标签:一个 mysq b+树 触发器 字段 分块 isa 无法 mysql
一,索引
1.Innodb索引使用的是B+树
2.尽量简化where条件,比如不要出现 where id + 3 = 5,这无法使用索引
3.索引很大时,可以冗余一列来模拟哈希索引
4.小的表不需要使用索引,很大的表需要用分块技术,也不用索引
5.索引的选择性=不重复的数量/总的数量
选择性越高,效率越高,unique索引选择性为1,效率最好
对于blob,text,很长的varchar类型的列,必须使用前缀索引。
诀窍在于,要选择足够长的前缀以保证较高的选择性,同时又不能太长
创建前缀索引:(city列里长度为7的前缀索引)
alter table sakila.city_demo ADD KEY(city(7))
前缀索引的缺点,无法做ORDER BY和GROUP BY
后缀索引:mysql不支持反向索引,但可以把字符串反转后存储,并基于此建立索引,可以通过触发器来维护索引
6、多列索引
对多个列做相交操作(and)时,需要的时一个多列索引而不是多个单独的单列索引
如果在explain中看到有索引合并,应该好好检查一下查询和表单结构,
可以通过参数optimizer_switch来关闭索引合并
7.覆盖索引
如果一个索引包含所有需要查询的字段的值,我们就称之为覆盖索引
由于myISAM在内存中只存索引,所以用覆盖索引有严重的性能问题
由于InnoDB的聚簇索引,覆盖索引对InnoDB特别有用
另外,只能用B-tree索引做全文索引
当使用覆盖索引时,EXPLAIN 中的Extra中显示Using index
查询优化
一般的优化方法有两个
1.确认应用程序是否在检索大量超过需要的数据,这通常意味着访问了太多的行
但有时候也可能是访问了太多的列
2.确认MySQL服务器层是否在分析大量超过需要的数据行
解决方法,加limit,
如果数据库资源紧张,可以考虑用mybatis代替hibernate
取出全部列,会让优化器无法完成覆盖索引扫描这类优化,比如hibernate
不过获取所有列的查询缓存,比多个独立的只获取部分列的查询缓存更有好处
每次看到select * 请去怀疑一下是否真的需要全部取出
重复查询相同的数据:请把这个数据缓存起来,比如放到session中
最简单的衡量查询开销的三个指标:
响应时间,
扫描的行数
返回的行数
这三个指标都会记录到mysql的慢日志中,所以检查慢日志
如果发现查询需要扫描大量的数据行,但返回少量的行,那么可以尝试下面的技巧去优化它
1,使用索引覆盖扫描,把所有需要用的列都放到索引中
2.改变表结构,例如使用单独的汇总表
3.重写这个查询,各种优化
有时可以考虑将一个复杂查询分为多个小查询,如果能减少工作量的话
比如删除旧的数据,每次删一点,可以避免一次锁住很多数据
分解关联查询的好处
1、缓存效率更高
2、用返回的数据的id来进行顺序查询比用join进行随机关联效率更高
坏处:一条语句分多条,增加连接开销
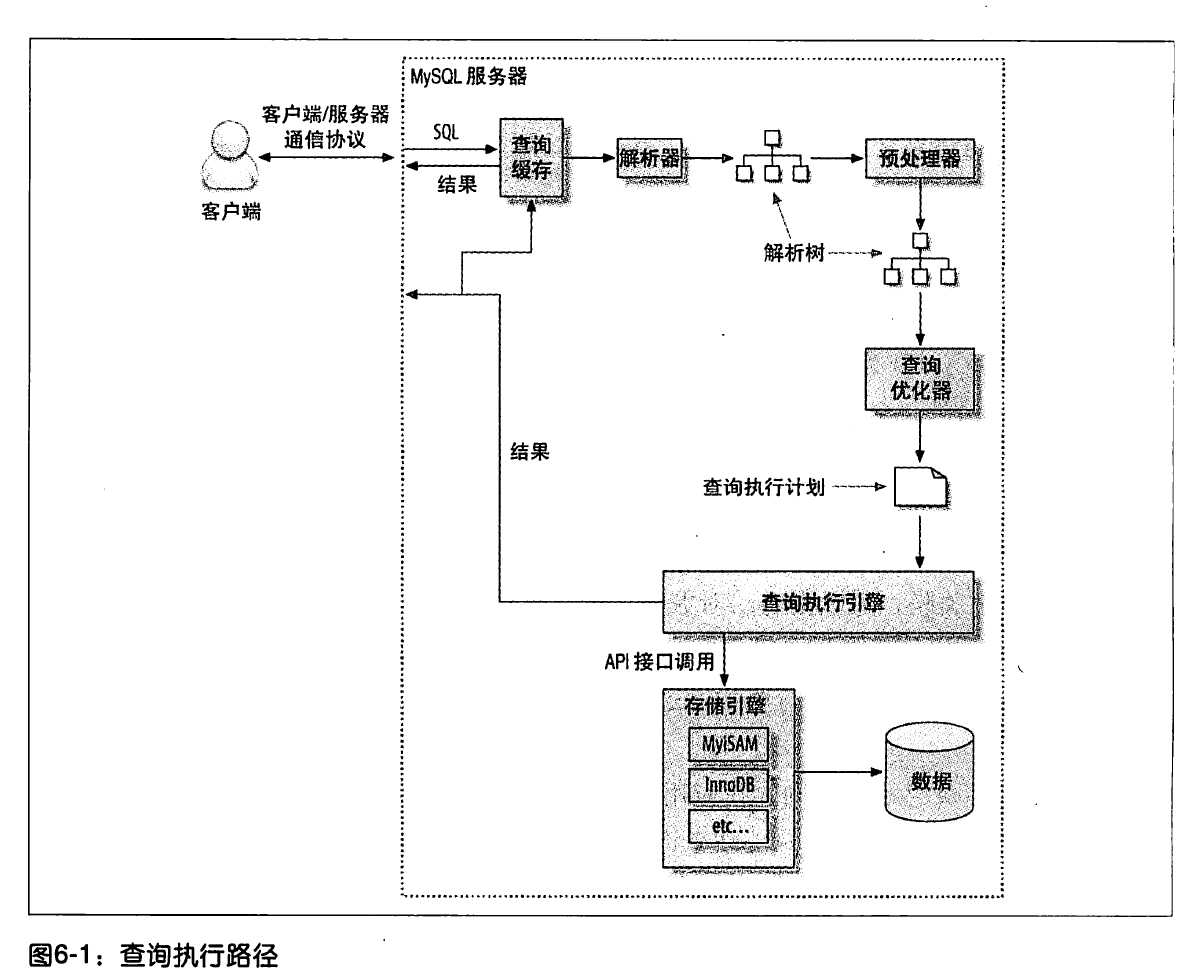
排序优化
无论如何,排序都是一个成本很高的操作,所以从性能角度考虑,尽可能避免排序,或避免对大量数据进行排序
标签:一个 mysq b+树 触发器 字段 分块 isa 无法 mysql
原文地址:http://www.cnblogs.com/lakeslove/p/7238746.html