标签:user 翻译 目标地址 有道翻译 安全 webkit cli 方式 服务器
urllib2默认只支持HTTP/HTTPS的GET和POST方法
一、Get方式
GET请求一般用于我们向服务器获取数据,比如说,我们用百度搜索,在百度搜索框中搜索“秦时明月”,拿到地址栏里有效url为:https://www.baidu.com/s?wd=秦时明月
通过抓包得到其get的目标url为:https://www.baidu.com/s?wd=%E7%A7%A6%E6%97%B6%E6%98%8E%E6%9C%88
这两个url其实是一样的,wd后面出现的字符串是“秦时明月”的url编码,于是我们可以尝试用默认的Get方式来发送请求。
#负责url编码处理 import urllib import urllib2 url = "http://www.baidu.com/s" word = {"wd":"秦时明月"} #转换成url编码格式(字符串) word = urllib.urlencode(word) # url首个分隔符就是 ? newurl = url + "?" + word headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
代码执行结果就相当于在百度搜索框输入“秦时明月”后回车,对于get请求,使用urllib的urlencode将查询字符进行url编码再拼接为完整url然后发送请求即可。
二、post请求
Request请求对象的里有data参数,它就是用在POST里的,我们要传送的数据就是这个参数data,data是一个字典,里面要匹配键值对。
打开有道翻译http://fanyi.youdao.com/,输入测试数据(python),我们发现地址栏的url没有变化,使用抓包工具可以拿到其POST请求的目标地址:
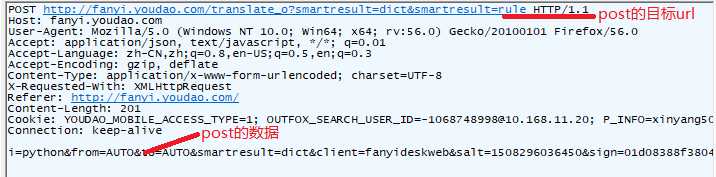
由此我们可以试着模拟这个POST请求:
import urllib import urllib2 # POST请求的目标URL url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0"} formdata = { "i":" python",
"from":"AUTO",
"to":"AUTO", "smartresult":" dict",
"client":" fanyideskweb",
"salt":" 15082966550971",
"sign":" 2a6d78290492d163dbd6803b29e2489c",
"doctype":"json", "version":"2.1", "keyfrom":"fanyi.web", "action":"FY_BY_ENTER", "typoResult":"true" } data = urllib.urlencode(formdata) request = urllib2.Request(url, data = data, headers = headers) response = urllib2.urlopen(request) print response.read()
这就是一个简单的post请求的方式,可以根据此思路写一个有道翻译的接口程序。
三、获取AJAX加载的内容
有些网页内容使用AJAX加载,直接发送请求拿不到数据,而AJAX一般返回的是JSON,可以直接对AJAX地址进行post或get,就返回JSON数据了。
以豆瓣电影排行榜为例,https://movie.douban.com/typerank?type_name=剧情&type=11&interval_id=100:90&action=,通过抓包获取传送json文件的url:

这样就拿到了url,其中start和limit两个参数是数据的加载发送,我们可以单独拿出来作为参数传进去:
import urllib import urllib2 url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action" headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0"}
# 变动的是这两个参数,从start开始往后显示limit个数据
formdata = {
‘start‘:‘0‘,
‘limit‘:‘10‘
}
data = urllib.urlencode(formdata)
request = urllib2.Request(url, data = data, headers = headers)
response = urllib2.urlopen(request)
print response.read()
对于这种动态页面,我们要关注数据的来源;也可以使用selenium和phantomJS模拟浏览器进行获取数据。
四、处理HTTPS请求的SSL认证
urllib2可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,如果网站的SSL证书是经过CA认证的,则能够正常访问,如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,比如浏览器在访问12306网站如:https://www.12306.cn/mormhweb/的时候,会警告用户证书不受信任。
import urllib2 url = "https://www.12306.cn/mormhweb/" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} request = urllib2.Request(url, headers = headers) response = urllib2.urlopen(request) print response.read()
运行程序会出现如下错误提示:
urllib2.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:661)>
所以,如果以后遇到这种网站,我们需要单独处理SSL证书,让程序忽略SSL证书验证错误,即可正常访问。
import urllib import urllib2 # 导入Python SSL处理模块 import ssl # 忽略未经核实的SSL证书认证 context = ssl._create_unverified_context() url = "https://www.12306.cn/mormhweb/" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} request = urllib2.Request(url, headers = headers) # 在urlopen()方法里 指明添加 context 参数 response = urllib2.urlopen(request, context = context) print response.read()
Python爬虫基础(二)urllib2库的get与post方法
标签:user 翻译 目标地址 有道翻译 安全 webkit cli 方式 服务器
原文地址:http://www.cnblogs.com/xinyangsdut/p/7686000.html