Header部分包含32位的报文长度,8位的主要协议版本和8位的次要协议版本。报文长度包含所有首部、数据和认证部分的长度
b、数据
Data部分包含了HTCP报文。数据组件如下表所示

下表列出了HTCP Opcode代码及其相应的数据类型

HTCP报文的认证部分是可选的,下表列出了它的认证组件

SET报文允许缓存请求对已缓存文档的缓存策略进行修改。下表给出了可以在SET报文中使用的首部

HTCP允许通过查询报文将请求和响应首部发送给兄弟缓存,这样可以降低缓存查询中的错误命中率。通过进一步允许在兄弟缓存间交换策略信息,HTCP还可以提高兄弟缓存之间的合作能力
标签:频率 无法 框架 存在 字符 操作码 copy 多播 foo
原文地址:http://www.cnblogs.com/tangshiguang/p/6759200.html