标签:src bsp ace 方便 -128 div 换行 字符 命名
需求:爬取豆瓣小组所有话题(话题title,内容,作者,发布时间),及回复(最佳回复,普通回复,回复_回复,翻页回复,0回复)

解决:1. 先爬取小组下,所有的主题链接,通过定位nextpage翻页获取总过700+条话题;
2. 访问700+ 链接,在内页+start=0中,获取话题相关的四部分(话题title,内容,作者,发布时间),及最佳回复、回复;
3. 在2的基础上,判断是否有回复,如果有回复才进一步判断是否有回复翻页,回复翻页通过nextpage 获取start=100、start=200的页;
4. 进入下一个爬取函数,将抓取的回复 续写 到2 中的文件;
解决思路:
Before:一开始建立2个文件,article.txt 用来存储所有话题相关的内容(700+话题、作者信息);
同时,建立以title命名的回复文件;
After: 统一建立以话题title命名的文章,先写入文章相关内容,再续写回复;这样方便读取;
遇到的坑:
1. 要获取某个div下直接的text,div.span下的text,div.h下的text:
——有2个解决方法:
A. 通过xpath //text,意思是获取div 下的所有text文件;

B. 通过css 拼接,逗号隔开即可:
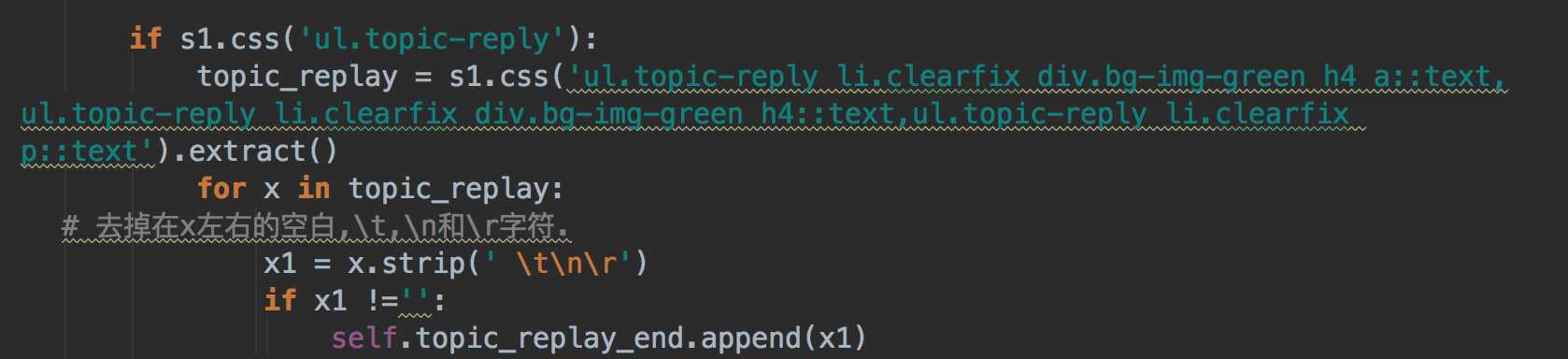
2. 巩固了不同函数之间通过meta传递参数的方法:

3. python open file with a variable name
f = open(‘%s.txt‘ % title_end,‘a‘)
a: 续写

4.去掉 str 中的空格,换行等符号
# 去掉在x左右的空白,\t,\n和\r字符.
x1 = x.strip(‘ \t\n\r‘)
5 . strip 去掉数据中的\r,‘‘.join 将列表转回字符串;
# 先将文章中的\r 都去掉,有些单独的‘\r‘ 就变成了空的列表元素:‘‘,再用if 来判断下就好了
artical_end = []
for x in article:
x1 = x.replace(‘\r‘,‘‘)
if x1 != ‘‘:
artical_end.append(x1)
# 将artical_end 列表 转为字符串
ar =‘‘.join(artical_end)
python爬取豆瓣小组700+话题加回复啦啦啦python open file with a variable name
标签:src bsp ace 方便 -128 div 换行 字符 命名
原文地址:http://www.cnblogs.com/vivivi/p/7156439.html