标签:最大化 部分 而在 实例 min 拉格朗日对偶 根据 证明 存在
1,SVM算法的思考出发点
SVM算法是一种经典的分类方法。对于线性可分问题,找到那个分界面就万事大吉了。这个分界面可以有很多,怎么找呢?SVM是要找到最近点距离最远的那个分界面。有点绕,看下面的图就明白了
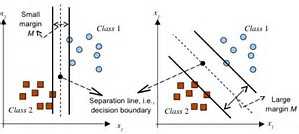
为了推导简单,我们先假设样本集是完全线性可分的,也就一个分界面能达到100%的正确率。
2,线性可分的情况
(1)优化目标的建立
最近点距离最远的分界面,这句话得用数学式子表示出来,这样才能用数学工具进行求解。
首先,假设分界面是y=wx+b,点\(x_i\)距离平面的距离用数学表达是\(\gamma_i=\frac{y_i(wx_i+b)}{||w||}\),这个是我们在中学学过的点到平面的距离,我们称之为几何距离。因为点分布在平面的两侧,所以这里乘以了\(y_i\)。
“最近点”该如何表达呢?
\(\gamma\)
s.t \(y_i(\frac{w\cdot x_i+b}{||w||})>=\gamma, i=1,2,...N\)
最近点距离最远的分界面,就是要上面的距离最大,用数学语言表示为
\(max_{w,b} \gamma\)
s.t \(y_i(\frac{w\cdot x_i+b}{||w||})>=\gamma, i=1,2,...N\)
到目前为止,我们的目标函数已经得到。
分析这个目标函数,这是个有约束的优化问题,但是要求解的w在分母上,为了方便求解,我们做一些整理,原优化问题为,
\(max_{w,b}\frac{y^*(w\cdot x^*+b)}{||w||}\)
s.t \(y_i(\frac{w\cdot x_i+b}{||w||})>=\frac{y^*(w\cdot x^*+b)}{||w||}, i=1,2,...N\)
其实\(y^*(w\cdot x^*+b)\)的值对最终的结果没有影响,就像y=ax+b与2y=2ax+2b其实是一样,所以不妨让\(y^*(w\cdot x^*+b)=1\),这样目标函数变为,
\(max_{w,b}\frac{1}{||w||}\)
s.t \(y_i(w\cdot x_i+b)>=1, i=1,2,...N\)
在考虑到最大化\(\frac{1}{||w||}\)和最小化\(||w||^2\)的等价的,目标函数可以写成如下形式
\(min_{w,b}\frac{1}{2}||w||^2\)
s.t \(y_i(w\cdot x_i+b)>=1, i=1,2,...N\)
这样就变成了一个容易求解的凸二次规划问题。
(2)优化目标的求解
对于凸二次规划问题,常用的求解方法就是拉格朗日对偶算法。
对偶问题和原问题的解是否相同呢?只有相同,我们才能用对偶算法。按照李航《统计学习方法》附录C,定理C.2,

回到我们的目标函数,因为数据线性可分,肯定存在w,使得所有不等式小于0(目标函数中的约束不等式取个负号,大于等于变成小于等于)。因此,我们可以通过求解对偶问题得到原始问题的解。
首先,构建拉格朗日函数,将不等式约束去除,
\(L(w,b,\alpha)=||w||^2-\sum_{i=1}^N\alpha_iy_i(w\cdot x_i+b)+\sum_{i=1}^N\alpha_i\),要求\(\alpha_i>=0\)
原始问题的对偶问题是极大极小问题,
\(max_\alpha min_{w,b}L(w,b,\alpha)\)
下面开始求解这个问题
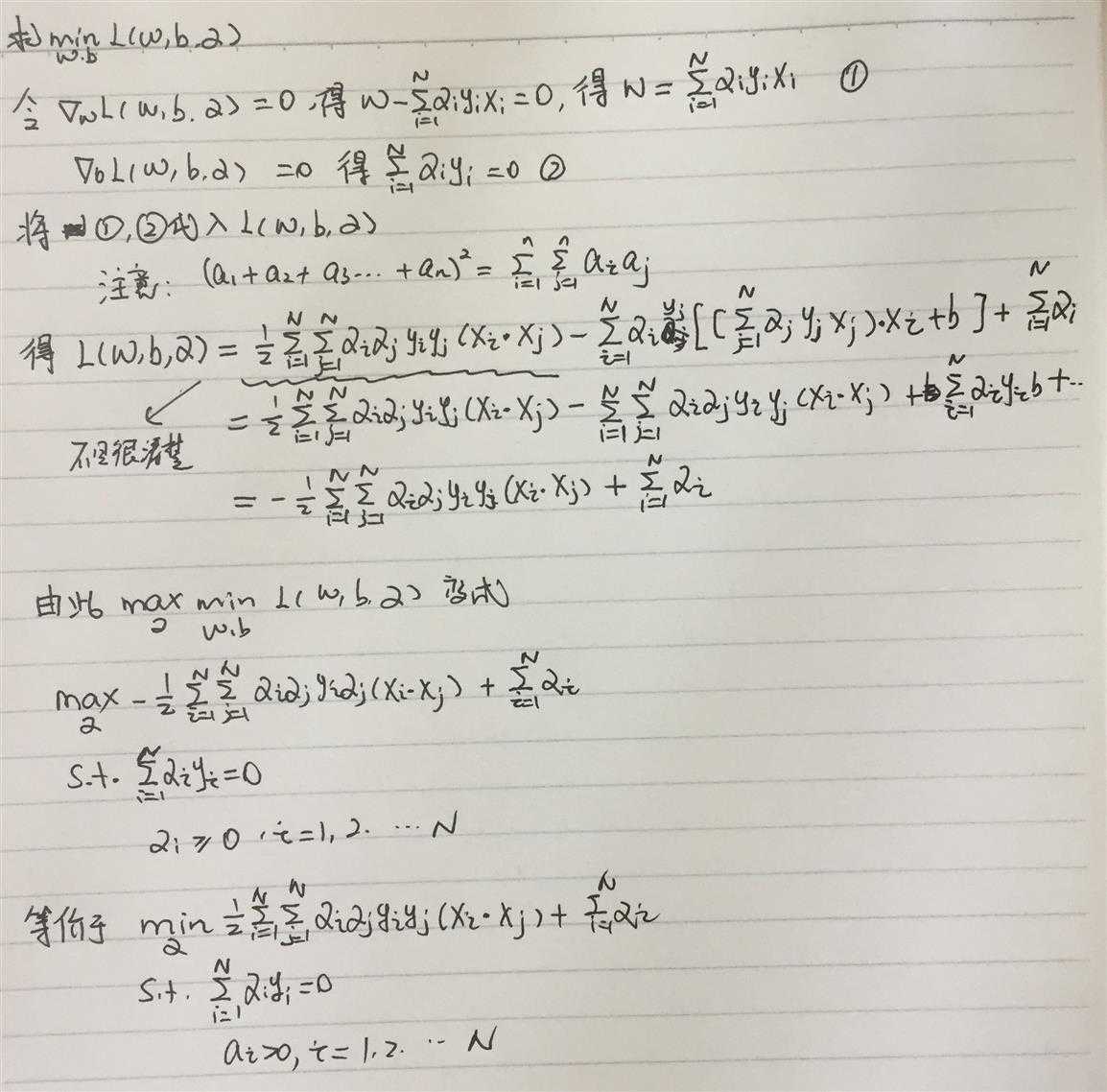
接下来求解相应的\(\alpha\),这里不在详述。
求解出\(\alpha\),根据定理C.3,求解原问题的解

假设\(\alpha^*\)是对偶问题最优解,\(w^*,b^*\)是原始问题最优解,根据KKT条件成立,即得:
(1)\(\triangledown L(w^*,b^*,\alpha^*)=w^*-\sum_{i=1}^N \alpha_i^* y_i x_i=0\),得到\(w^*=\sum_{i=1}^N \alpha_i^* y_i x_i=0\)
(2)\(\triangledown L(w^*,b^*,\alpha^*)=-\sum_{i=1}^N \alpha_i^*y_i=0\)
(3)\(a_i^*(y_i(w^* \cdot x_i+b^*)-1)=0\),i=1,2,3..N
(4)\(y_i(w^* \cdot x_i+b^*)-1\)>=0,i=1,2,..N
(5)\(a_i^*>=0\),i=1,2,...N
至少有一个\(\alpha_j>0\),这个可以用反证法证明,假设\(\alpha^*=0\),由(1)得\(w^*=0\),但是\(w^*=0\)不是原问题的一个解,因此肯定存在\(\alpha_j>0\),那么根据(3)得到
\(y_j(w^* \cdot x_j+b^*)-1=0\)
左后乘以\(y_j得到\)
\(b^*=y_i-\sum_{i=1}^N \alpha_i^* y_i (x_i \cdot x_j)\)
由此,得到了分类超平面的w和b,决策函数可以写成
\(f(x) = sign(\sum_{i=1}^N \alpha_i y_i (x_i \cdot x)+b^*)\) (*)
由此可以看出,分类决策函数只依赖于输入x和训练样本的内积。前面分析过存在\(\alpha_j>0\),那么根据(3)可以得到\(y_j(w^* \cdot x_j+b^*)-1=0\),\(\alpha_j>0\)对应的样本叫做支持向量,它们分布于分隔边界上。还有一部分样本,它们分布在分隔边界里,这些样本满足\(y_i(w^* \cdot x_i+b^*)-1>0\),那么根据(3)可知,这些样本对应的\(\alpha\)分量为0。所以,从(*)式看到,一个新来的样本x被分成哪个类,至于支持向量有关,而与其它训练样本无关,因为它们对应的\(\alpha_i\)为0.
3,线性可分但是存在异常点
实际情况中,用来训练模型的数据,很少有完全线性可分,总是存在部分异常点。而在2部分推导的模型,显然没有考虑这种情况。
在2部分得到的优化目标是
\(min_{w,b}\frac{1}{2}||w||^2\)
s.t \(y_i(w\cdot x_i+b)>=1, i=1,2,...N\)
为了使这个优化目标能够容忍异常,我们为每个样本点添加个松弛因子\(\xi_i\),容许这个点超出些界限,约束变成\(y_i(w\cdot x_i+b)>=1-\xi_i, i=1,2,...N\)。但是每个松弛因子的添加也不能不付出代价,所以最终的目标函数变成
\(min_{w,b}\frac{1}{2}||w||^2+C\sum_{i=1}^{N}\xi_i\)
s.t \(y_i(w\cdot x_i+b)>=1-\xi_i, i=1,2,...N\)
\(\xi_i>=0,i=1,2,3...N\)
目标函数的求解和2部分大同小异,这里不再推导,具体可参见李航《统计学习方法》第7章。最终结果是:
\(w^*=\sum_{i=1}^N \alpha_i^* y_i x_i=0\)
\(b^*=y_i-\sum_{i=1}^N \alpha_i^* y_i (x_i \cdot x_j)\)
形式上看和2部分相同,但是\(y_i\)的条件不同,这里不细述。
这里给出KKT条件,这有利于我们对支持向量的分析。
(1)\(\triangledown_w L(w^*,b^*,\xi^*,\alpha^*,\mu^*)=w^*-\sum_{i=1}^N \alpha_i^* y_i x_i=0\),得到\(w^*=\sum_{i=1}^N \alpha_i^* y_i x_i=0\)
(2)\(\triangledown_b L(w^*,b^*,\xi^*,\alpha^*,\mu^*)=-\sum_{i=1}^N \alpha_i^*y_i=0\)
(3)\(\triangledown_\xi L(w^*,b^*,\xi^*,\alpha^*,\mu^*)=C-\alpha^*-\nu^*=0\)
(4)\(a_i^*(y_i(w^* \cdot x_i+b^*)-1+\xi_i^*)=0\),i=1,2,3..N
(5)\nu_i^*\xi_i^*=0
(6)\(y_i(w^* \cdot x_i+b^*)-1+\xi_i^*\)>=0,i=1,2,..N
(7)\(a_i^*>=0\),i=1,2,...N
(8)\(\xi_i>=0\),i=1,2,...N
(9)\(\mu_i^*>=0\),i=1,2,...N
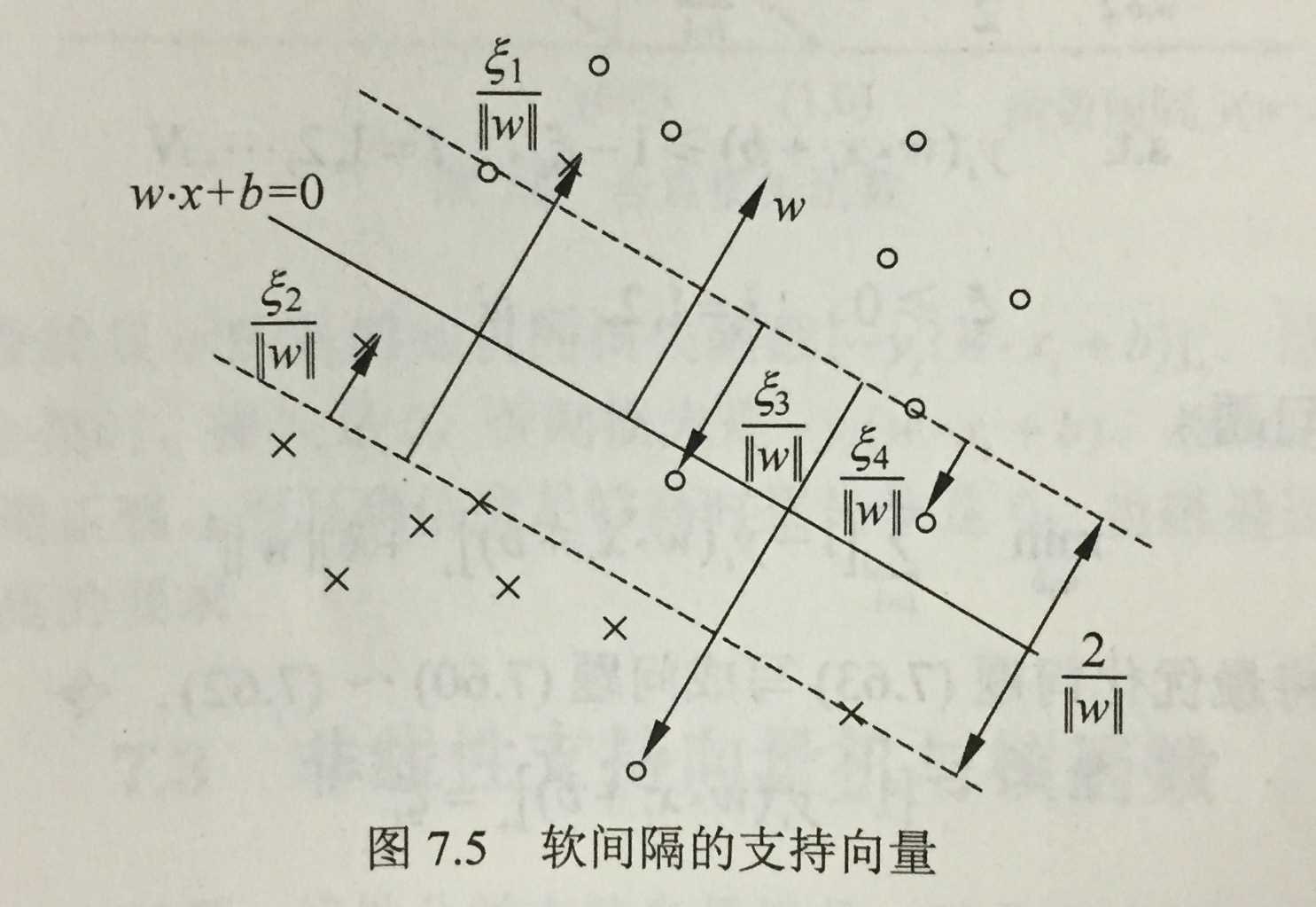
\(\alpha_i^*>0\)的样本点的实例\(x_i\)称作为支持向量,在2部分,只有间隔边界上的点满足\(\alpha_i^*>0\)。但是,当引入松弛变量时,情况变的复杂。
第一类点:间隔边界里面的点
这些点满足 \(y_i(w^* \cdot x_i+b^*)>1 \),由(4)得\(\alpha_i^*=0\),由(2)得\(\mu_i^*=0\),又由(5)得\(\xi_i^*=0\),
第二类点:间隔边界上的点
若\(0<\alpha_i^*<C\),则\(\xi_i^*=0\),支持向量落在间隔边界上。由(3)(4)(5)容易推得。
第三类点:间隔边界和分界线之间的点
若\(\alpha_i^*=C\),\(0<\xi_i^*<1\),则分类正确,\(x_i\)在间隔边界和分界线之间。由(3)(4)容易推得。
第四类点:分错的点
若\(\alpha_i^*=C\),\(\xi_i^*>1\),则样本位于误分一侧。由(3)(4)容易推得。
参考下图理解
4,线性不可分的情况
现实中,很多情况下两类样本是线性不可分的。SVM的思路是进行空间映射,将样本从不可分的空间映射到可分的空间。
从前两部分推导出来分隔面可以看出,
\(f(x) = sign(\sum_{i=1}^N \alpha_i y_i (x_i \cdot x)+b^*)\)
新来的样本只需与训练样本做点积即可得到label. 其实,样本如何从A空间映射到B空间并不是很重要,只要能够得到两个样本在新空间的点积就够了。核函数正是利用这一思想。它省掉了映射这一步,这一步可以非常复杂,因此,核函数的应用提高了效率。
常用的核函数有:多项式核函数,高斯核函数,字符串核函数。
核函数理论很丰富,这里不再详述。
参考: 李航《统计学习方法》
标签:最大化 部分 而在 实例 min 拉格朗日对偶 根据 证明 存在
原文地址:http://www.cnblogs.com/naniJser/p/6883137.html