标签:中间 logs 参数 方法 示例 插入排序 bre ++ alt


C 快速排序
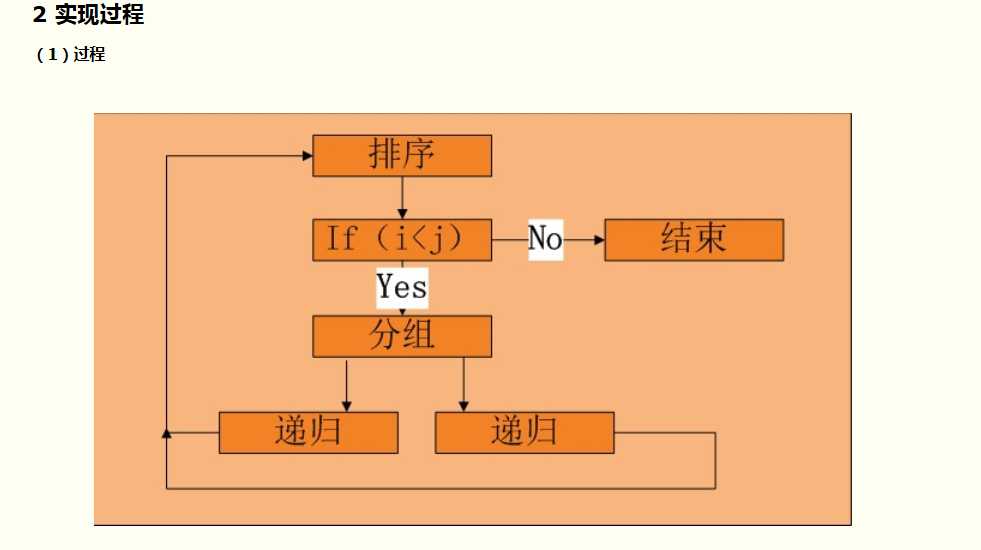
1). 描述
1.从数列中挑出一个元素,称为 "基准"(pivot)
2.重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
3.递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
2).示例代码
示例代码为C语言,输入参数中,需要排序的数组为arr[],取出一个元素为pivot,并根据 pivot值,将数组按照大于pivot和小于pivot分为两个区域,递归完成排序。
3).复制代码
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 void quick_sort(char *arr, int begin, int end)
5 {
6 char pivot = arr[begin];
7 int i,j;
8 i = begin;
9 j = end;
10 while(i < j) {
11 while(arr[j] >= pivot && i < j)
12 j --;
13 arr[i] = arr[j];
14 while(arr[i] <= pivot && i < j)
15 i ++;
16 arr[j] = arr[i];
17 }
18 arr[i] = pivot;
19
20 if( i-1 > begin)
21 quick_sort(arr, begin, i - 1);
22 if( end > i + 1)
23 quick_sort(arr, i + 1, end);
24 }
25
26 int main()
27 {
28 char ch[] = "qwertyuiopasdfghjklzxcvbnm";
29 quick_sort(ch, 0 ,25);
30 printf("%s\n", ch);
31 exit(0);
32 }
输出结果
abcdefghijklmnopqrstuvwxyz
一.算法分析
最差时间复杂度 Θ(n2) 最优时间复杂度 Θ(nlog n) 平均时间复杂度 Θ(nlog n)
二.原理
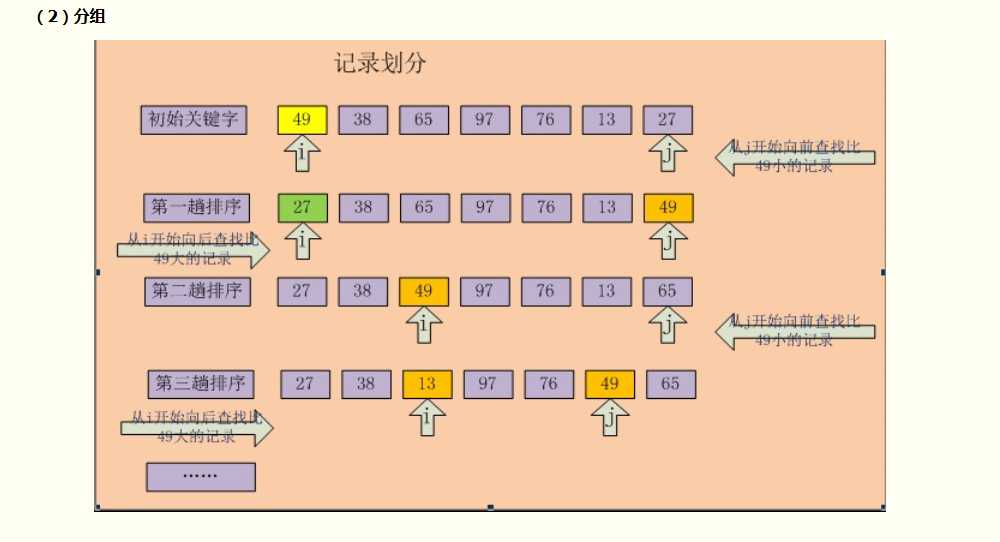
已知一组无序数据a[1]、a[2]、……a[n],需将其按升序排列。
首先任取数据a[x]作为基准。
比较a[x]与其它数据并排序,使a[x]排在数据的第k位,并且使a[1]~a[k-1]中的每一个数据<a[x],a[k+1]~a[n]中的每一个数据>a[x],
然后采用分治的策略分别对a[1]~a[k-1]和a[k+1]~a[n]两组数据进行快速排序。
三.优劣
优点:极快,数据移动少;
缺点:不稳定。
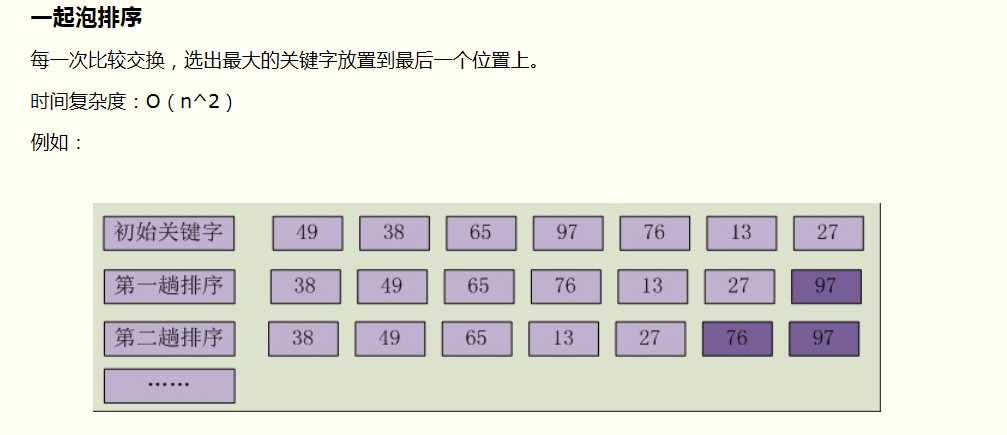
二.冒泡排序
1)算法描述
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序对n个项目需要O(n2)的比较次数,且可以原地排序(in-place)。
尽管这个算法是最简单了解和实作的排序算法之一,但它对于少数元素之外的数列排序是很没有效率的。
冒泡排序是与插入排序拥有相等的执行时间,但是两种法在需要的交换次数却很大地不同。在最坏的情况,冒泡排序需要O(n2)次交换,而插入排序只要最多O(n)交换。
天真的冒泡排序实作(类似下面)通常会对已经排序好的数列拙劣地执行(O(n2)),而插入排序在这个例子只需要O(n)个运算。因此很多现代的算法教科书避免使用冒泡排序,而用插入排序取代之。冒泡排序如果能在内部循环第一次执行时,使用一个旗标来表示有无需要交换的可能,也有可能把最好的复杂度降低到O(n)。在这个情况,在已经排序号的数列就无交换的需要。若在每次走访数列时,把走访顺序和比较大小反过来,也可以些微地改进效率。
2) 冒泡排序算法的运作如下:
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
1.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
2.针对所有的元素重复以上的步骤,除了最后一个。
3.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
3)示例代码
1 #include <stdlib.h>
2 #include <stdio.h>
3
4 void bubble_sort(int a[], const int size)
5 {
6 int flag = 0;
7 int temp = 0;
8 int i;
9 for(i = 0; i < size - 1; i ++) {
10 flag = 1;
11 int j;
12 for(j = 0; j < size - i -1; j ++) {
13 if(a[j] > a[j + 1]) {
14 temp = a[j];
15 a[j] = a[j + 1];
16 a[j + 1] = temp;
17 flag = 0;
18 }
19 }
20 if(flag)
21 break;
22 }
23 }
24
25 int main()
26 {
27 int number[] = {5,3,8,4,1,7,9,2,0,6};
28 bubble_sort(number, sizeof(int_array) / sizeof(int));
29 int i;
30 for(i = 0; i < sizeof(int_array) / sizeof(int); i ++)
31 printf("%d\n", number[i]);
32 }
复制代码
输出结果
0
1
2
3
4
5
6
7
8
9
一.原理
已知一组无序数据a[1]、a[2]、……a[n],需将其按升序排列。
首先比较a[1]与a[2]的值,若a[1]大于a[2]则交换两者的值,否则不变。
再比较a[2]与a[3]的值,若a[2]大于a[3]则交换两者的值,否则不变。
再比较a[3]与a[4],以此类推,最后比较a[n-1]与a[n]的值。
这样处理一轮后,a[n]的值一定是这组数据中最大的。
再对a[1]~a[n-1]以相同方法处理一轮,则a[n-1]的值一定是a[1]~a[n-1]中最大的。再对a[1]~a[n-2]以相同方法处理一轮,以此类推。共处理n-1轮后a[1]、a[2]、……a[n]就以升序排列了。
二.优劣
优点:稳定;
缺点:慢,每次只能移动相邻两个数据。
标签:中间 logs 参数 方法 示例 插入排序 bre ++ alt
原文地址:http://www.cnblogs.com/wangprince2017/p/7658749.html