标签:源代码 网络 通道 准确率 sof 机器学习 blog nbsp pool
归纳卷积神经网络的常用算法
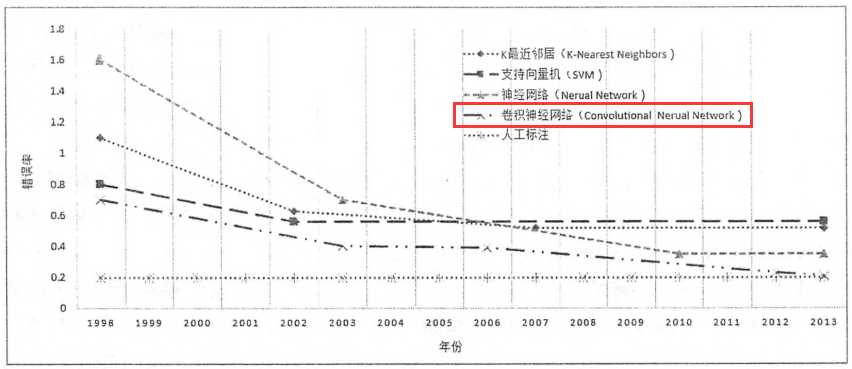
在卷积算法之前,是有很多图片分类和识别的机器学习算法,像SVM向量机的原理特别复杂,卷积算法还是比较易懂,一方面避免全连接带来的庞大参数,主要通过提取特征值,算法准确率也是最高的,几乎可以跟人工识别相提并论了。
经典算法:
1,LeNet算法:
LeNet算法的流程是:
Input –>conv2->relu->pool->conv2->relu->pool->CF->softmax->output
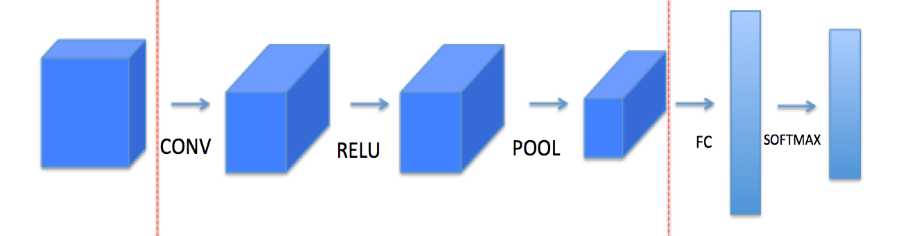
Input:输入; 矩阵为(w,h,c) w:宽的像素;h:高的像素;c:通道
Conv:卷积计算
卷积就是把一个图层(w,h)
Conv2:表示二维图的卷积
一个图层可能是64*64,通过W过滤层为(6,6) 通常有多个过滤层,输出层为矩阵维度为64-6+1=59 ,即(59,59)
以下面的图简单为例:
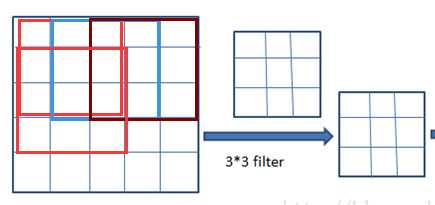
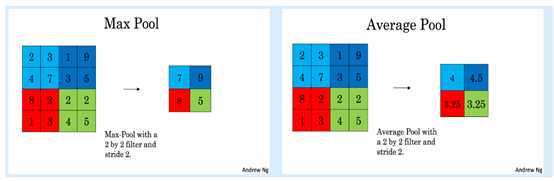
Pool:是池化操作,可能翻译原因表述不一样,池化层是单层的,池化层分为最大值池化和平均值池化;其实,也就是提取特征值最明显的值,最大值池化的效果相对来说更好,所以建议使用。
FC:也就是全连接了,即WX+b=Y
Softmax:归一化的处理,分类
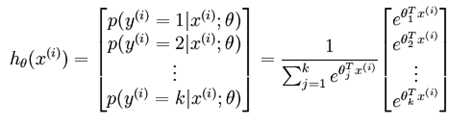
在conv2到pool过程中,还有一层no_linear_normal的操作,也是比较难懂,作用似乎没那么大,就被忽略了。
2,AlexNet算法:
其实就是一个leNet的变形,先来看一张图:
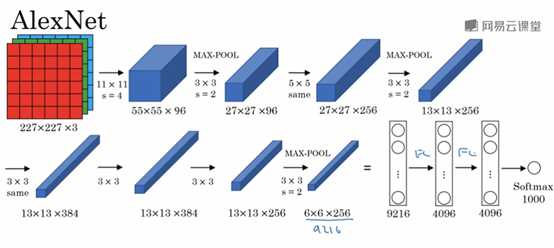
大体过程可分为:
Input->conv2->pool->conv2->pool->pool->pool->pool->pool->FC->FC->FC->softmax
当然中间还有一些relu激化函数就略过了,在激活函数前会通过LRN进行局部归一化,减少使用复杂的激化函数。
3,VGG-16 算法:
VGG-16 跟VGG-19算法 主要是在层次多少区别,算法效果差不多,所以一般建议使用VGG-16
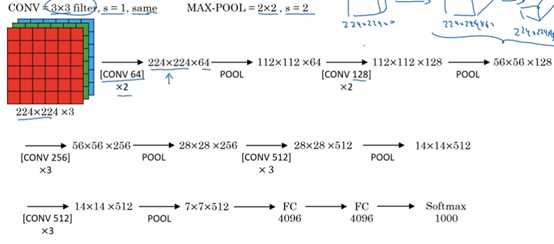
VGG算法跟alexNet的最大不同是这个算法重点是conv2卷积多次,达到集中特征收集的目的
==========================================================
高效的算法:
残差算法:ResNet算法
卷积算法,流程都是通过多个过滤器进行特征值提取,中间的过程容易造成层次越多,原始特征丢失越严重,损失函数在逆向优化时梯度下降太快,所以需要加一些特征优化降低这个速度。对于一些神经深度越大的,这种算法越见优势。
首先来一般的神经深度过程:
Input –>linear->rule->linear->relu->a
而resNet是加了一步
Input –>linear->rule->linear->?->relu->a
运算过程: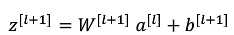
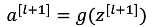
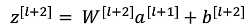
接下来是:?

不是,这样网络越大,会增加错误几率,所以得保真:
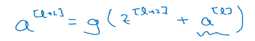
把上上步的a[L] 拿过来加进去求激活函数,这样就能保真。再看一张图:
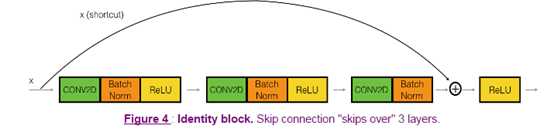
总体的流程如图:

这不是真正的跳跃,而是把原先的a值拿来求激活函数。
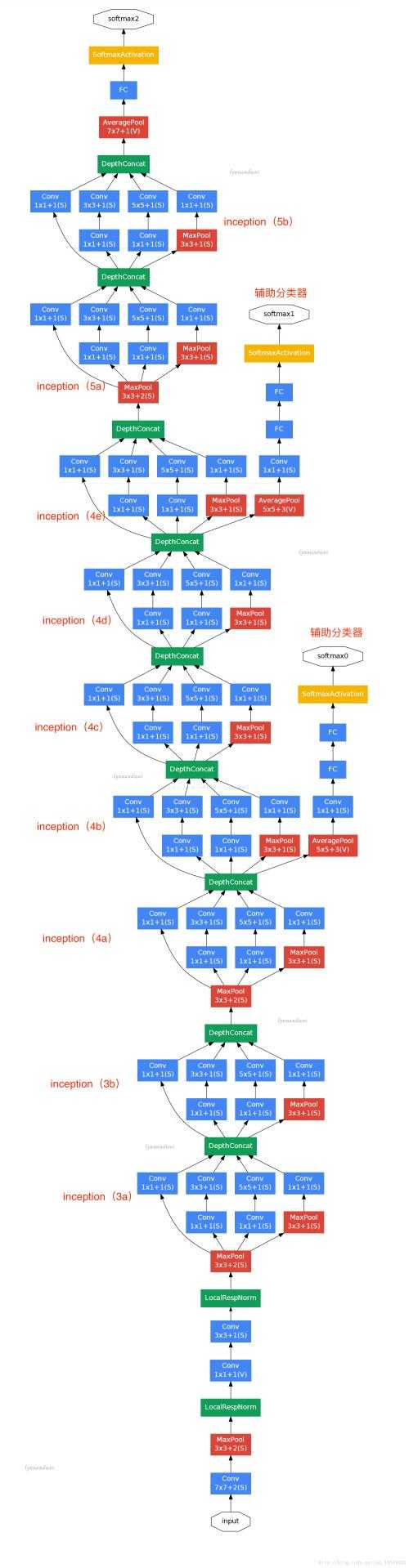
Inception network 算法
其实是谷歌的一个卷积算法 googleNet,这个算法真的比较负责,当然他的深度可以很深,也可以通过增加卷积的conv2的层次,识别一张图片里的多个事物;首先,我们先来一张图:
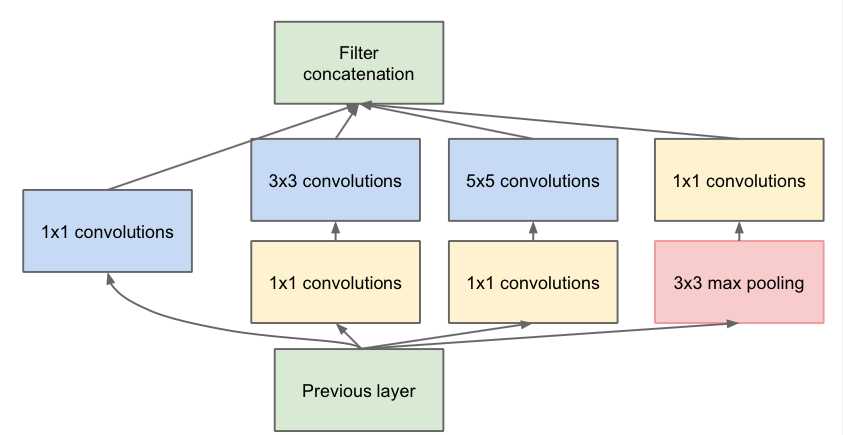
Previous layer是前一层 激活函数之后的
然后进行conv2或者pool进行,然后把各个层的卷积组成一个大的卷积。
有辅助卷积是可以识别出更多的物体。
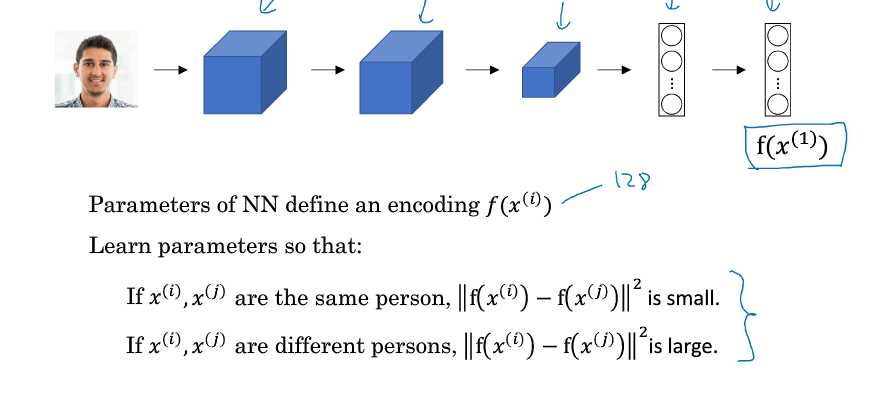
FaceNet算法 是人物识别
人物识别通常可用于监控,或者关卡或者上班的脸谱识别,通过卷积然后根据卷积后的CF后的特征计算误差;通常会需要某个人物的十多张图片作为训练,然后再找其他的图片作为对比。
自己本人图片的计算误差小于等于跟他人图片的误差
这里只是作为学习的一个总结,具体实现要leNet-5,googleNet,inception Network, faceNet等关键词去githup搜索相应的开源代码去研究;这些都是开源出来的,至少你可以查到他的论文,不过几乎都是英文。这才原汁原味。
参考:吴恩达视频教程
标签:源代码 网络 通道 准确率 sof 机器学习 blog nbsp pool
原文地址:http://www.cnblogs.com/minsons/p/7879047.html