标签:utf-8 visitor lte 页面 udev git youtube 5.0 str
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息。通过分析YouTube,可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类,之后进入到每个分类下的视频列表,最后在具体到每一个视频,获取需要的信息。以订阅号YouTube 电影为例。
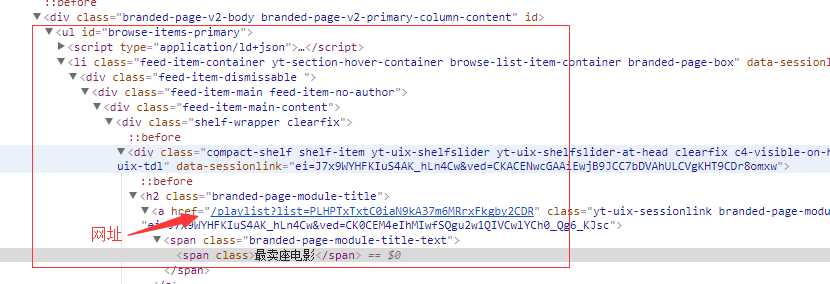
打开订阅号,我们可以发现订阅号下有许多视频分类如下图所示,接下来可以解析该订阅号信息,把视频分类的URL和名称爬取下来。

接下来我们通过浏览器点击检查查看网页,分析下如何获取分类,可以发现所有的视频分类都在ul 下的 li 里面,通过ul的id 我们便可以找到分类的相关信息,因此我们可以利用cheerio模块来解析页面,从而获取分类信息。
先将获取分类信息的相关代码分装成一个函数function categoryList (url , callback){},代码如下:
var request =require(‘superagent‘);
require(‘superagent-proxy‘)(request);
var cheerio = require(‘cheerio‘);
var debug = require(‘debug‘)(‘youtube:test:category-list‘);
var proxy = ‘http://127.0.0.1:61481‘;//设置代理IP地址
//请求头信息
var header = {
‘Accept‘:‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8‘,
‘Accept-Encoding‘:‘gzip, deflate, sdch, br‘,
‘Accept-Language‘:‘zh-CN,zh;q=0.8,en;0.6‘,
‘Cookie‘:‘WKcs6.resume=; _ga=GA1.2.1653214693.1476773935; _gid=GA1.2.943573022.1500212436; YSC=_X6aKoK1jMc; s_gl=1d69aac621b2f9c0a25dade722d6e24bcwIAAABVUw==; VISITOR_INFO1_LIVE=T3BczuPUIQo; PREF=hl=zh-CN&cvdm=grid&gl=US&f1=50000000&al=zh-CN&f6=1&f5=30; SID=7gR6XOImfW5PbJLOrScScD4DXf8cHCkWCkxSUFy9CbhnaFaPLBCVCElv97n_mjWgkPC_ow.; HSID=A0_bKgPkAZLJUfnTj; SSID=ASjQTON7p_q4UNgit; APISID=ZIVPX9a3vUKRa28E/A0dykxLiVJ4xDIUS_; SAPISID=t6dcqHC9pjGsE7Bi/ATm5wgRC27rqUQr5B; CONSENT=YES+CN.zh-CN+20160904-14-0; LOGIN_INFO=APUNbegwRQIhAPnMZ-qYHOSAKq0s9ltEQIUvnWNj9CHQ8J5s2JtZK15TAiBLzfS4HEUh-mWGo2Qo6XOruItGRdpPZ2v3cXLqYY7xtA:QUZKNV9BajdRR2VZQ2QyRlVDdXh3VDdKZ1AzMlFqRmg3aTBfR2pxWXFHWXlXYm1BaVVnQWk4UzZfWmZGSGcxRkNuTDBFYTk2a2tKLUEtNmtNaWZKM3hTMWNTZkgyOVlvTF9DNENwTG5XTlJudEVHQzVIeGxMbTFTdkl6YS02QlBmMmM0NVgteWI3QVNIa3c5c2ZkV1NSa3AzbWhwOHBtbzVrVTVSbTBqaWpIZ0dWNTd4UjJRSllr‘,
‘Upgrade-insecure-requests‘:‘1‘,
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36‘,
‘X-Chrome-Uma-Enabled‘:‘1‘,
‘X-Client-Data‘:‘CJa2yQEIorbJAQjBtskBCKmdygE=‘,
‘Connection‘: ‘keep-alive‘
};
//获取订阅号下视频分类列表
function categoryList (url , callback){
debug(‘读取订阅号下视频分类列表‘,url);
request
.get(url)//需要获取的网址
.set(‘header‘,header)
.proxy(proxy)
.end(onresponse);
function onresponse(err,res){
//res.setEncoding(‘utf-8‘); //防止中文乱码
if(err){
return callback(err);
}else{
console.log(‘status:‘+res.status);//打印状态码
//console.log(res.text);
var $ = cheerio.load(res.text);
//获取订阅号Id
var $channelName = $(‘#c4-primary-header-contents .branded-page-header-title a‘).attr(‘href‘);
var $channelId = $channelName.match(/channel\/([a-zA-Z0-9_-]+)/);
var categoryList = [];
$(‘#browse-items-primary .branded-page-module-title‘).each(function(){
var $category = $(this).find(‘a‘).first();
var item = {
name : $category.text().trim(),
url : ‘https://www.youtube.com‘ + $category.attr(‘href‘)
};
//根据URL判断为订阅号或者是视频分类
if(item.url.indexOf(‘list‘)!==-1){
item.channelId = $channelId[1];
}else{
var s = item.url.match(/channel\/([a-zA-Z0-9_-]+)/);
item.id = s[1];
}
//获取youtube某个订阅号下的视频分类
if(item.name!==‘‘){
categoryList.push(item);
}
});
callback(null,categoryList);
}
}
}
接着调用categoryList函数:
categoryList(‘https://www.youtube.com/channel/UClgRkhTL3_hImCAmdLfDE4g‘,function(err,categoryList){
if(err){
return console.log(err);
}
return console.log(categoryList);
});
在后台运行就得到了视频分类信息,这是会发现视频分类里面又包含了某些订阅号,而我们只需要提取视频分类。
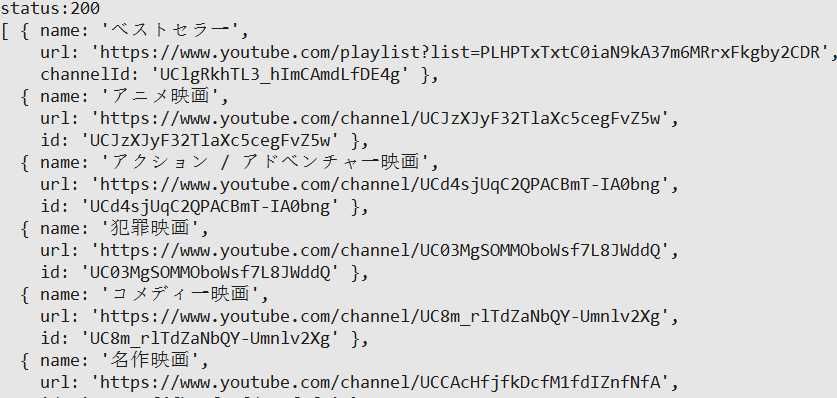
去除订阅号信息(当然也可以添加到订阅号列表,然后再依次读取订阅号下的视频分类)
//获取youtube某个订阅号下的视频分类
if(item.name!==‘‘){
categoryList.push(item);
}
替换为
//获取youtube某个订阅号下的视频分类
if(item.categoryName!==‘‘&&item.hasOwnProperty(‘channelId‘)){
categoryList.push(item);
}
这是再运行会发现订阅号的信息已经剔除了,接下来进入到下一层,通过视频分类获取视频列表
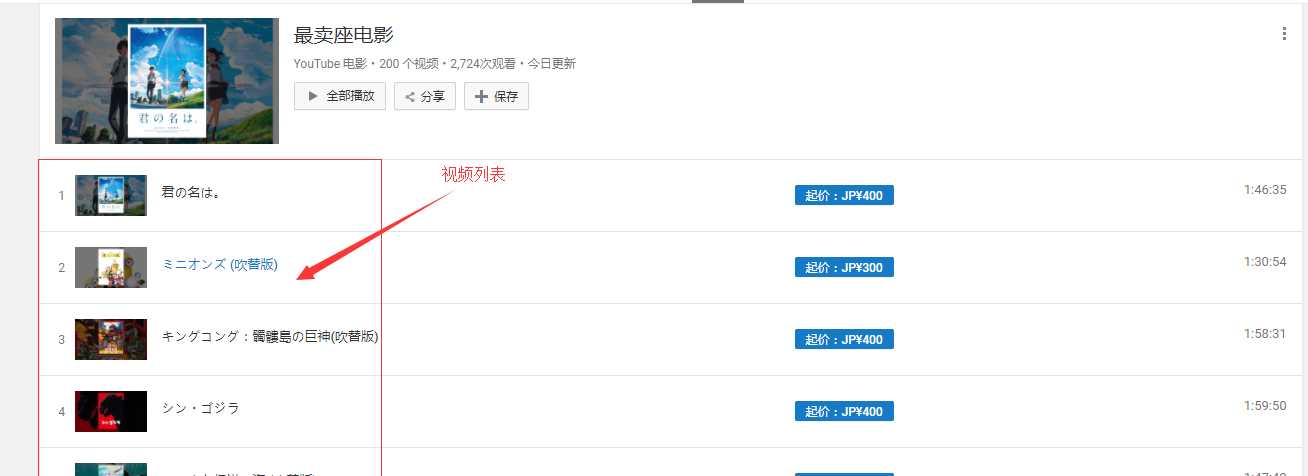
我们以最卖座电影为例,获取其下面的视频列表。点击打开页面,我们会发现该分类下视频列表全部在在里面,我们同样只获取其url 以及名称。
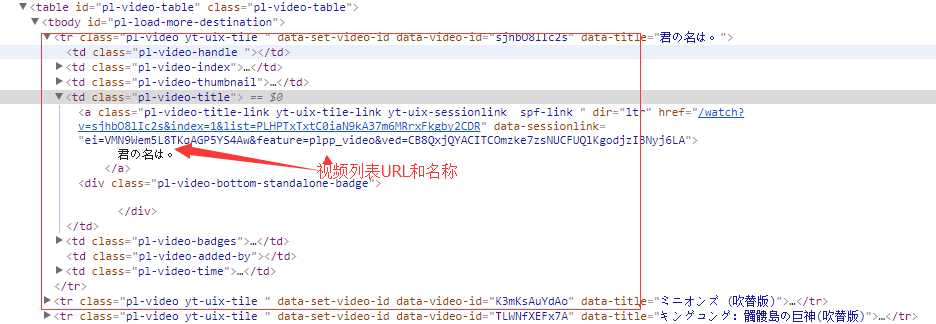
点击检查(ps:我用的Google浏览器),先查看下网页结构,再用cheerio进行解析。检查发现我们可以通过tbody中的tr获取每个视频。
标签:utf-8 visitor lte 页面 udev git youtube 5.0 str
原文地址:http://www.cnblogs.com/xiaxuexiaoab/p/7260037.html