标签:loss var require from maximum save one img prim
Table Compression
表压缩
The database can use table compression to reduce the amount of storage required for the table.
数据库可以使用表压缩来消除数据块中的重复值。
Compression saves disk space, reduces memory use in the database buffer cache, and in some cases speeds query execution. Table compression is transparent to database applications.
对于数据高度冗余的表,压缩可以节省磁盘空间,减少数据库高速缓存中的内存使用,并在某些情况下可以加快查询执行速度。表压缩对数据库应用程序是透明的。
Basic and OLTP Table Compression
基本/OLTP
Dictionary-based table compression provides good compression ratios for heap-organized tables. Oracle Database supports the following types of dictionary-based table compression:
基于字典的表压缩提供了很好的压缩率。Oracle 数据库支持以下类型的表压缩:
|
Basic table compression 基本表压缩 |
This type of compression is intended for bulk load operations. The database does not compress data modified using conventional DML. You must use direct path loads, ALTER TABLE . . . MOVE operations, or online table redefinition to achieve basic compression. 这种类型的压缩只能压缩由直接路径加载插入的数据,只支持有限的数据类型和 SQL 操作。 |
|
OLTP table compression OLTP 表压缩 |
This type of compression is intended for OLTP applications and compresses data manipulated by any SQL operation. 这种类型的压缩用于 OLTP 应用程序,并可压缩任何 SQL 操作的数据。 |
For basic and OLTP table compression, the database stores compressed rows in row-major format.
数据库以 行主要格式存储压缩行。
All columns of one row are stored together, followed by all columns of the next row, and so on
一个行的所有列都存储在一起,接下来是下一行的所有列,依次类推。
Duplicate values are replaced with a short reference to a symbol table stored at the beginning of the block.
重复值被替换为一个存储在块开始处的符号表短引用。
Thus, information needed to re-create the uncompressed data is stored in the data block itself.
因此,重新创建未压缩数据所需的信息存储在数据块本身中。
Compressed data blocks look much like normal data blocks. Most database features and functions that work on regular data blocks also work on compressed blocks.
压缩的数据块看起来跟正常的数据块差不多。在常规数据块上能正常工作的大多数数据库功能,也可以在压缩的数据块上正常工作。
You can declare compression at the tablespace, table, partition, or subpartition level. If specified at the tablespace level, then all tables created in the tablespace are compressed by default.
您可以在表空间、 表、 分区或子分区等级别声明压缩。如果在表空间级指定了压缩,则在该表空间中创建的所有表在缺省情况下都是压缩的。
The following statement applies OLTP compression to the orders table:
下面的语句将 OLTP 压缩应用于 orders 表:
ALTER TABLE oe.orders COMPRESS FOR OLTP;
The following example of a partial CREATE TABLE statement specifies OLTP compression for one partition and basic compression for the other partition:
如下所示的 CREATE TABLE 语句示例片断,指定其中一个分区为 OLTP 压缩,而其他分区为基本压缩:
CREATE TABLE sales (
prod_id NUMBER NOT NULL,
cust_id NUMBER NOT NULL, ... )
PCTFREE 5 NOLOGGING NOCOMPRESS
PARTITION BY RANGE (time_id)
( partition sales_2008 VALUES LESS THAN(TO_DATE(...)) COMPRESS BASIC,
partition sales_2009 VALUES LESS THAN (MAXVALUE) COMPRESS FOR OLTP );
Hybrid Columnar Compression
With Hybrid Columnar Compression, the database stores the same column for a group of rows together. The data block does not store data in row-major format, but uses a combination of both row and columnar methods.
Storing column data together, with the same data type and similar characteristics, dramatically increases the storage savings achieved from compression. The database compresses data manipulated by any SQL operation, although compression levels are higher for direct path loads. Database operations work transparently against compressed objects, so no application changes are required.
Types of Hybrid Columnar Compression
If your underlying storage supports Hybrid Columnar Compression, then you can specify the following compression types, depending on your requirements:
To achieve warehouse or online archival compression, you must use direct path loads, ALTER TABLE . . . MOVE operations, or online table redefinition.
Hybrid Columnar Compression is optimized for Data Warehousing and decision support applications on Exadata storage. Exadata maximizes the performance of queries on tables that are compressed using Hybrid Columnar Compression, taking advantage of the processing power, memory, and Infiniband network bandwidth that are integral to the Exadata storage server.
Other Oracle storage systems support Hybrid Columnar Compression, and deliver the same space savings as on Exadata storage, but do not deliver the same level of query performance. For these storage systems, Hybrid Columnar Compression is ideal for in-database archiving of older data that is infrequently accessed.
Compression Units
Hybrid Columnar Compression uses a logical construct called a compression unit to store a set of rows. When you load data into a table, the database stores groups of rows in columnar format, with the values for each column stored and compressed together. After the database has compressed the column data for a set of rows, the database fits the data into the compression unit.
For example, you apply Hybrid Columnar Compression to a daily_sales table. At the end of every day, you populate the table with items and the number sold, with the item ID and date forming a composite primary key. Table 2-1 shows a subset of the rows in daily_sales.
Table 2-1 Sample Table daily_sales
|
Item_ID |
Date |
Num_Sold |
Shipped_From |
Restock |
|
1000 |
01-JUN-11 |
2 |
WAREHOUSE1 |
Y |
|
1001 |
01-JUN-11 |
0 |
WAREHOUSE3 |
N |
|
1002 |
01-JUN-11 |
1 |
WAREHOUSE3 |
N |
|
1003 |
01-JUN-11 |
0 |
WAREHOUSE2 |
N |
|
1004 |
01-JUN-11 |
2 |
WAREHOUSE1 |
N |
|
1005 |
01-JUN-11 |
1 |
WAREHOUSE2 |
N |
Assume that the rows in Table 2-1 are stored in one compression unit. Hybrid Columnar Compression stores the values for each column together, and then uses multiple algorithms to compress each column. The database chooses the algorithms based on a variety of factors, including the data type of the column, the cardinality of the actual values in the column, and the compression level chosen by the user.
As shown in Figure 2-5, each compression unit can span multiple data blocks. The values for a particular column may or may not span multiple blocks.
Figure 2-5 Compression Unit
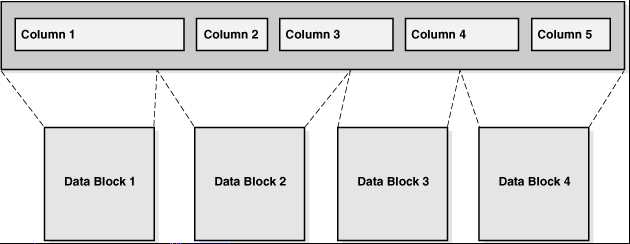
Description of "Figure 2-5 Compression Unit"
Hybrid Columnar Compression has implications for row locking (see "Row Locks (TX)"). When an update occurs for a row in an uncompressed data block, only the updated row is locked. In contrast, the database must lock all rows in the compression unit if an update is made to any row in the unit. Updates to rows using Hybrid Columnar Compression cause rowids to change.
Note:
When tables use Hybrid Columnar Compression, Oracle DML locks larger blocks of data (compression units), which may reduce concurrency.
Oracle Schema Objects——Tables——Table Compression
标签:loss var require from maximum save one img prim
原文地址:http://www.cnblogs.com/scentpath/p/TableCompression.html