标签:超时 链表 UI obj 包含 python get 复用 寻址
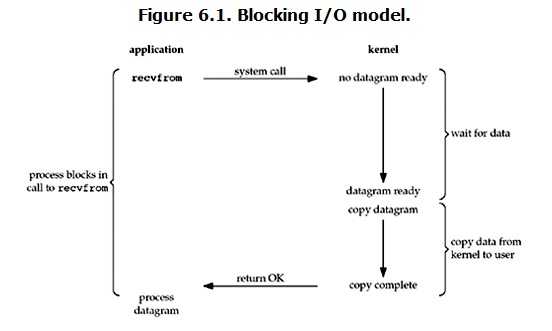
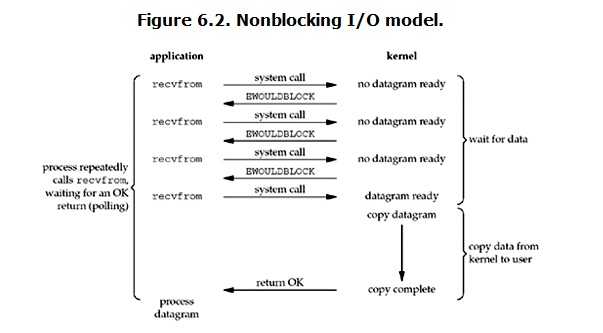
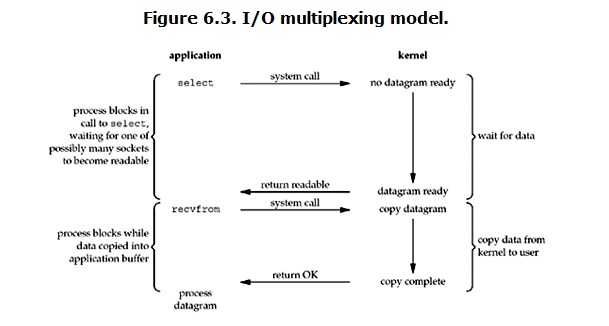
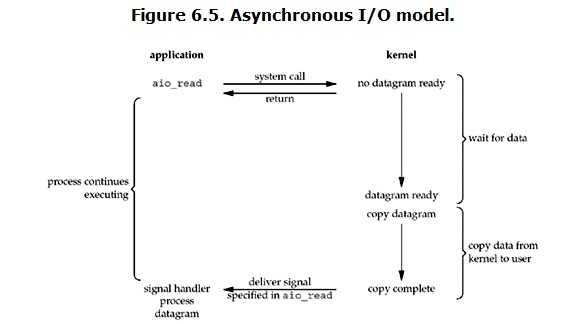


1 import select 2 import socket 3 import queue 4 5 server = socket.socket() 6 server.bind(("localhost", 9000)) 7 server.listen(1000) 8 9 msg_dict = {} # 存放要发送的消息队列 10 11 inputs = [server, ] # 要监测的实例 12 outputs = [] 13 14 while True: 15 readable, writeable, exceptional = select.select(inputs, outputs, inputs) 16 17 for e in exceptional: # 如果返回错误信息 18 if e in outputs: # 如果连接在outputs里则移除 19 outputs.remove(e) 20 inputs.remove(e) # inputs里的连接直接移除 21 del msg_dict[e] # 删除消息队列 22 23 for r in readable: 24 if r is server: # 代表来了一个新连接 25 conn, addr = server.accept() 26 inputs.append(conn) # 让select监测新连接 27 msg_dict[conn] = queue.Queue() # 生成一个新连接要发送数据的消息队列 28 else: # 代表连接接收到数据了 29 try: 30 data = r.recv(1024) # 收数据 31 except (ConnectionResetError, ConnectionAbortedError) as e: # 出现异常,说明用户断开连接或者程序中止了一个连接 32 print(e) 33 if r in outputs: 34 outputs.remove(r) 35 inputs.remove(r) 36 del msg_dict[r] # 删除消息队列 37 break 38 msg_dict[r].put(data) # 将要发送的数据放入消息队列中 39 outputs.append(r) # 将连接放入outputs里,下次select循环必然会返回此次的连接 40 41 for w in writeable: # 代表需要给客户端返回数据 42 data = msg_dict[w].get() # 获取连接对应的消息队列里的消息 43 w.send(data) # 给客户端发送消息 44 outputs.remove(w) # 从outputs里移除已经发好消息的连接,这样下次就不会重复发送消息了
复杂版:
1 import select 2 import socket 3 import queue 4 5 server = socket.socket() 6 server.setblocking(0) 7 8 server_addr = (‘localhost‘, 9000) 9 10 print(‘starting up on %s port %s‘ % server_addr) 11 server.bind(server_addr) 12 13 server.listen(5) 14 15 inputs = [server, ] # 自己也要监测呀,因为server本身也是个fd 16 outputs = [] 17 18 message_queues = {} 19 20 while True: 21 print("waiting for next event...") 22 23 readable, writeable, exeptional = select.select(inputs, outputs, inputs) # 如果没有任何fd就绪,那程序就会一直阻塞在这里 24 25 for s in readable: # 每个s就是一个socket 26 27 if s is server: # 别忘记,上面我们server自己也当做一个fd放在了inputs列表里,传给了select,如果这个s是server,代表server这个fd就绪了, 28 # 就是有活动了, 什么情况下它才有活动? 当然 是有新连接进来的时候 呀 29 # 新连接进来了,接受这个连接 30 conn, client_addr = s.accept() 31 print("new connection from",client_addr) 32 conn.setblocking(0) 33 inputs.append(conn) # 为了不阻塞整个程序,我们不会立刻在这里开始接收客户端发来的数据, 把它放到inputs里, 下一次loop时,这个新连接 34 # 就会被交给select去监听,如果这个连接的客户端发来了数据 ,那这个连接的fd在server端就会变成就续的,select就会把这个连接返回,返回到 35 # readable 列表里,然后你就可以loop readable列表,取出这个连接,开始接收数据了, 下面就是这么干 的 36 37 message_queues[conn] = queue.Queue() # 接收到客户端的数据后,不立刻返回 ,暂存在队列里,以后发送 38 39 else: # s不是server的话,那就只能是一个 与客户端建立的连接的fd了 40 # 客户端的数据过来了,在这接收 41 try: 42 data = s.recv(1024) 43 except (ConnectionResetError, ConnectionAbortedError) as e: # 出现异常,说明用户断开连接或者程序中止了一个连接 44 print("客户端断开了", s) 45 if s in outputs: 46 outputs.remove(s) # 清理已断开的连接 47 inputs.remove(s) # 清理已断开的连接 48 del message_queues[s] # 清理已断开的连接 49 else: # 一切正常 50 print("收到来自[%s]的数据:" % s.getpeername()[0], data) 51 message_queues[s].put(data) # 收到的数据先放到queue里,一会返回给客户端 52 if s not in outputs: 53 outputs.append(s) # 为了不影响处理与其它客户端的连接 , 这里不立刻返回数据给客户端 54 55 for s in writeable: 56 try: 57 next_msg = message_queues[s].get_nowait() 58 s.send(next_msg.upper()) 59 except queue.Empty: 60 print("client [%s]" % s.getpeername()[0], "queue is empty..") 61 outputs.remove(s) 62 except (ConnectionResetError, ConnectionAbortedError) as e: # 出现异常,说明用户断开连接或者程序中止了一个连接 63 outputs.remove(s) 64 except KeyError: 65 if s in outputs: 66 outputs.remove(s) 67 else: 68 print("sending msg to [%s]" % s.getpeername()[0], next_msg) 69 outputs.remove(s) 70 71 for s in exeptional: 72 print("handling exception for ", s.getpeername()) 73 inputs.remove(s) 74 if s in outputs: 75 outputs.remove(s) 76 s.close() 77 del message_queues[s]
1 import socket 2 import select 3 4 s = socket.socket() 5 s.bind((‘127.0.0.1‘,8888)) 6 s.listen(5) 7 epoll_obj = select.epoll() 8 epoll_obj.register(s,select.EPOLLIN) 9 connections = {} 10 while True: 11 events = epoll_obj.poll() 12 for fd, event in events: 13 print(fd,event) 14 if fd == s.fileno(): 15 conn, addr = s.accept() 16 connections[conn.fileno()] = conn 17 epoll_obj.register(conn,select.EPOLLIN) 18 msg = conn.recv(200) 19 conn.sendall(‘ok‘.encode()) 20 else: 21 try: 22 fd_obj = connections[fd] 23 msg = fd_obj.recv(200) 24 fd_obj.sendall(‘ok‘.encode()) 25 except BrokenPipeError: 26 epoll_obj.unregister(fd) 27 connections[fd].close() 28 del connections[fd] 29 30 s.close() 31 epoll_obj.close()
client:
1 import socket 2 3 s = socket.socket() 4 s.connect((‘127.0.0.1‘, 9999)) 5 while True: 6 input_msg = input(‘>>:‘) 7 if len(input_msg) == 0: 8 continue 9 s.sendall(input_msg.encode()) 10 msg = s.recv(1024) 11 print(msg.decode())
1 import selectors 2 import socket 3 4 sel = selectors.DefaultSelector() 5 6 def accept(sock, mask): 7 conn, addr = sock.accept() # Should be ready 8 print(‘accepted‘, conn, ‘from‘, addr) 9 conn.setblocking(False) 10 sel.register(conn, selectors.EVENT_READ, read) 11 12 def read(conn, mask): 13 try: 14 data = conn.recv(1000) # Should be ready 15 except (ConnectionAbortedError, ConnectionResetError) as e: 16 print(e) 17 print(‘closing‘, conn) 18 sel.unregister(conn) 19 conn.close() 20 else: 21 print(‘echoing‘, repr(data), ‘to‘, conn) 22 conn.send(data) # Hope it won‘t block 23 24 sock = socket.socket() 25 sock.bind((‘localhost‘, 9000)) 26 sock.listen(100) 27 sock.setblocking(False) 28 sel.register(sock, selectors.EVENT_READ, accept) 29 30 while True: 31 events = sel.select() 32 for key, mask in events: 33 callback = key.data 34 callback(key.fileobj, mask)
标签:超时 链表 UI obj 包含 python get 复用 寻址
原文地址:http://www.cnblogs.com/breakering/p/6979584.html
