标签:pap 9.png 对象 框架 nbsp 生成 learning present 产生
在文本处理领域,“The idea of local spatial context within a sentence, proved to be an effective supervisory signal for learning distributed word vector representations”,这有以下两个作用“Given a word tokenized corpus of text, to learn a representation for a target word that allows it to predict representations of contextual words around it; or vice versa, given contextual words to predict a representation of the target word.”
文本是一维的,其基本组成单位就是单词,一个单词的上下文环境可以通过看看其左边、右边的一些单词获取(这是文本的特性)。这种从研究对象本事寻找“其自然特性”并加以利用的做法,有可能为我们摆脱“在图像处理领域需要大量人工标记数据才能学习一个表达能力很强深度网络”指明一个方向(在没有人工标记样本的情况下,我们也可以学到表达能力很强的网络)。
现在的问题是,“图像的单词”是什么?像素、边缘、物体,还是场景?
图像单词的上下文环境又该如何定义?像素的四邻域,物体的空间布局,还是什么?
不同的人对上述问题有不同的理解,这样也就导致了沿着这个思路的一系列papers。本文将重点放在这篇paper的看法上。
这篇paper认为“单词应该是物体,其上下文环境应该是物体的空间布局”,原文是“By working with patches at object scale, our network can focus on more object-centric features and potentially ignore some of the texture and color details that are likely less important for semantic tasks”。物体的空间布局并不意味着物体应该是紧挨着的。
理解了这一前提之后,我们可以看看这篇paper的整体框架,如下图所示
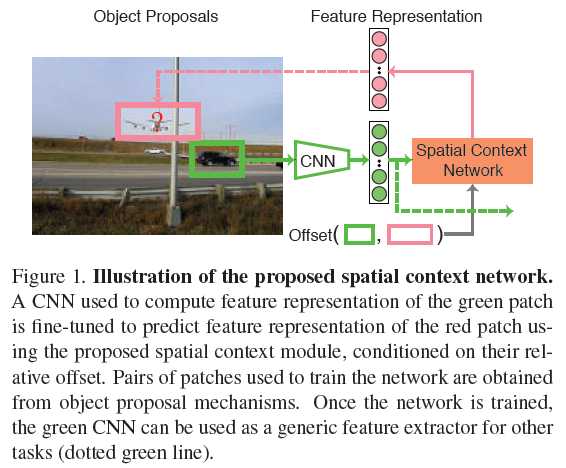
Figure 1想说明的是,给定“car”,及其与“airplane”的“offset”,我们预测“airplane”的表达。
明白了基本思路之后,有几个技术问题需要解决
1)我们怎么知道预测的“airplane”的表达是好还是坏呢?
这里面,作者采用了一个“trick”。如果我们事先知道“airplane”的一个很好的表达不就行了,采用现有的VGG、Alexnet活动一个物体的很好表达是trivial的。我们学习到的特征,通过与现有“好的表达”进行比对就可以了。基于此,作者设计了下面这个网络结构
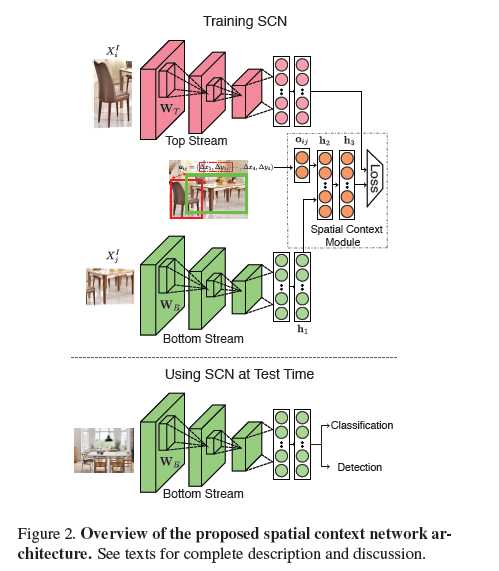
其中,Top stream和Bottom stream的网络结构相同,Top stream的参数是固定的(能够持续输出好的特征表达)。“offset”与Bottom stream的输出h1,一起输入到spatial context module,该模块的输出与Top stream的输出通过loss做对比。这样整个网络就没有思路上的障碍了,也就是说,至少在思路上是行得通的。
2)网络初始化
Bottom stream和Top stream采用已经在imagenet上pretrained的模型进行权值初始化,Top stream参数是固定的,Bottom stream和spatial context module参数是可学习的。
3)“car”、“airplane”等object如何产生呢?
我们有现成的“object agnostic”的region proposal的生成方法,作者在论文中也对比了几种算法的效果。
1)网络结构、参数初始化方式确定之后,下面的问题就是算法的实际效果了。这部分大家还是直接找原始paper来读一读比较好。
2)这篇论文的不足之处就是太依赖pretrained model了,严格来说,应该属于无监督的范畴。假如没有pretrained model,不晓得这篇论文的效果会怎么样?
3)这篇论文比较巧妙的也是依赖pretrained model避免了无监督学习trivial solution。
论文笔记 Weakly-Supervised Spatial Context Networks
标签:pap 9.png 对象 框架 nbsp 生成 learning present 产生
原文地址:http://www.cnblogs.com/everyday-haoguo/p/Note-SCN.html
{kind=link}