标签:实现 substring detail 页面 使用 hive 增加 lock 程序
介绍MySQL的调优手段,主要包括慢日志查询分析与Explain查询分析SQL执行计划
1、慢日志查询分析
首先需要对慢日志进行一些设置,如下:
SHOW VARIABLES LIKE ‘slow_query_log‘; -- 查看是否开启了慢查询 SET GLOBAL slow_query_log_file=‘/var/lib/mysql/mysql-slow.log‘; -- 设置慢查询日志的位置 SET GLOBAL log_queries_not_using_indexes=ON; -- 是否记录未使用索引的查询 SET GLOBAL long_query_time=1; -- 设置记录超过多长时间的SQL语句 SET GLOBAL slow_query_log=ON; -- 设置慢查询日志是否开启
然后我新建t_report_app、t_application与t_developer表,t_report_app中有2万多条数据,执行如下查询后,总共用时1.019sec,超过1秒后将记录到慢日志中。
SELECT * FROM t_report_app r ,t_application app,t_developer dev WHERE r.application_id = app.id AND app.developer_id = dev.id
查看mysql-slow.log输出日志信息,如果有许多历史信息,可以先使得如下命令清空:
echo "" > mysql-slow.log
重新运行后,进行查询,主要的信息如下:
# User@Host: root[root] @ [192.168.0.190] Id: 51 -- 执行的用户root和主机Host # Query_time: 22.834043 Lock_time: 0.000458 Rows_sent: 20724 Rows_examined: 277 SET timestamp=1469083853; SELECT * FROM t_report_app r ,t_application app,t_developer dev -- 执行的相关内容 WHERE r.application_id = app.id AND app.developer_id = dev.id;
我们也可以借助MySQL自带的慢查询分析工具mysqldumpslow,可以通过mysqldumpslow -h来查看具体的使用方法。
mysqldumpslow -t 3 mysql-slow.log | more
执行如上的语句将输出最耗时的3条SQL语句。输出格式如下:
Count: 1 (执行次数)Time=0.00s (0s) (执行时间)Lock=0.00s (0s)(锁定时间) Rows=2.0 (2), root[root]@[192.168.0.190](以root身份在ip客户端上执行如下内容) SELECT QUERY_ID, SUM(DURATION) AS SUM_DURATION, SEQ FROM INFORMATION_SCHEMA.PROFILING GROUP BY QUERY_ID LIMIT N, N (执行的SQL内容)
还可以通过pt-query-digest来进行分析,不过首先要安装这个工具,如下:
yum install perl-DBD-MySQL perl Makefile.PL make make test make install
安装完成后就可以使用如下命令进行查看分析SQL语句了。
cd /var/lib/mysql -- 切换到存有慢日志的文件夹中 echo "" >mysql-slow.log -- 清空之前的记录 pt-query-digest mysql-slow.log | more
输出如下:
# 250ms user time, 60ms system time, 25.30M rss, 219.89M vsz # Current date: Thu Jul 21 17:12:52 2016 # Hostname: localhost.localdomain # Files: mysql-slow.log # Overall: 2 total, 2 unique, 0 QPS, 0x concurrency ______________________ # Time range: all events occurred at 2016-07-21 17:12:47 # Attribute total min max avg 95% stddev median # ============ ======= ======= ======= ======= ======= ======= ======= # Exec time 1s 1ms 1s 611ms 1s 862ms 611ms # Lock time 12ms 357us 12ms 6ms 12ms 8ms 6ms # Rows sent 1016 16 1000 508 1000 695.79 508 # Rows examine 384 107 277 192 277 120.21 192 # Query size 317 142 175 158.50 175 23.33 158.50 # Profile # Rank Query ID Response time Calls R/Call V/M Item # ==== ================== ============= ===== ====== ===== =============== # 1 0x67E16746140E091A 1.2207 99.9% 1 1.2207 0.00 SELECT t_report_app # MISC 0xMISC 0.0012 0.1% 1 0.0012 0.0 <1 ITEMS> # Query 1: 0 QPS, 0x concurrency, ID 0x67E16746140E091A at byte 0 ________ # This item is included in the report because it matches --limit. # Scores: V/M = 0.00 # Time range: all events occurred at 2016-07-21 17:12:47 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 50 1 # Exec time 99 1s 1s 1s 1s 1s 0 1s # Lock time 97 12ms 12ms 12ms 12ms 12ms 0 12ms # Rows sent 98 1000 1000 1000 1000 1000 0 1000 # Rows examine 72 277 277 277 277 277 0 277 # Query size 44 142 142 142 142 142 0 142 # String: # Hosts 192.168.0.190 # Users root # Query_time distribution # 1us # 10us # 100us # 1ms # 10ms # 100ms # 1s ################################################################ # 10s+ # Tables # SHOW TABLE STATUS LIKE ‘t_report_app‘\G # SHOW CREATE TABLE `t_report_app`\G # EXPLAIN /*!50100 PARTITIONS*/ SELECT * FROM t_report_app r ,t_application app,t_developer dev WHERE r.application_id = app.id AND app.developer_id = dev.id LIMIT 0, 1000\G
为developer_id与application_id添加了Normal索引后,清空mysql-slow.log,重新运行SQL,结果如下:
# 210ms user time, 130ms system time, 25.30M rss, 219.89M vsz # Current date: Thu Jul 21 17:43:08 2016 # Hostname: localhost.localdomain # Files: mysql-slow.log # Overall: 2 total, 2 unique, 0 QPS, 0x concurrency ______________________ # Time range: all events occurred at 2016-07-21 17:43:01 # Attribute total min max avg 95% stddev median # ============ ======= ======= ======= ======= ======= ======= ======= # Exec time 36ms 1ms 35ms 18ms 35ms 24ms 18ms # Lock time 305us 125us 180us 152us 180us 38us 152us # Rows sent 1016 16 1000 508 1000 695.79 508 # Rows examine 1.17k 90 1.08k 599 1.08k 719.83 599 # Query size 318 142 176 159 176 24.04 159 # Profile # Rank Query ID Response time Calls R/Call V/M Item # ==== ================== ============= ===== ====== ===== =============== # 1 0x67E16746140E091A 0.0350 97.2% 1 0.0350 0.00 SELECT t_report_app # MISC 0xMISC 0.0010 2.8% 1 0.0010 0.0 <1 ITEMS> # Query 1: 0 QPS, 0x concurrency, ID 0x67E16746140E091A at byte 0 ________ # This item is included in the report because it matches --limit. # Scores: V/M = 0.00 # Time range: all events occurred at 2016-07-21 17:43:01 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 50 1 # Exec time 97 35ms 35ms 35ms 35ms 35ms 0 35ms # Lock time 59 180us 180us 180us 180us 180us 0 180us # Rows sent 98 1000 1000 1000 1000 1000 0 1000 # Rows examine 92 1.08k 1.08k 1.08k 1.08k 1.08k 0 1.08k # Query size 44 142 142 142 142 142 0 142 # String: # Hosts 192.168.0.190 # Users root # Query_time distribution # 1us # 10us # 100us # 1ms # 10ms ################################################################ # 100ms # 1s # 10s+ # Tables # SHOW TABLE STATUS LIKE ‘t_report_app‘\G # SHOW CREATE TABLE `t_report_app`\G # EXPLAIN /*!50100 PARTITIONS*/ SELECT * FROM t_report_app r ,t_application app,t_developer dev WHERE r.application_id = app.id AND app.developer_id = dev.id LIMIT 0, 1000\G
使用Explain查询分析SQL的执行计划,如下:
EXPLAIN SELECT * FROM t_report_app r ,t_application app,t_developer dev WHERE r.application_id = app.id AND app.developer_id = dev.id
输出如下结果:

为developer_id与application_id添加了Normal索引,执行结果如下:

解释如下:
| 列名称 | 描述 |
| table | 显示查询是关于哪个表的 |
| type | 很重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL |
| possible_keys | 显示可能应用在这张表中的索引。如果为空,没有可能应用的索引 |
| key | 实际使用的索引。如果为NULL,则没有使用索引 |
| key_len | 使用的索引的长度。在不损失精确性的情况下,长度越短越好 |
| ref | 显示索引的哪一列被使用了 |
| rows | MYSQL认为必须检查的用来返回请求的行数 |
|
extra
|
当这一列的值是Using filesort(需要进行额外的排序)或Using temporary(需要临时表进行处理)时,说明查询需要优化了
|
Using filesort:MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
Using temporary:MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
关于type字段的含义:
新建一个表,表名为tb_c,其中id是聚集索引,b和c建立了联合索引。
(1)ALL:全表扫描
explain select * from tb_c where c=2

用不到索引时只能是全表扫描
(2)const:读常量,且最多只会有一条记录匹配,由于是常量,所以实际上只需要读一次;
select b,c from tb_c where b=2

还有一个const的特例,表有且仅有一行满足条件,如下:
select * from (select b,c from tb_c where b=2) a

(3)eq_ref:最多只会有一条匹配结果,一般是通过主键或者唯一键索引来访问;
(4)index:全索引扫描;
该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。当查询只使用作为单索引一部分的列时,MySQL可以使用该联接类型
select c from tb_c where b>2

(5)rang:索引范围扫描。这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西时发生的情况
select * from tb_c where b>2

(6)ref:Join 语句中被驱动表索引引用查询;这个连接类型只有在查询使用了不是唯一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少—越少越好
各个属性可以参考:
(1)http://blog.csdn.net/xifeijian/article/details/19773795
(2)http://www.cnitblog.com/aliyiyi08/archive/2016/04/21/48878.html
2、MySQL常用SQL优化
1、 只返回需要的数据
返回数据到客户端至少需要数据库提取数据、网络传输数据、客户端接收数据以及客户端处理数据等环节。如果返回不需要的数据,就会增加服务器、网络和客户端的无效劳动,其害处是显而易见的,避免这类事件需要注意:
A、 横向来看,不要写SELECT * 的语句,而是选择你需要的字段
B、 纵向来看,合理写WHERE子句,不要写没有WHERE的SQL语句
C、对于聚合查询,可以用HAVING子句进一步限定返回的行
2、 尽量少做重复的工作
这一点的侧重点在客户端程序,需要注意的如下:
A、控制同一语句的多次执行,特别是一些基础数据的多次执行是很多程序员很少注意的
B、减少多次的数据转换,也许需要数据转换是设计的问题,但是减少次数是程序员可以做到的
C、杜绝不必要的子查询和连接表,子查询在执行计划一般解释成外连接,多余的连接表带来额外的开销??
D、UPDATE操作不要拆成(DELETE+INSERT)操作的形式,虽然功能相同,但是性能差别是很大的。
3、 子查询的用法
子查询可以使我们的编程灵活多样,可以用来实现一些特殊的功能。但是在性能上,往往一个不合适的子查询用法会形成一个性能瓶颈。
如果子查询的条件中使用了其外层的表的字段,这种子查询就叫作相关子查询。相关子查询可以用IN、NOT IN、EXISTS、NOT EXISTS引入。
A、NOT IN、NOT EXISTS的相关子查询可以改用LEFT JOIN代替写法
SELECT pub_name FROM publishers WHERE pub_id NOT IN (SELECT pub_id FROM titles WHERE TYPE =‘bubiness‘) SELECT a.pub_name FROM publishers a LEFT JOIN titles b ON b.type = ‘business‘ AND a.pub_id = b.pub_id WHERE b.pub_id IS NULL
SELECT titile FROM titles WHERE NOT EXISTS (SELECT title_id FROM sales WHERE title_id = titles.title_id) SELECT title FROM titles LEFT JOIN sales ON sales.title_id = titles.title_id WHERE sales.title_id IS NULL
B、如果保证子查询没有重复 ,IN、EXISTS的相关子查询可以用INNER JOIN 代替。如果有重复,则内连接会去重,所以就不等价了
SELECT pub_name FROM publishers WHERE pub_id IN (SELECT pub_id FROM titles WHERE TYPE =‘bubiness‘) SELECT DISTINCT a.pub_name FROM publishers a INNER JOIN titles b ON b.type = ‘business‘ AND a.pub_id = b.pub_id
C、IN的相关子查询用EXISTS代替
SELECT pub_name FROM publishers WHERE pub_id IN (SELECT pub_id FROM titles WHERE TYPE = ‘business‘) SELECT pub_name FROM publishers WHERE EXISTS (SELECT 1 FROM titles WHERE TYPE = ‘business‘ AND pub_id = publishers.pub_id)
如上的语句完全正确,注意红色为1,而不是L(l)
D、不要用COUNT(*)的子查询判断是否存在记录,最好用LEFT JOIN或者EXISTS
SELECT id FROM jobs WHERE (SELECT COUNT(*) FROM employee WHERE employee.id = jobs.id)<>0 SELECT id FROM jobs WHERE EXISTS(SELECT 1 FROM employee WHERE employee .id = jobs.id)
4、尽量使用索引
索引固然可以提高相应的 select 的效率,但同时也降低了insert及update的效率,因为insert或update时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
为了使得优化器能高效使用索引,写语句的时候应该注意:
A、尽量使用字段索引的本体
SELECT ID FROM T WHERE NUM/2=NUM1 -- NUM有索引 SELECT ID FROM T WHERE NUM=NUM1*2 -- NUM1有索引
B、不要对索引字段进行格式转换
应尽量避免在where子句中对字段进行表达式操作,应尽量避免在where子句中对字段进行函数操作
SELECT * WHERE date(date_col) between '2009-2-1'and '2009-3-1' # MySQL中也是可以这样写的
则索引失效,因为查询条件并不是字段A的本体,而是使用了date函数。解决方法是把查询条件改为:
select * where date_col between '2009-2-1 00:00:00'and '2009-3-1 23:59:59'
多个字段添加复合索引时,其中单个字段如果作为索引来使用则失去索引功能??有待讨论
C、不要对索引字段使用函数
WHERE LEFT(NAME, 3)=’ABC’ 或者 WHERE SUBSTRING(NAME,1, 3)=’ABC’ WHERE NAME LIKE ‘ABC%’
MySQL的日期转换为字符串:
SELECT * FROM time_test WHERE DATE_FORMAT( date_col,‘%Y-%m-%d‘)>‘2010-08-01‘ AND DATE_FORMAT( date_col, ‘%Y-%m-%d‘)<‘2020-08-03‘
5、 注意连接条件的写法
多表连接的连接条件对索引的选择有着重要的意义,所以我们在写连接条件的时候需要特别的注意。
A、 多表连接的时候,连接条件必须写全,宁可重复,不要缺漏。
B、 连接条件尽量使用聚集索引
C、 注意ON部分条件和WHERE部分条件的区别 ???两个SQL语句执行时有什么不同呢?
6、 其他需要注意的地方
经验表明,问题发现的越早解决的成本越低,很多性能问题可以在编码阶段就发现,为了提早发现性能问题,需要注意:
A、 程序员注意、关心各表的数据量。
B、 编码过程和单元测试过程尽量用数据量较大的数据库测试,最好能用实际数据测试。
C、 每个SQL语句尽量简单
D、 不要频繁更新有触发器的表的数据
E、 注意数据库函数的限制以及其性能
7、 对于Where子句及含有如下一些关键字时,要具体的使用执行计划查看:
在出现where 子句时,尤其是where子句中含有is null、!=、<>、or、in、not in时,应尽量避免在 where 子句中使用!= 或 <>操作符,
MySQL只有对以下操作符才使用索引:<、<=、=、>、>=、between、in,以及某些时候的like。
A、“应尽量避免在WHERE子句中对字段进行 NULL 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
SELECT ID FROM T WHERE NUM IS NULL SELECT ID FROM T WHERE NUM=0”
可以在NUM上设置默认值0,确保表中NUM列没有NULL值,然后这样查询:
个人意见:经过测试,IS NULL也是可以用INDEX SEEK查找的,0和NULL是不同概念的,以上说法的两个查询的意义和记录数是不同的。
2、 “应尽量避免在 WHERE 子句中使用!=或<>(表示不等于)操作符,否则将引擎放弃使用索引而进行全表扫描。”
个人意见:经过测试,<>也是可以用INDEX SEEK查找的。
(1)高效的统计行数:
select count(*) from news; // 一般这个性能会更好一些 select count(id) from news; // 这个会执行全表扫描,看一下id为空的情况是不计入内的
count(*)要比count(id)要快,因为如果count()括号中写列名,count就会统计该列有值的次数。
使用count的查询很难优化,因为很多情况都需要执行全表扫描,唯一的优化方式就是尽量为where子句的表建立索引,更多的时候我们应该调整应用程序,避免使用count,比如,大数据分页采用估算分页法等等。
(2)查询记录
首先需要新建一张辅助分页的表pagination,有id与page字段,类型都为整数。同步id值与t_report_app表中的id,如下:
INSERT INTO pagination(id) SELECT id FROM t_report_app
然后使用如下语句插入page值。
SET @p:= 0; UPDATE pagination SET page=CEIL((@p:= @p + 1) / 10) ORDER BY id DESC;
我们按每页10条记录,id降序进行分页。如果插入或删除记录则需要同步pagination表记录。
这样如果我们查询第10页的记录就可以直接知道t_report_app记录中10条数据的id了,如下:
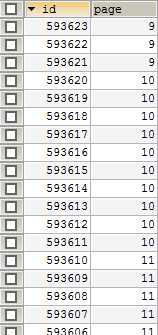
也可以用另外的办法,如下:
SELECT id FROM ( SELECT id, ((@cnt:= @cnt + 1) + $perpage - 1) % $perpage temp -- 对查询出来的记录进行编号,以方便筛选每页中第一条记录的id FROM t_report_app JOIN (SELECT @cnt:= 0)T -- 重置@cnt参数为0 -- WHERE id < $last_id ORDER BY id DESC LIMIT $perpage * $buttons -- 页面上有10个分页按钮,每页10条记录,则需要筛选出80条记录 )C WHERE temp = 0; -- 筛选每页中第一条记录的id,总计10个
为每一个分页的按钮计算出一个offset对应的id。可以将上面的结果存入表中,方面分页时查询。
INSERT INTO pagination2(id,page) ( SELECT id, @cntb:= @cntb + 1 AS page FROM ( SELECT id, ((@cnt:= @cnt + 1) + 10 - 1) % 10 cnt FROM t_report_app JOIN (SELECT @cnt:= 0)T ORDER BY id DESC )C JOIN (SELECT @cntb:= 0)D WHERE cnt = 0 ORDER BY id DESC )
查看pagination2中的数据,如下:
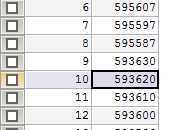
第10页的Max(id)为593620,与之前的表中是一致的。
标签:实现 substring detail 页面 使用 hive 增加 lock 程序
原文地址:http://www.cnblogs.com/mazhimazhi/p/7499371.html