标签:mina mount 公钥 author 重复 多对多 mongodb nts exe
本文从以下四个方面对mongodb进行介绍
一、聚合操作(aggregate operation)
二、文本搜索(text search)
三、数据模型 (DATA MODELS)
四、数据库安全(security)
一、聚合操作
组合多个数据记录,对分组数据记录进行多种操作,最终返回一个单一的结果
实现方式:聚合管道、map-reduce、单用途聚合方法
1、聚合管道
聚合管道是基于数据处理管道模型上的。数据记录经过 多个阶段的管道 最终被转换为聚合结果集。
最基本的过滤管道提供了改变数据集输出形式的过滤功能。另外、还提供了对documents进行分组、排序的功能。
聚合管道可以使用index对聚合操作进行优化。
例如:
db.col.aggregate([ {$match:{status:‘A‘}} {$group:{_id:‘$title‘,total:{$sum:"$amount"}}} ])
此聚合管道函数、分为两个阶段:
1.match stage - 匹配阶段 :找到所有status=A的documents
2.group stage - 分组段:以match阶段的结果集为输入,以title域分组并统计相应的amount
聚合管道优化
1.投影优化
即使用投影来获取所有fields的一个自己,以减少进入管道的数据量,实现优化
2.管道序列优化
$sort 和 $match优化如下
{ $sort: { age : -1 } },
{ $match: { status: ‘A‘ } }
应修改为:
{ $match: { status: ‘A‘ } },
{ $sort: { age : -1 } }
先过滤、再排序,减少排序阶段的数据量
$skip和$limit优化
{ $skip: 10 },
{ $limit: 5 }
修改为:
{ $limit: 15 },
{ $skip: 10 }
减少了进入skip阶段的数据量
$project 和$skip或$limit优化
$skip和$limit应该放在$project阶段之前
总结:序列优化的原则是,将能减少数据量的stage放在不能减少数据量的stage的前面,将减少数据量多的stage放在减少数据量少的stage。
3.管道合并优化
在可能的情况下,优化阶段会将一个管道阶段合并到它之前的管道阶段。通常情况下,管道合并会发生在 序列重排序优化之后。
$sort 和 $limit
当$sort在$limit之前的时候,优化器可以将$limit合并到$sort阶段。$sort阶段仅仅会持有$limit指定的前n个ducuments,MongDB只需要在内存中持有n项documents。
注:$sort阶段在有100M的内存限制,如果进入此阶段的数据容量超过了100M,$sort会产生一个错误信息。当然,我们也可以修改相关配置项。
$limit和$limit
多个$limit会自动合并为一个。Limit为个stage中最小的那个值。
$skip和$skip
会合并为$kip指定值的总和
$match和$match
会使用$and操作符合并为一个管道阶段
聚合管道限制
1.结果集大小限制
从mongodb2.6开始,aggregate命令会返回一个游标或者在collection中存储结果。返回结果中的每一个document(一条数据记录)都服从 BSON Document Size 设置(目前是16M)。如果有document超过了限制,聚合命令就会出错。这种限制只作用在最终返回中的结果集,对于管道操作的中间过程,documents可以超过这个限制。[ mongodb>2.6,aggregate默认返回一个游标(指针)]
2.内存限制
从mongodb2.6开始,管道阶段处理的数据集有100M的限制。可以使用allowDiskUse进行内存限制的设置,使聚合管道stage可以把数据写到临时文件。
聚合管道与分片集合
1.行为
2.优化
2、map-reduce
Map-Reduce是个将大批量数据压缩为有用聚合结果集的数据处理范例。
mongodb也提供了map-reduce操作来实现对documents的聚合。
map-reduce大致分为两个阶段
map阶段:处理所有文档、为每个文档映射出一个或多个对象
reduce阶段:对映射操作的输出结果进行组合
map-reduce 还有一个可选的最终阶段、来对结果进行修改。如:指定查询条件、对结果进排序和限制。
和聚合管道相比,使用定制型的avascript 的map-reduce具有更大的灵活性,但是更加的复杂和低效。
以下是Map-reduce执行过程图(摘自mongo官网)
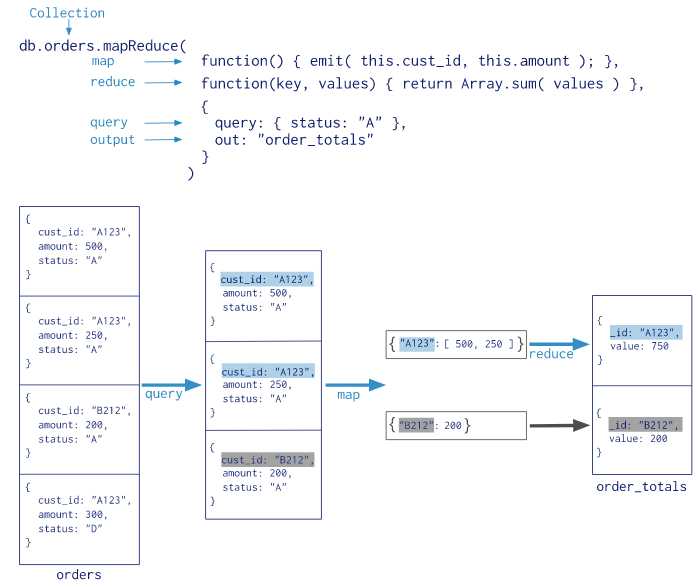
Map-Reduce JavaScript Funcitons
Map-reduce使用自定义javascript函数,将值映射、关联到键上。如果一个键对应过个值,reduces操作会将多个键值对合并为一个对象。
可以对map、reduce的操作结果,使用自定义函数来执行额外的计算等功能。
Map-Reduce Behavior
Map-reduce操作可以将其操作结果写入一个collection,也可以返回一个联机的结果。
如果写到collection,你可以对之前map-reduce的结果集,执行进一步的map-reduce操作。
如果以联机的形式返回结果,要求每个document<BSON Documetn Size(16M)。
Map-reduce操作也是支持sharded collction。
Map-reduce分片集合
Map-reduce并发
Map-reduce由多个任务组成,包括、读取输入集合、执行map、执行reduce、把集合写入临时集合、把结果写入输出集合。
在操作执行期间,map-reduce持有一下锁:
--读阶段,持有读锁。每100个documents会生成一个读锁。
--写入临时集合操作持有一个写锁。
--如果输出集合不存在,那么输入集合的操作会持有一个写锁。
--如果输出集合存在,输出操作(合并、替换、缩减)会持有一个写锁。这个写锁是全局锁,会锁定mongod的所有操作。
增量式Map-reduce
在map-reduce数据集不断增长的时候,我们可能想执行增量式的map-reduce,而不是每次都执行所有的数据集。
首先,要把map-reduce结果写入一个单独的collection
其次,当有更多的数据需要处理的时候,执行subsequent map-reduce任务:
查询条件仅仅指定新增的documents
Out参数中的aciton指定为:reduce,这样后来执行的map-reduce结果会和已经存在的collection共同执行reduce函数、并进行结果集的合并。
Troubleshoot the Map Function
Troubleshoot the Reduce Function
3、单用途聚合操作
mongodb还提供了 db.collection.count() db.collection.distinct() 实现对聚合过程的简单访问。
二、文本搜索
1.Text indexes
文本索引(t-i)可以包含任何值为String、或者元素为String的数组的域。
一个collection只能拥有一个text index,但是一个t-i可以包含几个域。如:
db.stores.createIndex( { name: "text", description: "text" } )
2.Text search operateors
使用$text操作符,对拥有t-i的collection执行文本搜索。
$text会将大部分的空格和标点符号作为定界符。如:
db.stores.find( { $text: { $search: "java coffee shop" } } )会搜索包含 java 、coffee、shop的条目。
使用$meta 查询操作符来获取text search与每条document的匹配分数:
db.stores.find(
{ $text: { $search: "coffee shop cake" } },
{ score: { $meta: "textScore" } }
).sort( { score: { $meta: "textScore" } } )
3.Text search in the aggeregation pipeline
Mongodb2.6开始,可以在聚合管道的$match阶段使用$text查询操作符进行文本搜索。
使用限制:
1.$match stage必须是管道的第一个阶段。
2.Text操作符只能出现一次
3.Text操作符不能出现在$or 、$not 表达式中
4.在$sort阶段使用$meta聚合表达式
文本匹配分数:
$text操作符给document指定了一个score。Score代表了document和text search的匹配程度。
$meta操作符只可以出现在包含$text的$match阶段之后。
db.articles.createIndex( { subject: "text" } )
计算包含cake的subject的views总量:
db.articles.aggregate(
[
{ $match: { $text: { $search: "cake" } } },
{ $group: { _id: null, views: { $sum: "$views" } } }
]
)
使用score排序:
db.articles.aggregate(
[
{ $match: { $text: { $search: "cake tea" } } },
{ $sort: { score: { $meta: "textScore" } } },
{ $project: { title: 1, _id: 0 } }
]
)
对Text score做匹配和过滤:
db.articles.aggregate(
[
{ $match: { $text: { $search: "cake tea" } } },
{ $project: { title: 1, _id: 0, score: { $meta: "textScore" } } },
{ $match: { score: { $gt: 1.0 } } }
]
)
指定文本搜索语言:
db.articles.aggregate(
[
{ $match: { $text: { $search: "saber -claro", $language: "es" } } },
{ $group: { _id: null, views: { $sum: "$views" } } }
]
)
4.Text search with basis technology rosette linguistics platform
(mongodb企业版提供了额外的文本搜索语言:其中有简体中文、繁体中文)详细使用信息参考官网。
5.Text search languages
三、数据模型 DATA MODELS
在MongoDB中,collections不会强制document 的结构。这种灵活性,给了我们可以选择的数据模型,以适应我们特定的应用程序与性能需求。
1.Data modeling introduction
Document structure
数据模型设计的关键是documents的结构和如何表示数据之间的关系。Mongodb中使用引用文档和嵌入文档来表示这些关系。
写操作的原子性
MongDB中,在document级别,写操作是原子性的。一个单独的写操作不会对多个documents或者collection产生原子性的影响。
非规范化的嵌入文档数据将代表一个实体的相关数据组合成了一个实体,这有助于对实体进行原子性的插入、更新操作。然而,规范化的数据会将一个实体的数据分布在多个collection里面,需要同时进行多项写入、更新操作,这样并不能保证对一个实体的原子性操作。
document growth
向数组增加元素或者新增域的操作都会增加document的大小。
对于MMAPv1存储引擎来说,document的大小超过了设定的空间,mongodb会在硬盘上重新安置document。
数据的使用和性能
设计数据模型之前,首先要考虑应用程序会如何使用我们的数据库。如,colleciton主要用于读取查询操作,那么添加索引就可以提高数据访问性能。
2.Document validation
可以通过validator选项来设置验证规则.
文档验证设置形式如下:
db.runCommand( {
collMod: "contacts",
validator: { $or: [ { phone: { $exists: true } }, { email: { $exists: true } } ] },
validationLevel: "moderate"
} )
Behavior
验证发生在更新、插入操作期间。当对collection增加验证的时候,已经存在的documents不会执行验证检查,直到有数据被修改。
existing documents
可以通过validationLevel 选项,控制mongodb如何处理documents
默认,validationLevel 是 strict。Mongodb会对所有已经存在的documents,inserts and updates应用验证规则。
validationLevel = moderate,只会对已经存在的documents中满足验证规则的documents进行验证。不会检查不符合验证规则的documents。
不合法documents的接受和拒绝
validationAction选项,决定mongdoDB如何处理违反验证的documetns。
默认,validationAction=error,MongoDB会阻止所有违反验证的documents。
validationAction=warn,MongoDB只在日志中记录不合法的验证,不会阻止documents的插入和更新操作。
日志会记录下失败验证操作的命名空间、colleciton、document,还有执行的时间如:
2015-10-15T11:20:44.260-0400 W STORAGE [conn3] Document would fail validation collection: example.contacts doc: { _id: ObjectId(‘561fc44c067a5d85b96274e4‘), name: "Amanda", status: "Updated" }
Restrictions
不能对admin、local、config数据库使用validator。
不能对system.* collection使用validator。
绕开document验证
使用bypassDocumentValidation选项,来绕开document验证。
对于开启安全验证的数据库,用户必须要拥有bypassDocumetnValidation权限。内建的角色只有dbAdmin和restore提供了这个权限。
2.数据模型概念Data modeling concepts
模型设计(Data Model Design)
要考虑不同数据模型的优势与劣势,以根据事实需要选择不同的策略。
有效的数据模型能更好的支撑应用的需求。Document结构的设计关键是,使用嵌入型(非规范化)、还是引用型documents(规范化)。
嵌入式数据模型

嵌入式数据模型允许程序把相关的一组信息存储到一条数据库记录中。这样,应用程序可以使用更少次数的查询、更新语句来完成查询。
使用情形:
1.实体间存在一对一关系的时候。
2.实体间存在一对多关系的时候。
嵌入型模型,通常具有更好的读操作性能,并且可以通过一条语句 来请求和获取相关联的数据。以原子性的写入方式来更新、写入相关联的数据。
存在问题:
一个document包含过多的域,导致document growth。对于MMAPv1存储引擎,这会影响写操作的性能、导致数据分段。
规范化(引用)数据模型
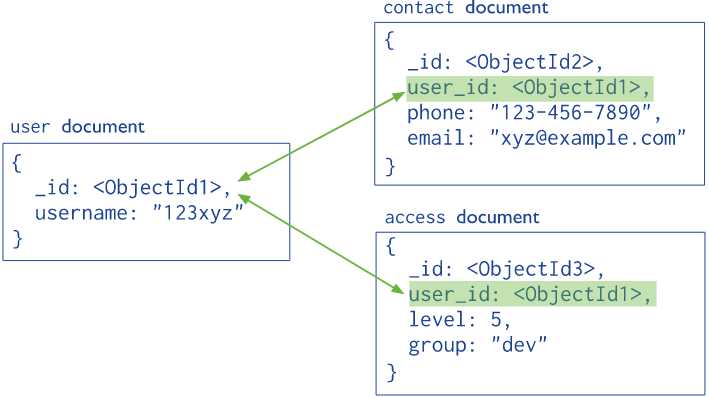
使用引用的方式表示document之间的关系。
使用情况:
--当嵌入式模型导致了大量数据重复,但是,数据重复使得读取性能无法表现出其应有的优势。
--表示复杂的多对多关系的时候。
--构造大的分层数据集。
引用模型拥有更多的灵活性。但是,客户端应用程序必须执行多项操作来实现相关联数据的同步更新。
2.Operational Factors and Data Models
四、MongoDB安全性
1.MongoDB认证管理
默认情况下,mongodb不使用访问控制功能。要使用访问控制需要自行开启、配置相关更能。
开启权限控制
方式一,启动时使用命令选项:
mongod --auth
方式二,在mongod配置文件中加入security.authorization设置:
security:
authorization: enabled
创建账户管理员
在admin数据库中,添加userAdmin/userAdminAnyDatabase角色类型的用户。
use admin db.createUser( { user: "myUserAdmin", pwd: "abc123", roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )
注:此账户只能对账户、角色进行管理,没有其他任何权限。
重启mongod即开启了权限认证功能,登录命令如下:
mongo --port 27017 -u "myUserAdmin" -p "abc123" --authenticationDatabase "admin"
认证
use admin
db.auth("myUserAdmin", "abc123" )
返回1:认证成功,否则认证失败
拥有用户管理员账户之后,即可添加其他我们需要的账户。例如:为test数据库添加一个具有读写权限的用户:
use test db.createUser( { user: "myTester", pwd: "xyz123", roles: [ { role: "readWrite", db: "test" }] } )
使用myTester账户登录:
mongo --port 27017 -u "myTester" -p "xyz123" --authenticationDatabase "test"
MongoDB提供了一系列的内置角色,我们可以使用它们来进行mongodb的管理。
我们也可以创建自定义的角色,定制我们需要的权限。
内置角色
2、加密设置
2.1传输加密
使用TLS/SSL (Transport Layer Security/Secure Sockets Layer) 对网络传输进行加密。
在使用SSL之前,须使用有一个包含一对公钥、私钥证书的.pem文件。
MongoDB可以使用任何权威证书和自签名证书发行的有效SSL证书。
为mongod和mongos配置TLS/SSL
2.2存储加密
2.3应用程序级别加密
标签:mina mount 公钥 author 重复 多对多 mongodb nts exe
原文地址:http://www.cnblogs.com/ahguSH/p/7397199.html