标签:dal 扫描 sdi 获取 == 本地存储 正则表达 make 匹配
import urllib.request,os
import re
# 获取html 中的内容
def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html
path=‘本地存储位置‘
# 保存路径
def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,‘%s.jpg‘%x)
return t
html=getHtml(‘https://。。。‘)
# 获取网页的图片
def getImg(html):
# 正则表达式
reg=r‘src="(https://imgsa[^>]+\.(?:jpeg|jpg))"‘
# 编译正则表达式
imgre=re.compile(reg)
imglist=re.findall(imgre,html.decode(‘utf-8‘))
x=0
for imgurl in imglist:
# 下载图片
urllib.request.urlretrieve(imgurl,saveFile(x))
print(imgurl)
x+=1
if x==23:
break
print(x)
return imglist
getImg(html)
print(‘end‘)
^ : 字符串的开始,
$: 字符串的末尾
. : 匹配任意字符,除换行符
* : 任意多的字符
+: 任意大于1 的字符
?: 匹配0或1个, home-?brew : homebrew, 或home-brew
[]: 指定一个字符类别,可以单独列出,也可以使用- 表示一个区间。[abc]匹配a,b,c 中的任意一个字符,也可以表示[a-c]的字符集
[^]: ^ 作为类别的首个字符,[^5]将匹配除5之外的任意字符
\ : 转义字符
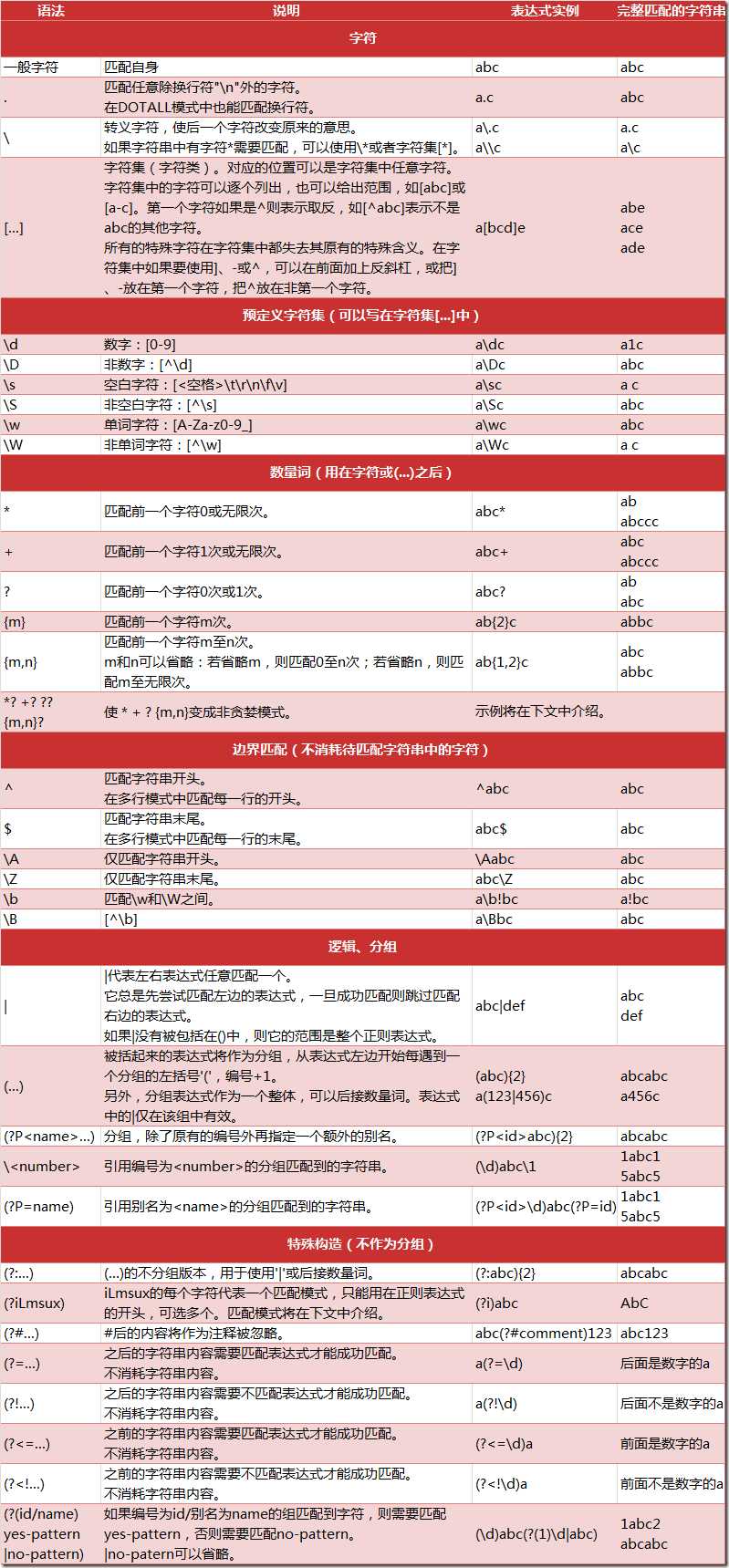
加反斜杠取消特殊性。\ section, 为了匹配反斜杠,就得写为\\, 但是\\ 又有别的意思。。大量反斜杠。。。 使用raw字符串表示,在字符串前加r,反斜杠就不会当做特殊处理,\n 表示两个字符\ 和n,而不是换行。
如: https://imgsa[^>]+\.(?:jpeg|jpg) 表示 https://imgsa(不匹配>的多余1个的字符串).
| 方法/属性 | 作用 |
| match() | 决定 RE 是否在字符串刚开始的位置匹配 |
| search() | 扫描字符串,找到这个 RE 匹配的位置 |
| findall() | 找到 RE 匹配的所有子串,并把它们作为一个列表返回 |
| finditer() | 找到 RE 匹配的所有子串,并把它们作为一个迭代器返回 |
| 方法/属性 | 作用 |
| group() | 返回被 RE 匹配的字符串 |
| start() | 返回匹配开始的位置 |
| end() | 返回匹配结束的位置 |
| span() | 返回一个元组包含匹配 (开始,结束) 的位置 |
标签:dal 扫描 sdi 获取 == 本地存储 正则表达 make 匹配
原文地址:http://www.cnblogs.com/fanhaha/p/7620374.html