标签:style blog http color io os 使用 ar strong
说明:
无意看到一篇小短文,猜测作者应该是一个图形学领域的程序员或专家,介绍了在光线(射线)追踪程序中是如何优化C/C++代码的。倒也有一些参考意义,当然有的地方我并不赞同或者说我也不完全理解,原文在此,我的粗糙翻译如下:
1. 牢记Ahmdal定律
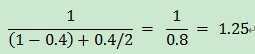
- funccost表示是函数func的运行时间百分比,funcspeedup是你优化后函数的运行系数;
- 所以,如果函数TriangleIntersect()占用40%的运行时间,而在你优化后使它运行快了两倍,那么你的程序运行能够快了25%;
- 这意味着不经常使用的代码不需要做过多优化(或者完全不优化),比如场景加载过程;
- 也就是:让频繁调用的代码运行得更加高效,而让较少调用的代码保持运行正确;
2. 先有正确的代码,然后再做优化
- 这并不是说先花8个周时间写一个全功能的光线追踪器,然后再花8个周去优化;
- 而是在你的管线追踪程序中的多个阶段都进行优化;
- 如果代码是正确的,而你又知道哪些函数会被频繁的调用,优化是很明显的;
- 然后找到瓶颈所在,并去除瓶颈(通过优化或者算法改进)。通常来说改进算法可以很显著地优化瓶颈——甚至可能采用了一个你没想到的算法。优化那些你所知道的将被频繁调用的函数是一个很好的做法;
3. 那些我认识的能够写出非常高效的代码的人说,他们花费在优化代码上的时间是他们写代码时间的至少两倍以上
4. 跳转/分支语句是昂贵的,不管何时尽可能的减少使用
- 函数调用除了栈存储操作外,还需要两次跳转;
- 优先选择迭代,而不是递归;
- 如果是短函数,使用内联来消除函数开销;
- 将循环放在函数内(例如将for(i=0;i<100;i++) DoSomething();改为在DoSomething()内做DoSomething());
- 长长的if...else if...else if...else if...语句链需要大量的跳转才能结束(除了在测试每个条件时)。如果可能,改为switch语句,有时编译器可以有优化为在一个表中查找和单级跳转。如果switch语句是不可能的,那把最经常走到的if语句放在语句链开头;
5. 考虑数组索引的顺序
- 两维或更多维的数组在内存中仍是按一维存储的。这意思是array[i][j]和 array[i][j+1]是相邻的(C/C++代码),然而array[i][j]和array[i+1][j]却可以相离的任意远;
- 访问物理内存中的连续数据,可以显著加快你的代码(有时是一个数量级,甚至更多);
- 现在CPU从主内存中加载数据到高速缓存时,它不仅仅是只加载单一数据,而是加载一块数据,既包含了要请求的数据,也包含部分相邻数据(一个cache行)。这意思是说如果array[i][j]在CPU缓存中,那么array[i][j+1]就很有可能也在缓存中了,然而array[i+1][j]可能仍在内存中;
6. 考虑指令级并行性(IPL)
- 尽管很多程序仍是单线程执行,但现代的CPU已经能够在单核上有显著的并行性。这意味着单CPU也可能同时执行4个浮点数乘法、等待4个内存请求,并执行即将到来的分支比较操作
- 为了充分利用这种并行性,代码块(比如在跳转语句中)需要足够的独立指令来使CPU得到充分使用;
- 可以考虑通过展开循环来改进;
- 这也是使用内联函数的一个很好的原因;
7. 避免或减少局部变量的使用
- 局部变量通常是存储在栈上。如果很少,可以存储在寄存器中。在这种情况下,函数不仅得到了对存储在寄存器上的数据的更快内存访问的好处,也可以避免建立一个栈帧的开销;
- 但是,也不要把所有对象都全盘声明为全局变量;
8. 减少函数参数的个数
- 和减少局部变量的原因一样——他们也是在栈上存储的;
9. 结构体(包括类)传参时使用传引用而不是传值
- 在光线追踪程序中,哪怕是简单如vector、points、colors等结构,我也没有见过使用值传递的代码
10. 如果你不需要一个函数的返回值,那就不要返回
11. 尽可能避免使用转型操作
- 整数和浮点数的指令集通常在不同的寄存器上运算,因此转型操作需要拷贝操作;
- 短整形(char和short)仍然需要一个全尺寸的寄存器,而且在存储回内存之前,它们需要对齐到32位或64位上,然后才转换成更小尺寸类型;
12. 当定义C++对象时一定要小心
- 使用初始化(Color c(black))而不是赋值(Color c, c = black),而前者更快;
13. 使类的默认构造函数尽可能的轻量
- 特别是那简单的、经常使用的类(例如,颜色,矢量,点等);
- 这些默认构造函数通常是在你不注意时就调用,甚至那时你并不希望这样;
- 使用构造初始化列表(使用Color::Color() : r(0), g(0), b(0) {}而不是Color::Color() { r = g = b = 0; } );
14. 尽可能使用移位操作符>>和<<,而不是整数乘法和除法
15. 小心使用查表功能
- 很多人鼓励对于复杂的功能(例如,三角函数)使用预先计算过值的查表法。对于光线跟踪程序来说,这往往是不必要的。内存查找是非常(日益)昂贵的,而且重新计算三角函数往往和从内存中查找值一样快(尤其是当你考虑到内存查找会影响CPU缓存命中率时);
- 在其它情况下,查表可能是非常有用的。比如在GPU编程中,查表法通常是复杂功能的优先选择;
16. 对于大多数的类类型,使用运算符 +=,-=,*=和/=,而少用+,-,*,/
- 这类简单操作其实需要创建一个匿名名的、临时的中间对象;
- 例如Vector v = Vector(1,0,0) + Vector(0,1,0) + Vector(0,0,1) 语句创建了5个未命名、临时的Vector:Vector(1,0,0), Vector(0,1,0),Vector(0,0,1),Vector(1,0,0) + Vector(0,1,0),以及Vector(1,0,0) + Vector(0,1,0) + Vector(0,0,1);
- 稍微更好点的做法:Vector v(1,0,0); v+= Vector(0,1,0); v+= Vector(0,0,1); 这样仅仅创建了2个临时Vector:Vector v(1,0,0) 和Vector(0,0,1),而节省了6个函数调用(3个构造和3个析构);
17. 对于基本数据类型,使用运算符+,-,*,/,而少用+=,-=,*=和/=
18. 延迟局部变量的定义时间
- 定义一个对象总会有一个函数调用开销(就是构造函数)
- 如果一个对象只是有时候才被使用(比如在一个if语句内部),那么就只在必要时才定义,因为这样就只当这个变量使用时才会调用它的构造函数
19. 对于对象来说,使用前缀操作符(++obj),而不是后缀操作符(obj++)
- 在你的光线追踪程序中,这可能并不是个问题
- 对象的拷贝操作必须使用后缀操作符(这需要额外调用一个构造和一个析构函数),而前缀操作符并不产生临时对象
20. 慎用模板
- 各种具现化实例的优化方式可能是不同的;
- 标准模板库(STL)做了很好的优化,但如果你打算实现交互式光线跟踪器,最好是仍避免使用;
- 通过自己实现,你能清楚地明白要它使用的算法,你就会知道最有效的使用方式;
- 更重要的是,我的经验表明调试、编译STL会很慢。通常这也是没问题的,除非你使用Debug版本进行性能分析。你会发现STL的构造、迭代器等操作会占用运行时间的15%以上,它会使输出的分析结果更为混乱
21. 在计算过程中避免动态内存分配
- 动态内存主要优势在于存储场景数据和其他数据,而不是在计算过程中进行修改
- 然而,在许多(大多数)时候系统动态存储分配要求使用锁来控制访问分配器。对于使用动态内存的多线程应用程序来说,由于需要等待分配和释放内存,通过这些额外的处理,你可能实际上得到的是一个更慢的程序
- 即使在单线程程序中,在堆上分配内存也比在栈上分配更昂贵。操作系统需要进行一些计算来确定所需大小的内存块。
22. 发现和充分利用有关你的系统内存Cache的有用信息
- ü 如果一个数据结构大小恰好填满一个Cache行,处理整个类只需要从内存中读取一次;
- ü 确保所有的数据结构都能对齐到Cache边界(如果你的数据大小和Cache都是128字节,那么当1个字节在一个Cache行而另外127字节在第二个Cache行时,那么性能仍然不好)
23. 避免不必要的数据初始化
- 如果你要初始化一大块内存,考虑用memset()函数
24. 尽量提早结束循环判断和函数返回
- 考虑射线和三角形相交。常见情况是射线和三角形不相交,因此这里可以优化;
- 如果你要判断射线和三角形相交的情况,一旦t值射线平面为负,你可以立即返回。这样可以使你跳过大约一半的光线三角形交叉点的重心坐标计算。一个巨大的胜利!一旦你确定没有相交发生,求交函数就应该退出
- 同样的,一些循环也可以被提早结束。例如,在光线阴影设置中,最近的相交是不必要的。只要发现了任何交叉闭环,求交函数就可以返回
25. 先在纸上简化你使用的公式
- 在很多公式中,总是可以或者一些特殊情况下,可以取消计算
- 编译器找不到这些简化,但是你可以。消除一些内在循环中的昂贵操作可以比你在其他地方的优化更能加速你的程序
26. 对于整数型、定点数、32位浮点数、64位浮点数来说,他们之间的差别并没有你想象中的那么大
- 现代CPU进行浮点运算和整数运算其实有相同的运算吞吐量,像光线追踪这种计算密集型的程序,这意思是整数和浮点运算成本之间的差异可以忽略不计,这意味着你不需要做一些优化来使用整数运算;
- 双精度浮点运算并不一定比单精度浮点计算更慢,尤其是在64位机器上。我曾经在同一台机器上测试光线追踪算法,结果是有时全部使用double比全部使用float会运行得更快,
27. 考虑通过重写你的数学公式来消除昂贵的操作
- sqrt()函数通常是可以避免的,尤其是在比较数值的平方是否相等时;
- 如果你需要反复除以x,考虑计算1/x,然后相乘。在向量的归一化操作中(3次除法),这曾经是一个很大的优化,但最近我发现这很难说。然而如果你整除更多次数,这样做仍是有益的;
- 如果你执行一个循环操作,将那些在循环中固定不变的计算移出到循环外;
- 考虑是否能够在计算循环自增中得到值(而不是每次迭代都计算),原文:Consider if you can compute values in a loop incrementally (instead of computing from scratch each iteration).
优化C/C++代码的小技巧
标签:style blog http color io os 使用 ar strong
原文地址:http://www.cnblogs.com/lizhenghn/p/3969531.html