标签:release blog rom name lis blank images param 加载
最近在学习处理自然语言处理,就发现LTP的(哈工大语言云),这个比我最先使用的jieba分词更好,词库更大,功能也更强大。
这里介绍两种方法:1、调用LTP的API,2、使用pyltp,这里的方法基于python,对于其它语言的使用的请大家了解这里:LTP 3.3文档
1、调用LTP的API
①进入哈工大语言云进行注册
②注册之后哈工大语言云的官网会给你一个API key,但是好像一开始并不能使用,要等官网审核之后,显示你的本月使用流量有18G左右就可以了,
新用户一般会给你送20G(我好像一开始就是18G)
③代码实现自然语言处理:
# -*- coding: utf-8 -*- import urllib2 url_get_base = "http://api.ltp-cloud.com/analysis/?" api_key = ‘*********‘ # 输入注册API_KEY # 待分析的文本 text = "国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。" format0 = ‘plain‘ # 结果格式,有xml、json、conll、plain(不可改成大写) pattern = ‘ws‘ # 指定分析模式,有ws、pos、ner、dp、sdp、srl和all #分词 result = urllib2.urlopen("%sapi_key=%s&text=%s&format=%s&pattern=%s" % (url_get_base, api_key, text, format0, ‘ws‘)) content = result.read().strip() print content print ‘*‘*60 #词性标注 result1 = urllib2.urlopen("%sapi_key=%s&text=%s&format=%s&pattern=%s" % (url_get_base, api_key, text, format0, ‘pos‘)) content1 = result1.read().strip() print content1 print ‘*‘*60 #命名实体识别 result2 = urllib2.urlopen("%sapi_key=%s&text=%s&format=%s&pattern=%s" % (url_get_base, api_key, text, format0, ‘ner‘)) content2 = result2.read().strip() print content2 print ‘*‘*60 #依存句法分析 result3 = urllib2.urlopen("%sapi_key=%s&text=%s&format=%s&pattern=%s" % (url_get_base, api_key, text, format0, ‘dp‘)) content3 = result3.read().strip() print content3 print ‘*‘*60 #语义依存分析 result4 = urllib2.urlopen("%sapi_key=%s&text=%s&format=%s&pattern=%s" % (url_get_base, api_key, text, format0, ‘sdp‘)) content4 = result4.read().strip() print content4 print ‘*‘*60 #语义角色标注 result1 = urllib2.urlopen("%sapi_key=%s&text=%s&format=%s&pattern=%s" % (url_get_base, api_key, text, format0, ‘srl‘)) content1 = result1.read().strip() print content1 print ‘*‘*60
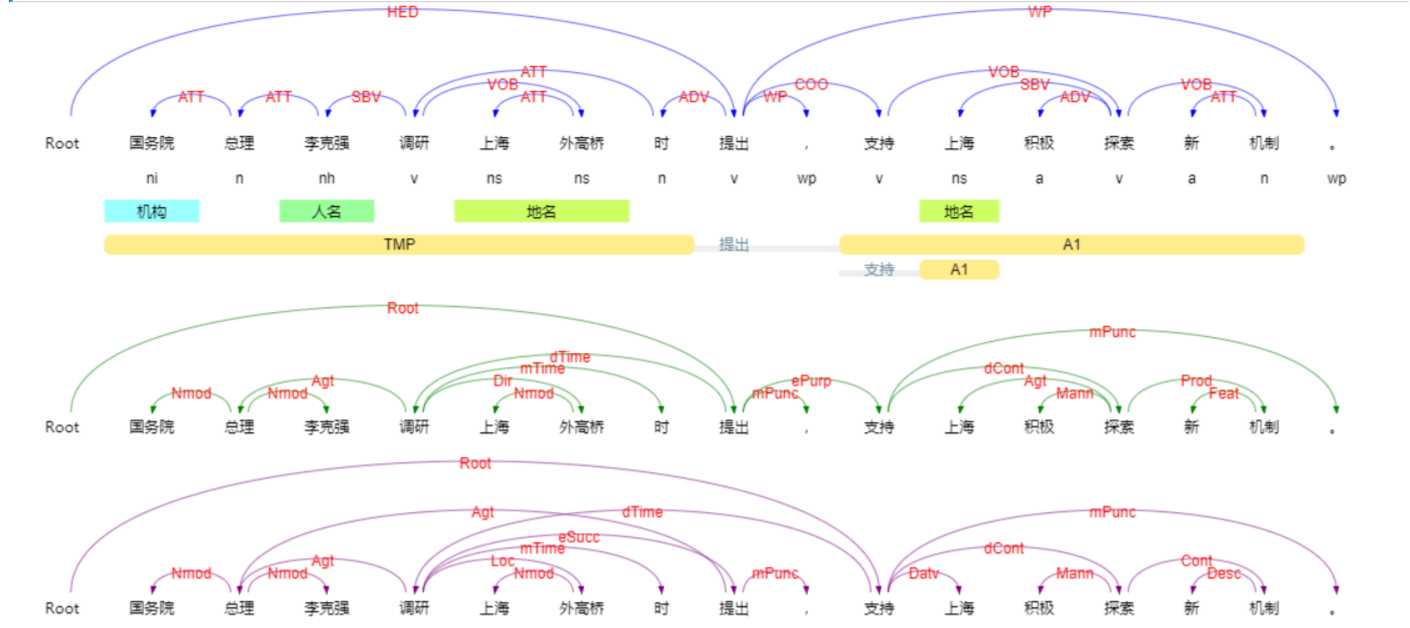
显示结果:
国务院 总理 李克强 调研 上海 外高桥 时 提出 , 支持 上海 积极 探索 新 机制 。
************************************************************
国务院_ni 总理_n 李克强_nh 调研_v 上海_ns 外高桥_ns 时_n 提出_v ,_wp 支持_v 上海_ns 积极_a 探索_v 新_a 机制_n 。_wp
************************************************************
[国务院]Ni 总理 [李克强]Nh 调研 [上海 外高桥]Ns 时 提出 , 支持 [上海]Ns 积极 探索 新 机制 。
************************************************************
国务院_0 总理_1 ATT
总理_1 李克强_2 ATT
李克强_2 调研_3 SBV
调研_3 时_6 ATT
上海_4 外高桥_5 ATT
外高桥_5 调研_3 VOB
时_6 提出_7 ADV
提出_7 -1 HED
,_8 提出_7 WP
支持_9 提出_7 COO
上海_10 探索_12 SBV
积极_11 探索_12 ADV
探索_12 支持_9 VOB
新_13 机制_14 ATT
机制_14 探索_12 VOB
。_15 提出_7 WP
************************************************************
国务院_0 总理_1 Nmod
总理_1 调研_3 Agt
李克强_2 总理_1 Nmod
调研_3 提出_7 dTime
上海_4 外高桥_5 Nmod
外高桥_5 调研_3 Dir
时_6 调研_3 mTime
提出_7 -1 Root
,_8 提出_7 mPunc
支持_9 提出_7 ePurp
上海_10 探索_12 Agt
积极_11 探索_12 Mann
探索_12 支持_9 dCont
新_13 机制_14 Feat
机制_14 探索_12 Prod
。_15 支持_9 mPunc
************************************************************
[国务院 总理 李克强 调研 上海 外高桥 时]TMP [提出]v , [支持 上海 积极 探索 新 机制]A1 。
国务院 总理 李克强 调研 上海 外高桥 时 提出 , [支持]v [上海]A1 积极 探索 新 机制 。
************************************************************
如果大家想看到更加直观的的结果可以进入哈工大语言云的在线测试,就可以看到更加直观的结果,如下:
2、使用pyltp
这里参考:Python下的自然语言处理利器-LTP语言技术平台 pyltp 学习手札
按照上面的博客安装是没有问题的,我的系统是win8.1、python2.7,需要注意的是,pip pyltp install要基于C++的编译器,所以我安装的是Micorsoft Visual C++ Compiler for Python 2.7,
因为本人电脑上已经安装了VS2012。
安装完成以后,就可以进行测试了:
注意下面的ltp路径要换上你自己的路径
①使用 pyltp 进行分句示例如下
# -*- coding: utf-8 -*- from pyltp import SentenceSplitter sents = SentenceSplitter.split(‘元芳你怎么看?我就趴窗口上看呗!‘) # 分句 print ‘\n‘.join(sents)
结果如下:
元芳你怎么看?
我就趴窗口上看呗!
②使用 pyltp 进行分词示例如下
# -*- coding: utf-8 -*- import os LTP_DATA_DIR = ‘/path/to/your/ltp_data‘ # ltp模型目录的路径 cws_model_path = os.path.join(LTP_DATA_DIR, ‘cws.model‘) # 分词模型路径,模型名称为`cws.model` from pyltp import Segmentor segmentor = Segmentor() # 初始化实例 segmentor.load(cws_model_path) # 加载模型 words = segmentor.segment(‘元芳你怎么看‘) # 分词 print ‘\t‘.join(words) segmentor.release() # 释放模型
结果如下:
元芳 你 怎么 看
③使用 pyltp 进行命名实体识别示例如下
# -*- coding: utf-8 -*- from pyltp import NamedEntityRecognizer recognizer = NamedEntityRecognizer() # 初始化实例 recognizer.load(‘/path/to/your/model‘) # 加载模型 netags = recognizer.recognize(words, postags) # 命名实体识别 print ‘\t‘.join(netags) recognizer.release() # 释放模型
④使用 pyltp 进行依存句法分析示例如下
# -*- coding: utf-8 -*- from pyltp import SementicRoleLabeller labeller = SementicRoleLabeller() # 初始化实例 labeller.load(‘/path/to/your/model/dir‘) # 加载模型 roles = labeller.label(words, postags, netags, arcs) # 语义角色标注 for role in roles: print role.index, "".join( ["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]) labeller.release() # 释放模型
⑤pyltp 暂不提供语义依存分析功能。若需使用该功能,请使用 语言云 。
# -*- coding: utf-8 -*- import sys, os ROOTDIR = os.path.join(os.path.dirname(__file__), os.pardir) sys.path = [os.path.join(ROOTDIR, "lib")] + sys.path # Set your own model path MODELDIR=os.path.join(ROOTDIR, "ltp_data") from pyltp import SentenceSplitter, Segmentor, Postagger, Parser, NamedEntityRecognizer, SementicRoleLabeller paragraph = ‘国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。‘ sentence = SentenceSplitter.split(paragraph)[0] segmentor = Segmentor() segmentor.load(os.path.join(MODELDIR, "你的路径\\cws.model")) words = segmentor.segment(sentence) print "\t".join(words) postagger = Postagger() postagger.load(os.path.join(MODELDIR, "你的路径\\pos.model")) postags = postagger.postag(words) # list-of-string parameter is support in 0.1.5 # postags = postagger.postag(["中国","进出口","银行","与","中国银行","加强","合作"]) print "\t".join(postags) parser = Parser() parser.load(os.path.join(MODELDIR, "你的路径\\parser.model")) arcs = parser.parse(words, postags) print "\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs) recognizer = NamedEntityRecognizer() recognizer.load(os.path.join(MODELDIR, "你的路径\\ner.model")) netags = recognizer.recognize(words, postags) print "\t".join(netags) labeller = SementicRoleLabeller() labeller.load(os.path.join(MODELDIR, "你的路径\\srl/")) roles = labeller.label(words, postags, netags, arcs) for role in roles: print role.index, "".join( ["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]) segmentor.release() postagger.release() parser.release() recognizer.release() labeller.release()
结果:
国务院 总理 李克强 调研 上海 外高桥 时 提出 , 支持 上海 积极 探索 新 机制 。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ni n nh v ns ns n v wp v ns a v a n wp
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2:ATT 3:ATT 4:SBV 7:ATT 6:ATT 4:VOB 8:ADV 0:HED 8:WP 8:COO 13:SBV 13:ADV 10:VOB 15:ATT 13:VOB 8:WP
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
S-Ni O S-Nh O B-Ns E-Ns O O O O S-Ns O O O O O
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
3 A0:(0,2)A1:(4,5)
7 TMP:(0,6)
9 A1:(10,14)
12 A0:(10,10)ADV:(11,11)A1:(13,14)
python处理自然语言:1、调用LTP的API,2、使用pyltp
标签:release blog rom name lis blank images param 加载
原文地址:http://www.cnblogs.com/ybf-yyj/p/7658571.html