PhantomJS是一种没有界面的浏览器,便于爬虫
1、PhantomJS下载
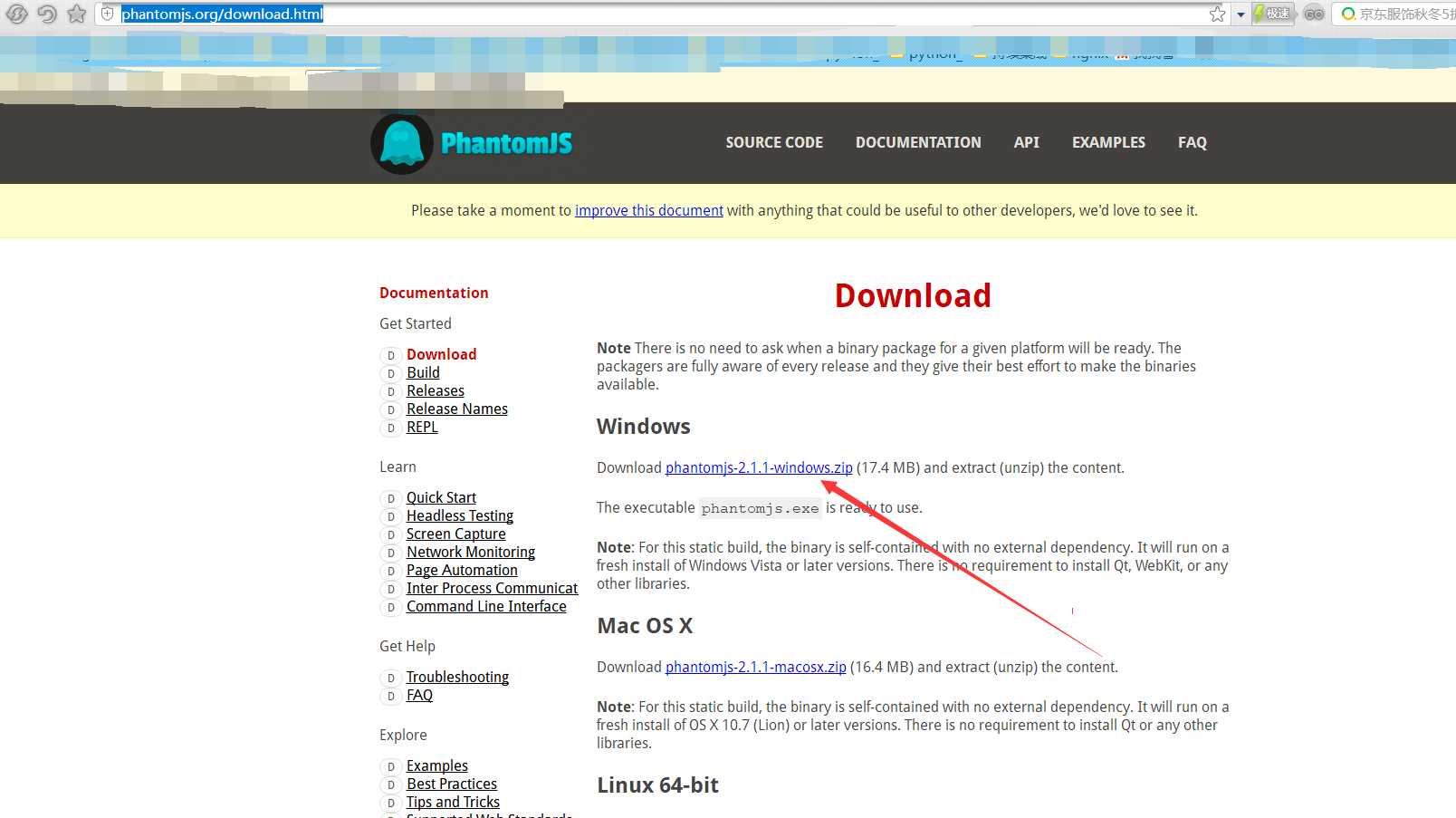
2、phantomjs无须安装driver,还有具体的api参考:
http://phantomjs.org/api/command-line.html
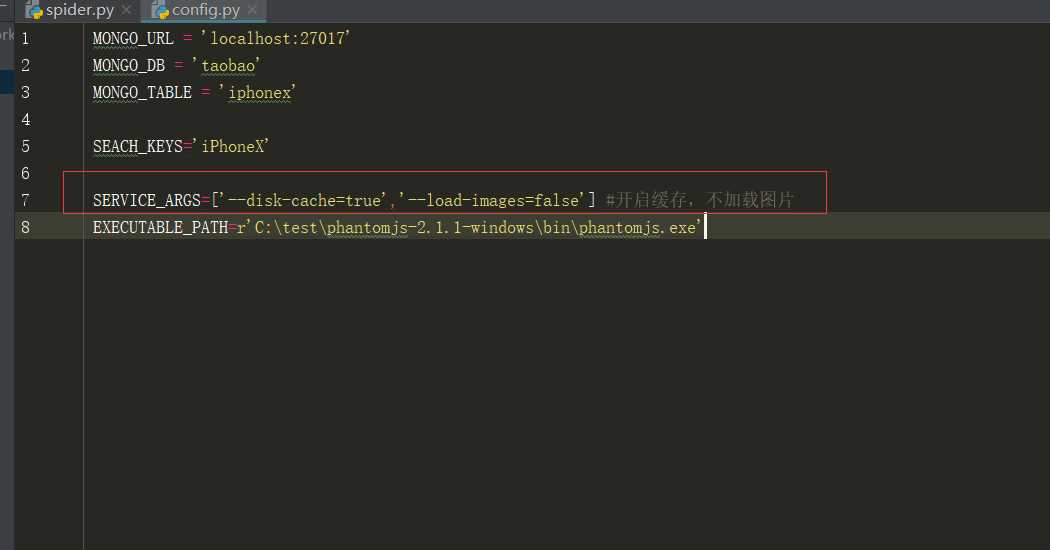
3、配置config.py
1 MONGO_URL = ‘localhost:27017‘ 2 MONGO_DB = ‘taobao‘ 3 MONGO_TABLE = ‘iphonex‘ 4 5 SEACH_KEYS=‘iPhoneX‘ 6 7 SERVICE_ARGS=[‘--disk-cache=true‘,‘--load-images=false‘] #开启缓存,不加载图片 8 EXECUTABLE_PATH=r‘C:\test\phantomjs-2.1.1-windows\bin\phantomjs.exe‘
4、爬取如下spider.py
1 import re 2 3 from selenium import webdriver 4 from selenium.common.exceptions import TimeoutException 5 from selenium.webdriver.common.by import By 6 from selenium.webdriver.support.ui import WebDriverWait 7 from selenium.webdriver.support import expected_conditions as EC 8 from pyquery import PyQuery as pq 9 from config import * 10 import pymongo 11 12 client=pymongo.MongoClient(MONGO_URL) 13 db=client[MONGO_DB] 14 15 # browser = webdriver.Chrome() 16 browser=webdriver.PhantomJS(executable_path=EXECUTABLE_PATH,service_args=SERVICE_ARGS) 17 18 wait=WebDriverWait(browser,20) 19 browser.maximize_window() #窗口最大化避免出问题 20 def save_to_mongo(result): 21 try: 22 if db[MONGO_TABLE].insert(result): 23 print(‘存储到MongoDB成功‘,result) 24 except Exception: 25 print(‘存储到MongoDB失败‘,result) 26 27 def search(search_key): 28 try: 29 browser.get("http://www.taobao.com") 30 input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))#直到定位到这个元素 31 submit= wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button"))) #等到元素可点击 32 input.send_keys(search_key) 33 submit.click() 34 total_pages=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,‘#mainsrp-pager > div > div > div > div.total‘))) 35 return total_pages.text 36 except TimeoutException: 37 return search() #超时重试 38 39 def next_page(page_number): 40 try: 41 input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))) 42 submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))) 43 input.clear() 44 input.send_keys(page_number) 45 submit.click() 46 wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,‘#mainsrp-pager > div > div > div > ul > li.item.active > span‘),str(page_number)))#判断元素中的值是否和指定内容一致 47 get_product() 48 print(page_number) 49 except TimeoutException: 50 print(‘超时‘) 51 return next_page(page_number) #超时重试 52 53 def get_product(): 54 wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,‘#mainsrp-itemlist .items .item‘))) 55 html=browser.page_source 56 doc=pq(html) 57 items=doc(‘#mainsrp-itemlist .items .item‘).items() 58 for item in items: 59 product={ 60 ‘image‘:item.find(‘.pic img‘).attr(‘src‘), 61 ‘price‘:item.find(‘.price‘).text(), 62 ‘deal‘:item.find(‘.deal-cnt‘).text()[:-3], 63 ‘title‘:item.find(‘.title‘).text(), 64 ‘shop‘:item.find(‘.location‘).text() 65 } 66 save_to_mongo(product) 67 68 def main(): 69 try: 70 total=search(search_key=SEACH_KEYS) 71 total=int(re.compile(‘(\d+)‘).search(total).group(1)) 72 for i in range(2, total+1): 73 next_page(i) 74 except Exception: 75 print(‘出错啦‘) 76 finally: 77 browser.close() 78 79 80 if __name__==‘__main__‘: 81 main()