标签:res sse logs plot .sh orm lua 绘图 type
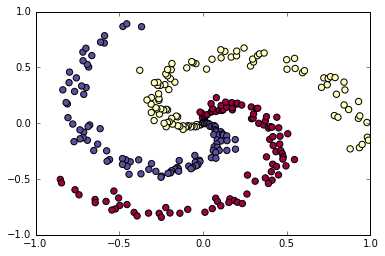
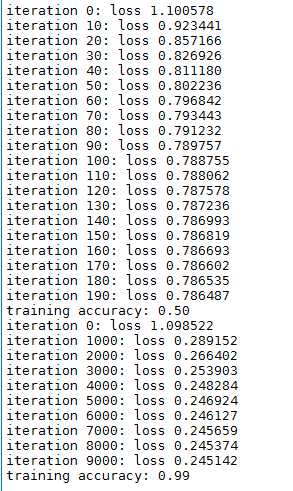
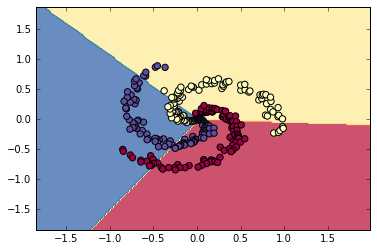
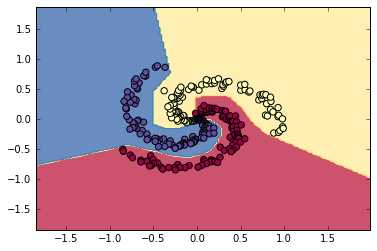
1 #CS231n中线性、非线性分类器举例(Softmax) 2 #注意其中反向传播的计算 3 4 # -*- coding: utf-8 -*- 5 import numpy as np 6 import matplotlib.pyplot as plt 7 N = 100 # number of points per class 8 D = 2 # dimensionality 9 K = 3 # number of classes 10 X = np.zeros((N*K,D)) # data matrix (each row = single example) 11 y = np.zeros(N*K, dtype=‘uint8‘) # class labels 12 for j in xrange(K): 13 ix = range(N*j,N*(j+1)) 14 r = np.linspace(0.0,1,N) # radius 15 t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta 16 X[ix] = np.c_[r*np.sin(t), r*np.cos(t)] 17 y[ix] = j 18 # lets visualize the data: 19 plt.xlim([-1, 1]) 20 plt.ylim([-1, 1]) 21 plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral) 22 plt.show() 23 24 25 26 # initialize parameters randomly 27 # 线性分类器 28 W = 0.01 * np.random.randn(D,K) 29 b = np.zeros((1,K)) 30 31 # some hyperparameters 32 step_size = 1e-0 33 reg = 1e-3 # regularization strength 34 35 # gradient descent loop 36 num_examples = X.shape[0] 37 for i in xrange(200): 38 39 # evaluate class scores, [N x K] 40 scores = np.dot(X, W) + b 41 42 # compute the class probabilities 43 exp_scores = np.exp(scores) 44 probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K] 45 46 # compute the loss: average cross-entropy loss and regularization 47 corect_logprobs = -np.log(probs[range(num_examples),y]) 48 data_loss = np.sum(corect_logprobs)/num_examples 49 reg_loss = 0.5*reg*np.sum(W*W) 50 loss = data_loss + reg_loss 51 if i % 10 == 0: 52 print "iteration %d: loss %f" % (i, loss) 53 54 # compute the gradient on scores 55 dscores = probs 56 dscores[range(num_examples),y] -= 1 57 dscores /= num_examples 58 59 # backpropate the gradient to the parameters (W,b) 60 dW = np.dot(X.T, dscores) 61 db = np.sum(dscores, axis=0, keepdims=True) 62 63 dW += reg*W # regularization gradient 64 65 # perform a parameter update 66 W += -step_size * dW 67 b += -step_size * db 68 69 # evaluate training set accuracy 70 scores = np.dot(X, W) + b 71 predicted_class = np.argmax(scores, axis=1) 72 print ‘training accuracy: %.2f‘ % (np.mean(predicted_class == y)) 73 74 # plot the resulting classifier 75 h = 0.02 76 x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 77 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 78 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), 79 np.arange(y_min, y_max, h)) 80 Z = np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b 81 Z = np.argmax(Z, axis=1) 82 Z = Z.reshape(xx.shape) 83 fig = plt.figure() 84 plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8) 85 plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral) 86 plt.xlim(xx.min(), xx.max()) 87 plt.ylim(yy.min(), yy.max()) 88 89 ## initialize parameters randomly 90 # 含一个隐层的非线性分类器 使用ReLU 91 h = 100 # size of hidden layer 92 W = 0.01 * np.random.randn(D,h) 93 b = np.zeros((1,h)) 94 W2 = 0.01 * np.random.randn(h,K) 95 b2 = np.zeros((1,K)) 96 97 # some hyperparameters 98 step_size = 1e-0 99 reg = 1e-3 # regularization strength 100 101 # gradient descent loop 102 num_examples = X.shape[0] 103 for i in xrange(10000): 104 105 # evaluate class scores, [N x K] 106 hidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation 107 scores = np.dot(hidden_layer, W2) + b2 108 109 # compute the class probabilities 110 exp_scores = np.exp(scores) 111 probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K] 112 113 # compute the loss: average cross-entropy loss and regularization 114 corect_logprobs = -np.log(probs[range(num_examples),y]) 115 data_loss = np.sum(corect_logprobs)/num_examples 116 reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2) 117 loss = data_loss + reg_loss 118 if i % 1000 == 0: 119 print "iteration %d: loss %f" % (i, loss) 120 121 # compute the gradient on scores 122 dscores = probs 123 dscores[range(num_examples),y] -= 1 124 dscores /= num_examples 125 126 # backpropate the gradient to the parameters 127 # first backprop into parameters W2 and b2 128 dW2 = np.dot(hidden_layer.T, dscores) 129 db2 = np.sum(dscores, axis=0, keepdims=True) 130 # next backprop into hidden layer 131 dhidden = np.dot(dscores, W2.T) 132 # backprop the ReLU non-linearity 133 dhidden[hidden_layer <= 0] = 0 134 # finally into W,b 135 dW = np.dot(X.T, dhidden) 136 db = np.sum(dhidden, axis=0, keepdims=True) 137 138 # add regularization gradient contribution 139 dW2 += reg * W2 140 dW += reg * W 141 142 # perform a parameter update 143 W += -step_size * dW 144 b += -step_size * db 145 W2 += -step_size * dW2 146 b2 += -step_size * db2 147 # evaluate training set accuracy 148 hidden_layer = np.maximum(0, np.dot(X, W) + b) 149 scores = np.dot(hidden_layer, W2) + b2 150 predicted_class = np.argmax(scores, axis=1) 151 print ‘training accuracy: %.2f‘ % (np.mean(predicted_class == y)) 152 # plot the resulting classifier 153 h = 0.02 154 x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 155 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 156 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), 157 np.arange(y_min, y_max, h)) 158 Z = np.dot(np.maximum(0, np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b), W2) + b2 159 Z = np.argmax(Z, axis=1) 160 Z = Z.reshape(xx.shape) 161 fig = plt.figure() 162 plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8) 163 plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral) 164 plt.xlim(xx.min(), xx.max()) 165 plt.ylim(yy.min(), yy.max())
运行结果
【Python 代码】CS231n中Softmax线性分类器、非线性分类器对比举例(含python绘图显示结果)
标签:res sse logs plot .sh orm lua 绘图 type
原文地址:http://www.cnblogs.com/xiangfeidemengzhu/p/7146745.html