标签:格式 ges html 中间 .com 二进制格式 字节 htm gbk
1. 无论py2还是py3,字符编码之间相互转换,如gbk转换成utf-8,都需要通过unicode中转
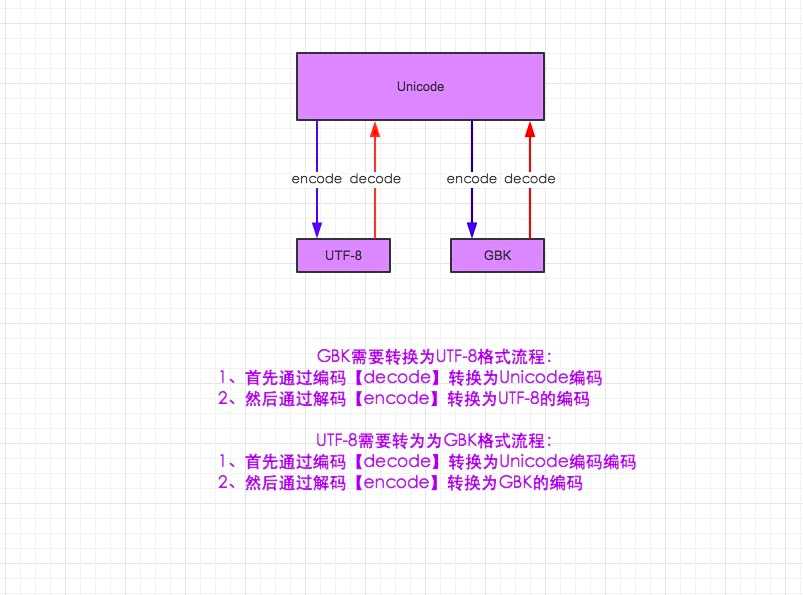 ,
,
2. 将非unicode转换成unicode的时候,是需要告知原本是什么类型,如原本是utf-8的,转换成unicode应如下:
string1 = "你好"
假设string1原本是utf-8,需要转换成unicode,
则转换过程为:string1.decode("utf-8")
3. 如果需要将原本为utf-8的转换为gbk,则流程应为先将string1转换成unicode,再转换成gbk
string1.decode("utf-8")
string1.encode("gbk")指定为转换后的字符编码
python3中,在encode的时候,不仅将字符串改变的字符编码,并且改变成二进制格式
python2中解释器的默认以ASCII码去解释文件,python3中通过utf-8去解释文件,但可以通过在文件开头以 # -*- coding:utf-8 -*- 的方式告知解释器以utf-8来解码
python3中,文件内的数据类型是用unicode编码的,如字符串的字符类型是unicode
1 import sys 2 print(sys.getdefaultencoding()) #打印系统默认编码 3 4 s = "杭州" #python 3中文件内的字符串类型默认是unicode 5 print(s,type(s)) 6 print(s) 7 s = s.encode("gbk") #将unicode编码成gbk 8 print(s,"=========") 9 s_to_unicode = s.decode("gbk") #将编码由gbk转换成unicode,这个意识是告知s原本是gbk的编码需要转换成unicode 10 print(s_to_unicode) 11 12 unicode_to_utf8 = s_to_unicode.encode("utf-8") #将原本是unicode的转换成utf-8 13 print(unicode_to_utf8) 14 utf8_to_gb2312 = unicode_to_utf8.decode("utf-8").encode("gb2312") #将原本是utf-8的转换成gb2312,中间需要通过先decode转换成unicode,再将unicode通过encode转换成gb2312 15 print(utf8_to_gb2312)
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
4. ASCII占用一个字节,GBK,GB2312占用两个字节,UTF-8编码是变长编码,通常汉字占三个字节,扩展B区以后的汉字占四个字节。
参考链接:http://www.cnblogs.com/yuanchenqi/articles/5956943.html
标签:格式 ges html 中间 .com 二进制格式 字节 htm gbk
原文地址:http://www.cnblogs.com/clv5/p/7062395.html