标签:需要 .com 技术分享 移动 学习笔记 nbsp html 操作 ges
Ng的机器学习课,课程资源: cs229-课件 网易公开课-视频
五元组{S、a、Psa、γ、R},分别对应 {状态、行为、状态s下做出a行为的概率、常数、回报}。
选择一个policy以获得最佳报酬:E[R(s0)+γR(s1)+γ2R(s2)+......],常数γ的存在可以保证尽量快地获得收益。
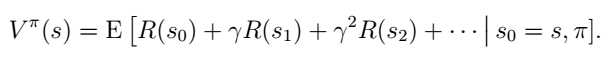
根据贝尔曼方程,
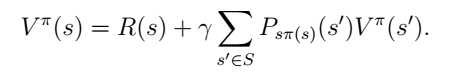
R(s)表示执行此策略获得的直接收益,后面那一堆是执行了此策略以后再后面的行为获得的收益。
最优策略满足:
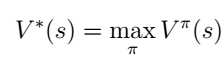
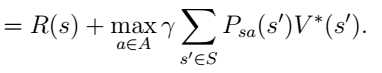
那么在s状态下的最有策略是满足以下等式的行为:
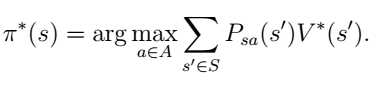
这样,就可以迭代计算了。
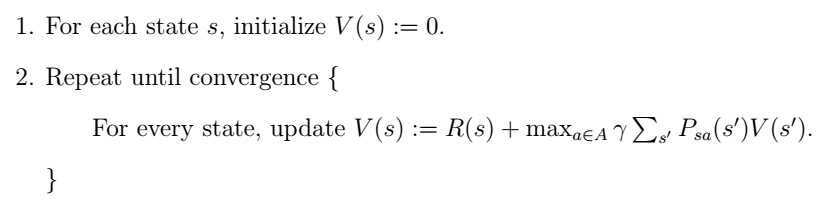
但实际操作中Psa是未知的,所以需要先统计次数,针对课上举的机器人移动的例子,Ng解释说可以先让机器人随便走,统计到达每个状态的次数。
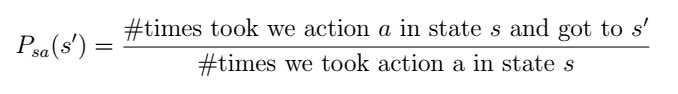
所以强化学习的完整实现过程是这样:

CS229 - MachineLearning - 12 强化学习笔记
标签:需要 .com 技术分享 移动 学习笔记 nbsp html 操作 ges
原文地址:http://www.cnblogs.com/zhengmeisong/p/7853175.html