标签:区别 取数据 发送 padding upper pre one 演示 next
目录
一. 面向对象高级用法
二. 加工标准类型(继承、授权)
三. 迭代协议
四. 上下文管理协议
五. __call__方法
六. 元类
七. socket介绍、基于tcp协议的socket
八. 通讯循环 和 链接循环
九. 基于socket实现远程执行命令
十. 自定义报头解决粘包问题
1. __str__ 字符串返回值
class Foo:
def __init__(self,name,age):
self.name=name
self.age=age
def __str__(self):
#必须有返回值,且必须返回字符串类型
return ‘<name:%s age:%s>‘ %(self.name,self.age)
obj=Foo(‘egon‘,18)
print(obj) #如果没有__str__ 打印出来的是一个对象
2.__del__ 析构方法
#应用:关掉数据库连接,避免占用内存中数据资源
class Foo:
def __init__(self,name,age):
self.name=name
self.age=age
def __del__(self): #析构方法
print(‘del---->‘)
obj=Foo(‘egon‘,18)
del obj
print(‘=============>‘)
3. __setitem__ , __getitem__ ,__delitem__ 自定义字典属性操作,统一调用方式
class Foo:
def __init__(self,name):
self.name=name
def __getitem__(self, item):
# print("getitem")
return self.__dict__[item] # 这里是真正的获取
def __setitem__(self, key, value):
# print("setitem",key,value)
self.__dict__[key]=value # 这里是真正的更改
def __delitem__(self, key):
# print(‘del obj[key]时,我执行‘)
self.__dict__.pop(key) # 这里是真正的删除
obj=Foo(‘egon‘)
obj.name=‘egon666‘ # 以前的修改方式
print(obj.name)
obj[‘name‘]=‘egon666‘ # 现在是以字典的方式 此时触发了__setitem__方法,还没有更改内容
print(obj[‘name‘])
# print(obj.name)
del obj[‘name‘]
print(obj.__dict__) #删除后的查看
你的程序慢的原因就是没有统一方法
# 如果没有item方法,需要判断obj的类型,函数将多出于功能无关的逻辑
def func(obj,key,value):
if isinstance(obj,dict):
obj[key]=value #obj[‘name‘]=‘123123‘
else:
setattr(obj,key,value)
# 加上item方法,则无需判断obj的类型,不管是dict类型还是Foo类型(自己定义的类型),都以统一的一种[]的方式操作
def func(obj,key,value):
obj[key]=value #obj[‘name‘]=‘123123‘
dic={‘name‘:‘egon‘,‘age‘:18}
obj=Foo(‘egon‘)
# func(dic,‘name‘,‘egon666‘)
# print(dic)
print(obj.__dict__)
func(obj,‘name‘,‘123123123123‘)
print(obj.__dict__)
1. __setattr__ , __getattr__ ,__delattr__ 特殊在于__getattr__的方法使用
class Foo:
def __init__(self,x):
self.x=x # self.x=10 #self.__dict__[‘x‘]=10 初始化就会触发方法
def __getattr__(self, item):
print(‘getattr‘)
def __setattr__(self, key, value):
# print(‘setattr‘,key,type(key))
# setattr(self,key,value) #obj.x=1 # 错误的执行 会产生递归
self.__dict__[key]=value #self.__dict__[‘x‘]=10 # 正确的执行
def __delattr__(self, item):
# print(‘delattr‘)
self.__dict__.pop(item)
def __del__(self): # __del__触发是在所有执行完毕后才执行
print(‘del‘)
obj=Foo(10)
# obj.x=1
# print(obj.__dict__)
# del obj.x #
print(obj.__dict__)
obj.a=1
obj.b=2
obj.c=3
print(obj.__dict__)
del obj.c
print(obj.__dict__)
# print(obj.x)
print(obj.yyyyyyyyyyyyyyyyyyyyy) # 当属性没有才触发__getattr__
2. 包装:python为大家提供了标准数据类型,以及丰富的内置方法,其实在很多场景下我们都需要基于标准数据类型来定制我们自己的数据类型,新增/改写方法,这就用到了我们刚学的继承/派生知识(其他的标准类型均可以通过下面的方式进行二次加工)
class List(list):
def __init__(self,item,tag=False):
super().__init__(item)
self.tag=tag
def append(self, p_object):
# print(p_object)
if not isinstance(p_object,str):
raise TypeError(‘%s must be str‘ %p_object)
super(List,self).append(p_object)
@property # mid为名字函数 需要执行函数的返回值
def mid(self):
mid_index=len(self)//2
return self[mid_index]
def clear(self):
if not self.tag:
raise PermissionError(‘not permissive‘)
super().clear()
self.tag=False
# l=List([1,2,3])
# l.append(4)
# l.append(‘aaaaa‘)
# l.append(‘aaaaa‘)
# print(l)
# print(l.mid)
# l.insert(0,123123123123123)
# print(l)
# l.tag=True
# l.clear()
# print(l)
# l=[1,2,3,4,5,56,6,7,7]
#
# mid_index=len(l)//2
# print(l[mid_index])
3. 授权:授权是包装的一个特性, 包装一个类型通常是对已存在的类型的一些定制,这种做法可以新建,修改或删除原有产品的功能。其它的则保持原样。授权的过程,即是所有更新的功能都是由新类的某部分来处理,但已存在的功能就授权给对象的默认属性。
实现授权的关键点就是覆盖__getattr__方法
import time
class Open:
def __init__(self,filepath,mode=‘r‘,encoding=‘utf-8‘):
self.filepath=filepath
self.mode=mode
self.encoding=encoding
self.f=open(self.filepath,mode=self.mode,encoding=self.encoding)
def write(self,msg):
t=time.strftime(‘%Y-%m-%d %X‘)
self.f.write(‘%s %s\n‘ %(t,msg))
def __getattr__(self, item):
# print(item,type(item))
return getattr(self.f,item)
obj=Open(‘a.txt‘,‘w+‘,encoding=‘utf-8‘)
# obj.f.write(‘11111\n‘)
# obj.f.write(‘2222\n‘)
# obj.f.write(‘33233\n‘)
# obj.f.close()
obj.write(‘aaaaa\n‘)
obj.write(‘bbbb\n‘)
obj.write(‘cccc\n‘)
# print(obj.seek)
# obj.close
obj.seek(0)
print(obj.read()) #self.f.read()
obj.close() #self.f.close()
class Foo:
def __init__(self,n,stop):
self.n=n
self.stop=stop
def __next__(self):
if self.n >= self.stop:
raise StopIteration # 抛出异常
x=self.n
self.n+=1
return x
def __iter__(self):
return self
obj=Foo(0,5) #0 1 2 3 4
# print(next(obj)) #obj.__next__()
# print(next(obj)) #obj.__next__()
# from collections import Iterator
# print(isinstance(obj,Iterator))
for i in obj:
print(i)
用途或者说好处:
1.使用with语句的目的就是把代码块放入with中执行,with结束后,自动完成清理工作,无须手动干预
2.在需要管理一些资源比如文件,网络连接和锁的编程环境中,可以在__exit__中定制自动释放资源的机制,你无须再去关系这个问题,这将大有用处
我们知道在操作文件对象的时候可以这么写
1 with open(‘a.txt‘) as f: 2 ‘代码块‘

1 class Open: 2 def __init__(self,name): 3 self.name=name 4 5 def __enter__(self): 6 print(‘出现with语句,对象的__enter__被触发,有返回值则赋值给as声明的变量‘) 7 # return self 8 def __exit__(self, exc_type, exc_val, exc_tb): 9 print(‘with中代码块执行完毕时执行我啊‘) 10 11 12 with Open(‘a.txt‘) as f: 13 print(‘=====>执行代码块‘) 14 # print(f,f.name) 15 16 上下文管理协议
1 class Open: 2 def __init__(self, name,mode=‘r‘,encoding=‘utf-8‘): 3 self.name = name 4 self.mode=mode 5 self.encoding=encoding 6 self.f=open(self.name,mode=self.mode,encoding=self.encoding) 7 def __enter__(self): 8 # print(‘__enter__‘) 9 return self.f 10 11 def __exit__(self, exc_type, exc_val, exc_tb): # 异常三要素 12 # print(‘__exit__‘) 13 print(exc_type) 14 print(exc_val) 15 print(exc_tb) 16 self.f.close() # 模拟的文件管理协议需要自行关闭文件 17 return True 18 19 # obj=Open(‘b.txt‘,‘w‘) 20 # print(obj) 21 22 23 24 with Open(‘c.txt‘,‘w‘) as f: #f=self.f 25 print(f) 26 1/0 27 print(‘===>‘) 28 f.write(‘11111\n‘) 29 f.write(‘22222\n‘) 30 31 print(‘=======>with以外的代码‘) 32 # int(‘aaaaaa‘) 33 # 34 # raise TypeError(‘11111111111‘)
对象后面加括号,触发执行。
注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
# 所有的类都在调用__call__
class Foo:
def __call__(self, *args, **kwargs):
print(‘======>‘)
obj=Foo()
# print(type(obj))
obj()
exec:三个参数
参数一:字符串形式的命令
参数二:全局作用域
参数三:局部作用域
exec会在指定的局部作用域内执行字符串内的代码,除非明确地使用global关键字
1. 引子(类也是对象)
1 class Foo: 2 pass 3 4 f1=Foo() #f1是通过Foo类实例化的对象
python中一切皆是对象,类本身也是一个对象,当使用关键字class的时候,python解释器在加载class的时候就会创建一个对象(这里的对象指的是类而非类的实例),因而我们可以将类当作一个对象去使用,同样满足第一类对象的概念,可以:
把类赋值给一个变量
把类作为函数参数进行传递
把类作为函数的返回值
在运行时动态地创建类
上例可以看出f1是由Foo这个类产生的对象,而Foo本身也是对象,那它又是由哪个类产生的呢?
1 #type函数可以查看类型,也可以用来查看对象的类,二者是一样的 2 print(type(f1)) # 输出:<class ‘__main__.Foo‘> 表示,obj 对象由Foo类创建 3 print(type(Foo)) # 输出:<type ‘type‘>
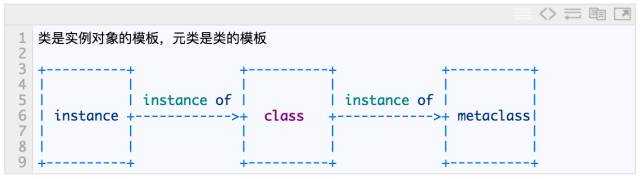
2. 什么是元类?
元类是类的类,是类的模板
元类是用来控制如何创建类的,正如类是创建对象的模板一样,而元类的主要目的是为了控制类的创建行为
元类的实例化的结果为我们用class定义的类,正如类的实例为对象(f1对象是Foo类的一个实例,Foo类是 type 类的一个实例)
type是python的一个内建元类,用来直接控制生成类,python中任何class定义的类其实都是type类实例化的对象
3. 创建类的两种方式
class Chinese(object):
country=‘China‘
def __init__(self,name,age):
self.name=name
self.age=age
def talk(self):
print(‘%s is talking‘ %self.name)
准备工作:
创建类主要分为三部分
1 类名
2 类的父类
3 类体
#类名
class_name=‘Chinese‘
#类的父类
class_bases=(object,)
#类体
class_body="""
country=‘China‘
def __init__(self,name,age):
self.name=name
self.age=age
def talk(self):
print(‘%s is talking‘ %self.name)
"""
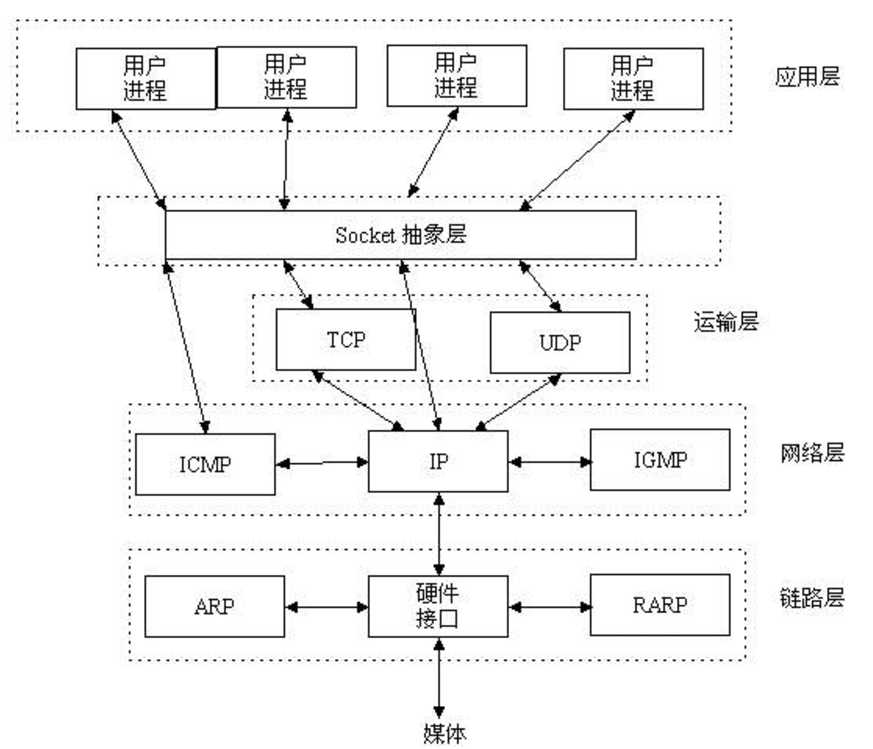
1、socket逻辑架构图:
2、socket概念
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。所以,我们无需深入理解tcp/udp协议,socket已经为我们封装好了,我们只需要遵循socket的规定去编程,写出的程序自然就是遵循tcp/udp标准的。
也有人将socket说成ip+port,ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序,ip地址是配置到网卡上的,而port是应用程序开启的,ip与port的绑定就标识了互联网中独一无二的一个应用程序而程序的pid是同一台机器上不同进程或者线程的标识
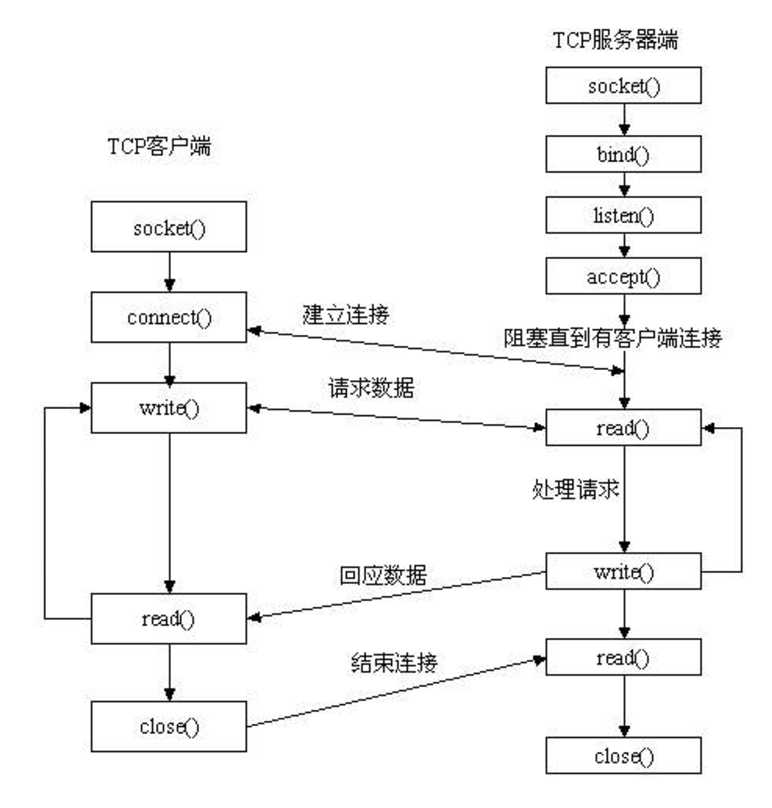
3、套接字工作流程
a. 工作流程(服务端--〉客户端):
服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
import socket socket.socket(socket_family,socket_type,protocal=0) socket_family 可以是 AF_UNIX 或 AF_INET。socket_type 可以是 SOCK_STREAM 或 SOCK_DGRAM。protocol 一般不填,默认值为 0。 获取tcp/ip套接字 tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 获取udp/ip套接字 udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 由于 socket 模块中有太多的属性。我们在这里破例使用了‘from module import *‘语句。使用 ‘from socket import *‘,我们就把 socket 模块里的所有属性都带到我们的命名空间里了,这样能 大幅减短我们的代码。 例如tcpSock = socket(AF_INET, SOCK_STREAM)
b. python服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字
s.listen() 开始TCP监听
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
c. python客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
d. 公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
s.close() 关闭套接字
c. 面向锁的套接字方法
s.setblocking() 设置套接字的阻塞与非阻塞模式
s.settimeout() 设置阻塞套接字操作的超时时间
s.gettimeout() 得到阻塞套接字操作的超时时间
d. 面向文件的套接字的函数
s.fileno() 套接字的文件描述符
s.makefile() 创建一个与该套接字相关的文件
e.python套接字流程代码推到
1:用打电话的流程快速描述socket通信
2:服务端和客户端加上基于一次链接的循环通信
3:客户端发送空,卡主,证明是从哪个位置卡的
服务端:
from socket import *
phone=socket(AF_INET,SOCK_STREAM)
phone.bind((‘127.0.0.1‘,8081))
phone.listen(5)
conn,addr=phone.accept()
while True:
data=conn.recv(1024)
print(‘server===>‘)
print(data)
conn.send(data.upper())
conn.close()
phone.close()
客户端:
from socket import *
phone=socket(AF_INET,SOCK_STREAM)
phone.connect((‘127.0.0.1‘,8081))
while True:
msg=input(‘>>: ‘).strip()
phone.send(msg.encode(‘utf-8‘))
print(‘client====>‘)
data=phone.recv(1024)
print(data)
说明卡的原因:缓冲区为空recv就卡住,引出原理图
4.演示客户端断开链接,服务端的情况,提供解决方法
5.演示服务端不能重复接受链接,而服务器都是正常运行不断来接受客户链接的
6:简单演示udp
服务端
from socket import *
phone=socket(AF_INET,SOCK_DGRAM)
phone.bind((‘127.0.0.1‘,8082))
while True:
msg,addr=phone.recvfrom(1024)
phone.sendto(msg.upper(),addr)
客户端
from socket import *
phone=socket(AF_INET,SOCK_DGRAM)
while True:
msg=input(‘>>: ‘)
phone.sendto(msg.encode(‘utf-8‘),(‘127.0.0.1‘,8082))
msg,addr=phone.recvfrom(1024)
print(msg)
udp客户端可以并发演示
udp客户端可以输入为空演示,说出recvfrom与recv的区别,暂且不提tcp流和udp报的概念,留到粘包去说
http://www.cnblogs.com/wangshuyang/p/7049942.html
标签:区别 取数据 发送 padding upper pre one 演示 next
原文地址:http://www.cnblogs.com/lipingzong/p/7058199.html
