标签:javascript
part1 ---------------------------------------------------------------------------------------------------------
这两天看了一下TOM大叔的《深入理解js系列》中的基础部分,根据自己的实际情况,做了读书笔记,记录了部分容易绊脚的问题。写篇文章,供大家分享。
var divs = document.getElementsByTagName("div"), i; for (i = 0; i < divs.length; i++) { //…… }
以上代码中,会出现性能问题。问题就在于divs是一个HTMLCollection类型的对象,这种类型在每次获取数据时,都会再重新从dom中分析计算。因此,这里的for循环中,每一步循环都会执行一次divs.length的计算,都会令浏览器再重新遍历一遍dom树。
所以,应该在循环之外,早早的计算出divs的length属性值。如下:
var divs = document.getElementsByTagName("div"), i, length = divs.length; for (i = 0; i < length; i++) { //…… }
var obj = { a: 10, b: 20 }; // 注意词句代码 Object.prototype.c = 30; var item; for (item in obj) { console.log(item); }
以上代码中,注意中间标注释的句子。这句代码加与不加,会对下面的for..in..循环产生影响。加上了就输出“c”,不加就不输出“c”。道理很简单,for..in..循环不光能遍历obj对象本身就有的属性,还能遍历obj原型中的属性。
要想屏蔽掉原型中的属性,就用hasOwnProperty函数,如下:
for (item in obj) { if (obj.hasOwnProperty(item)) { //if (Object.prototype.hasOwnProperty.call(obj, item)) { console.log(item); } }
这两句if判断语句,都可以用,效果是一样的。第一个代码可读性好,第二个效率相对较高。建议,没有特殊情况,用第一个即可。
var events = [], i = 0; //循环创建函数 for (; i < 10; i++) { events[i] = function () { console.log(i); }; } //验证结果 for (i = 0; i < events.length; i++) { events[0](); }
先看以上代码,有js开发经验的人肯定都很熟悉,但是有的人知道,有的人不知道。依照以上代码,循环遍历events数组,执行数组元素中的函数,这10个函数都会打印出什么数字?答案是:全都会输出“10”。下面解释一下原因:
在每个函数生成/被创建时,系统都会给它分配一个变量的环境,这个环境中也包括闭包的数据。但是,当多个环境,公用一个闭包的数据时,是一种引用的关系,这是重点。引用,不是复制。如果改变了这个公用数据,这些公用的环境获取时,也是改变后的数据。
所以,在创建第一个函数时,i === 0,第一个函数引用的闭包中i的值就是0;第二个函数被创建时,i === 1,这是,第一个、第二个两个函数应用闭包中i的值,都是1。以此类推,直到第十个函数创建时,i === 9;但是在for循环的最后一步,又执行了 i++;所以i === 10。
明白了吗?
想要改变这个问题,想要每个函数都输出不同的数值,那就需要不让每个函数都公用一个闭包——让每个函数使用单独的闭包数据,不共享。只需讲for循环创建函数的部分修改为:
//循环创建函数 for (; i < 10; i++) { events[i] = (function (index) { return function (index) { console.log(index); } })(i); }
此时,i作为参数,传入匿名自动执行函数,赋值给index参数。这个匿名函数的变量环境,就把index保存了下来,而不会随着i的变化而变化。这就是要点。
欢迎关注微博:weibo.com/madai01
part2-----------------------------------------------------------------------------------------------------------
昨天写了《js便签笔记(11)——浏览TOM大叔博客的学习笔记 part1》,简单记录了几个问题。part1的重点还是在于最后那个循环创建函数的问题,也就是多个子函数公用一个闭包数据的问题。如果觉得有兴趣,可以再重新翻出来看看。
今天继续把剩下的问题写完。
学js的人,即使初级入门的也都知道“原型链”,但是“作用域链”,可能好多人没有听说过。大部分人都知道或者听说过“闭包”,但是可能有好多人不知道闭包其实和作用域链有莫大的联系。如果理解闭包不从作用域链开始理解,那么你就只能理解闭包的皮毛。
我也是从TOM大叔的这些博客中才了解到作用域链的,之前也看过了许多本书籍,都没有很清晰的展开作用域链这个概念。其实作用域链简单说来也好理解,如下代码:
var x = 10; function fn() { var y = 20; return function () { var z = 30 console.log(x + y + z); } }
上面代码中,如果想要打印 x+y+z 的值,就必须要遍历三个层次的上下文环境或者作用域,这其实和原型链的结构表现形式类似。但要细细将来,连同闭包图文并茂的说明白,需要很多内容。
此处不再深入进去,以后有机会再另起一篇详细介绍。
上文讲到通过作用域练向上查找变量,实际在查找变量的过程中,是使用“二维链查找”——“作用域链” + “原型链”。看如下代码:
Object.prototype.x = 10; function fn() { var y = 20; return function () { var z = 30 console.log(x + y + z); } }
这份代码跟上文中演示作用域链的代码差不多,但是它却通过 Object.prototype.x = 10; 这么一句话,表现出了原型链在其中的作用。
因此,在查找变量值时,是同时兼顾原型链和作用域链两个方向的,即“二维链查找”。
这句话的下半句是——不能通过if/for等语句块来创建。后半句大家可能知道,但是它的本质确实前半句——独立作用域只能通过函数来创建(除了独立作用域之外,剩下的就是全局作用域)。既然独立作用域只能通过函数来创建,那么函数中任何地方的自由变量就都是函数层级的,因此,以下代码希望不要再次出现:
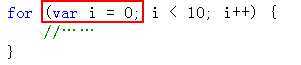
var a = 10; b = 20;
以上两句代码,看似都是声明两个全局变量,但是按照TOM大叔说的,只有var才能声明一个变量,也就是 var a = 10; 是真正的声明变量。
而下一句 b = 20,其实是相当于设置window的一个属性值而已。
因此,第一句的本质是声明一个全局变量;第二句的本质是设置window的一个属性值。
当然,不推荐用第二句的形式。
js定义函数的方法有多种,但看看以下这段代码:
fn(); var fn = function() { //函数表达式 alert(123); // 报错 } //------ fn(); function fn() { //函数声明 alert(123); // 123 }
两种函数定义方式,却得出不一样的结果。
此处我当时没有详细看,因为这样使用的情况不是很多,所以就没有过深入的细看,只是做了个标记。如果有了解的朋友,不放解释一下。
在part1中讲过,当一个函数作为参数被传入,后者作为一个值被返回的时候,连同它一块被传递的,是它的作用域。也就是咱们常说的闭包。且看如下代码:
var x = 10; function foo() { alert(x); } (function (funarg) { var x = 20; funarg(); // 10, 不是20 })(foo);
foo是一个函数,把它作为参数传入进另一个函数中执行,连同一起传递的,是foo的作用域。而foo使用的是静态作用域,其中的变量x在传递的时候已经被静态赋值,不会受其他环境下x变量的影响。
这个道理也同样适用于函数作为返回值。如下:
function fn() { var x = 10; return function () { alert(x); } } var ret = fn(); var x = 20; ret(); // 10,不是20
更多内容请关注我的微博
标签:javascript
原文地址:http://blog.csdn.net/wangfupeng1988/article/details/38984681