标签:ati svm splay osal ring alt 一个个 卷积 cal
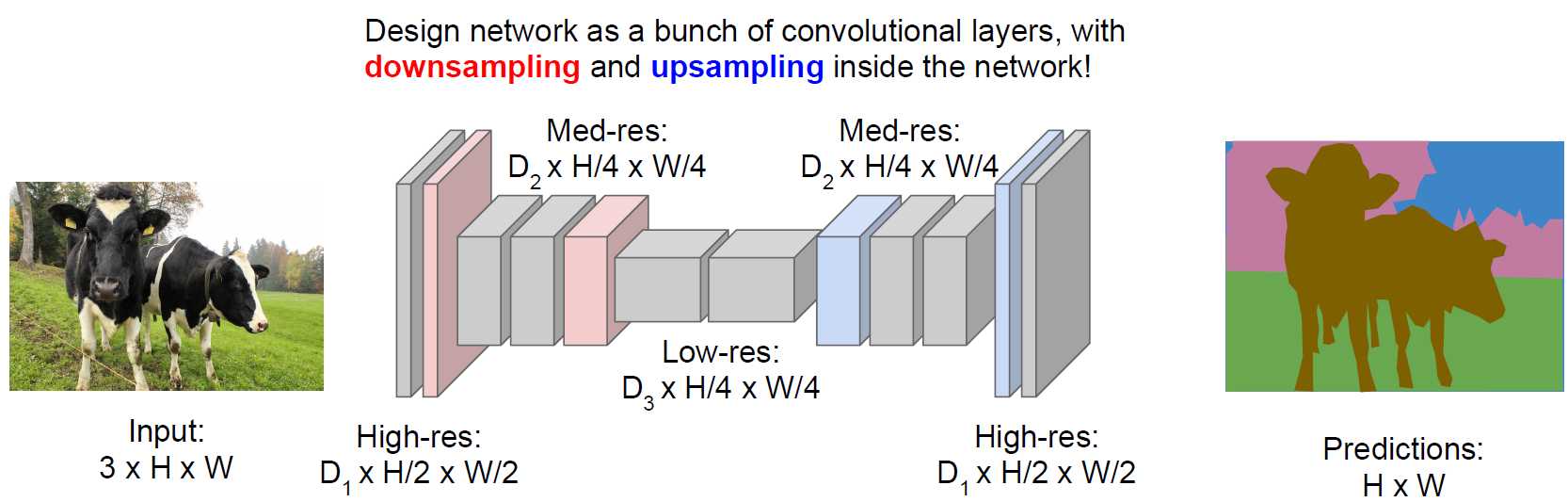
1. Semantic Segmentation
把每个像素分类到某个语义。
为了减少运算量,会先降采样再升采样。降采样一般用池化层,升采样有各种“Unpooling”、“Transpose Convolution”(文献中也叫“Upconvolution”之类的其他名字)。
这个问题的训练数据的获得非常昂贵,因为需要一个像素一个像素的贴标签。
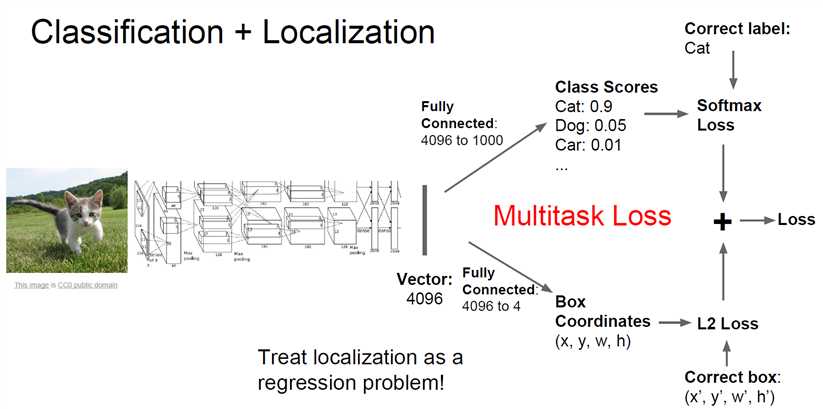
2. Classification + Localizatoin
一般用同一个网络,一方面得出分类,一方面得出Bounding box的位置和大小。
3. Object Detection
预先设定好要找哪些objects,一旦图片里发现,就框出来。Classification + Localizatoin一般是针对单个物体,而这里是针对多个物体。
Sliding window:计算量太大,舍弃。
Region Proposals:先找可能有物体的图片区域,然后一个个处理,在CPU上大概几秒的时间。这种方法在深度学习之前就出来了。
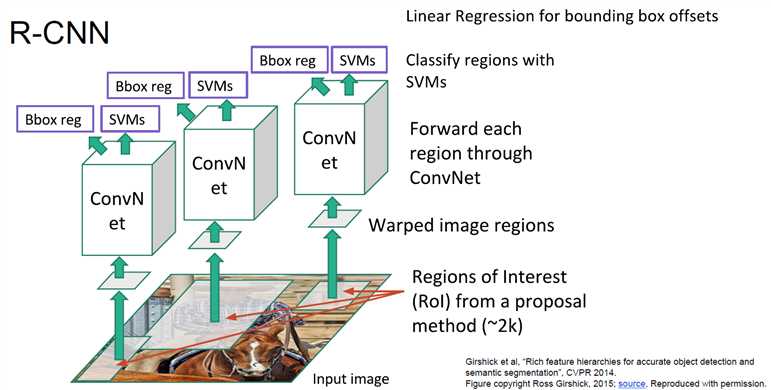
R-CNN:先找出region proposal,然后把region proposal调整成神经网络需要的大小,然后给神经网络计算,最后通过SVM分类。
训练很慢(84h),也非常耗内存。预测也很慢(47秒 VGG16)
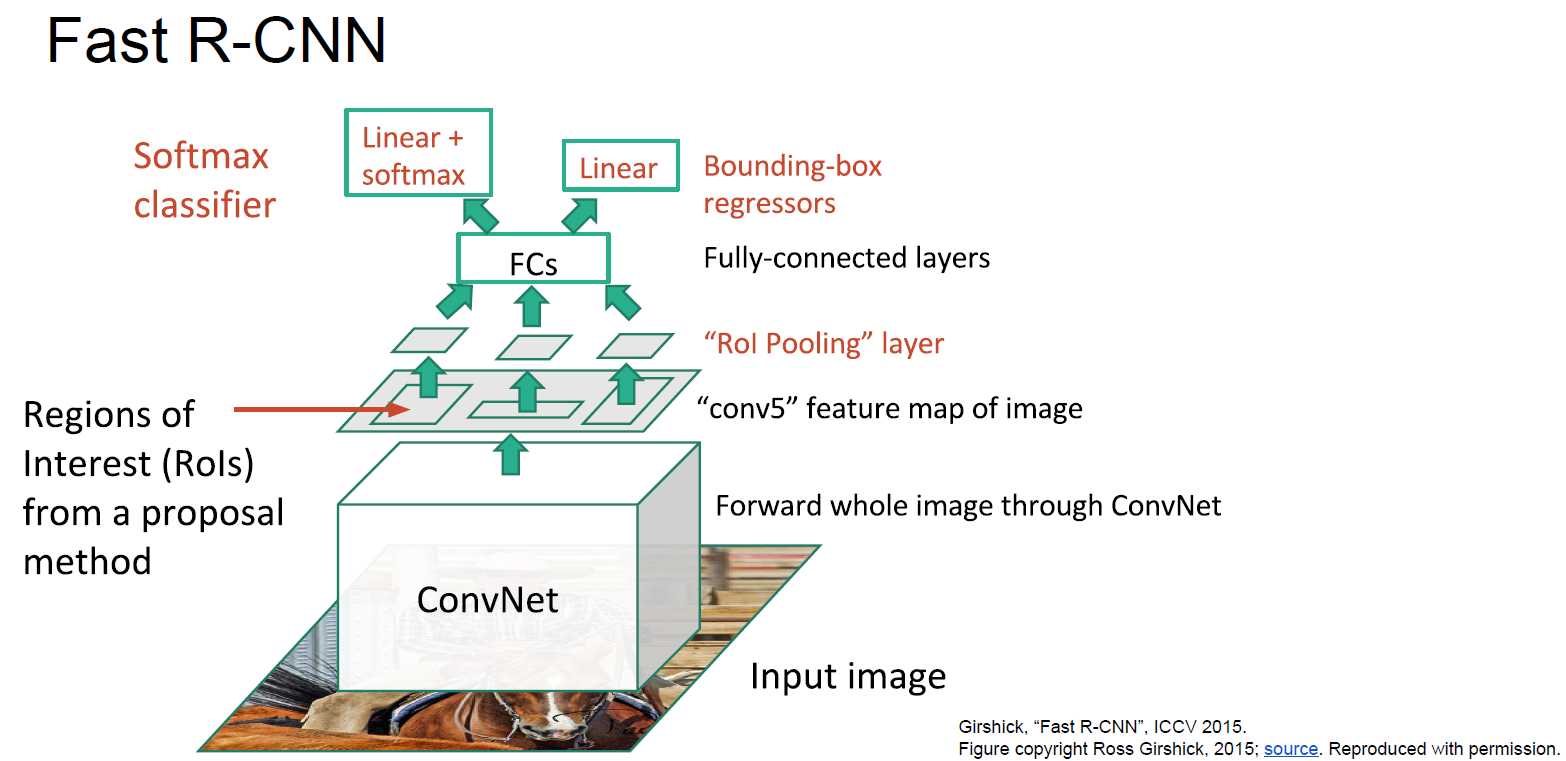
Fast R-CNN:相比R-CNN快很多,训练(8.75h),预测(计算region proposal花2秒,神经网络预测花0.32秒)。
训练的时候把下图中的Linear + softmax和Linear加起来得到multi-task loss。
Faster R-CNN:用卷积层去预测region proposal。比Fast R-CNN更快,预测耗时0.2秒。
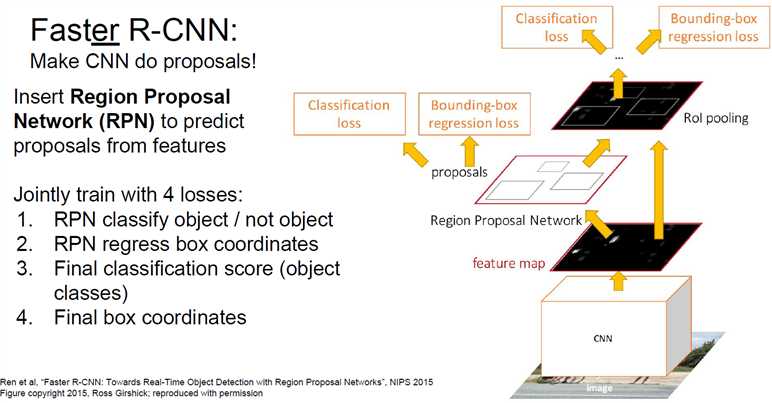
YOLO(Redmon et al., CVPR 2016)/SSD(Liu et al, "Single-Shot MultiBox Detecotr", ECCV 2016):这两种方法没有用region proposal,更快,但是相对不那么准。Faster R-CNN更慢,但是更准。
Object Detection + Captioning (DenseCap, CVPR 2016)
4. Instance Segmentation
Semantic Segmentation和Object Detection的结合,找出多个物体,并且判断每个像素属于哪个分类。
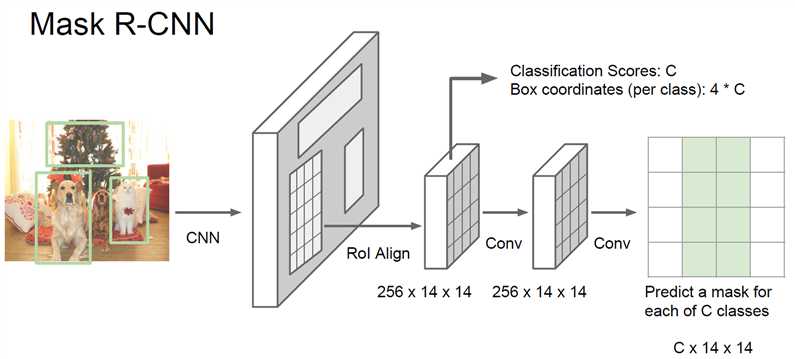
Mask R-CNN (He et al., 2017),网络有两个分支,第一个执行Object Detection,第二个执行Semantic Segmentation。这个网络把之前的都融合起来,是集大成者,表现非常非常好。在Object Detection分支加入对人体关节的识别,还能识别人的pose。基于Faster R-CNN,接近real-time。
cs231n spring 2017 lecture11 听课笔记
标签:ati svm splay osal ring alt 一个个 卷积 cal
原文地址:http://www.cnblogs.com/zonghaochen/p/8001357.html