标签:算法 之间 显示 put create items 技术分享 没有 数据
简单地说,k-近邻算法采用测量不同特征值之间的距离方法进行分类。
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数值型和标称型
存在一个训练样本集,并且每个样本都存在标签(有监督学习)。输入没有标签的新样本数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取出与样本集中特征最相似的数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,而且k通常不大于20。最后选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
以电影分类为例子,使用k-近邻算法分类爱情片和动作片。有人曾经统计过很多电影的打斗镜头和接吻镜头,下图显示了6部电影的打斗和接吻镜头数。 假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?

①首先需要统计这个未知电影存在多少个打斗镜头和接吻镜头,下图中问号位置是该未知电影出现的镜头数

②之后计算未知电影与样本集中其他电影的距离(相似度),具体算法先忽略,结果如下表所示:
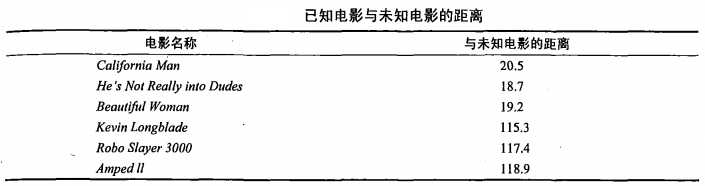
③将相似度列表排序,选出前k个最相似的样本。此处我们假设k=3,将上表中的相似度进行排序后前3分别是:He’s Not Really into Dudes,Beautiful Woman,California Man。
④统计最相似样本的分类。此处很容易知道这3个样本均为爱情片。
⑤将分类最多的类别作为未知电影的分类。那么我们就得出结论,未知电影属于爱情片。
2、k-近邻简单分类的应用
2.1 算法一般流程

2.2 Python实现代码及注释
# -*- coding:utf-8 -*- import numpy as np def createDataSet(): dataSet = np.array([[1,1,1,1], [2, 2, 2,3], [8, 8,8,9], [9, 9, 9,8]]) label = [‘A‘, ‘A‘, ‘B‘, ‘B‘] return dataSet, label def classify(input, dataSet, label, k): dataSize = dataSet.shape[0] diff = np.tile(input, (dataSize, 1)) - dataSet sqdiff = diff ** 2 squareDist = np.sum(sqdiff, axis=1) dist = squareDist**0.5 sortDistIndex = np.argsort(dist) classCount = {} for i in range(k): votelabel = label[sortDistIndex[i]] classCount[votelabel] = classCount.get(votelabel, 0) + 1 max = 0 for key, value in classCount.items(): if max < value: max = value classes = key return classes
参考:http://www.cnblogs.com/hemiy/p/6155425.html
标签:算法 之间 显示 put create items 技术分享 没有 数据
原文地址:http://www.cnblogs.com/lovephysics/p/7230702.html