此脚本读取的是 SQL Server ,只需给定表名或视图名称,如果有数据,将输出每个字段符合要求的每张数据分布图。
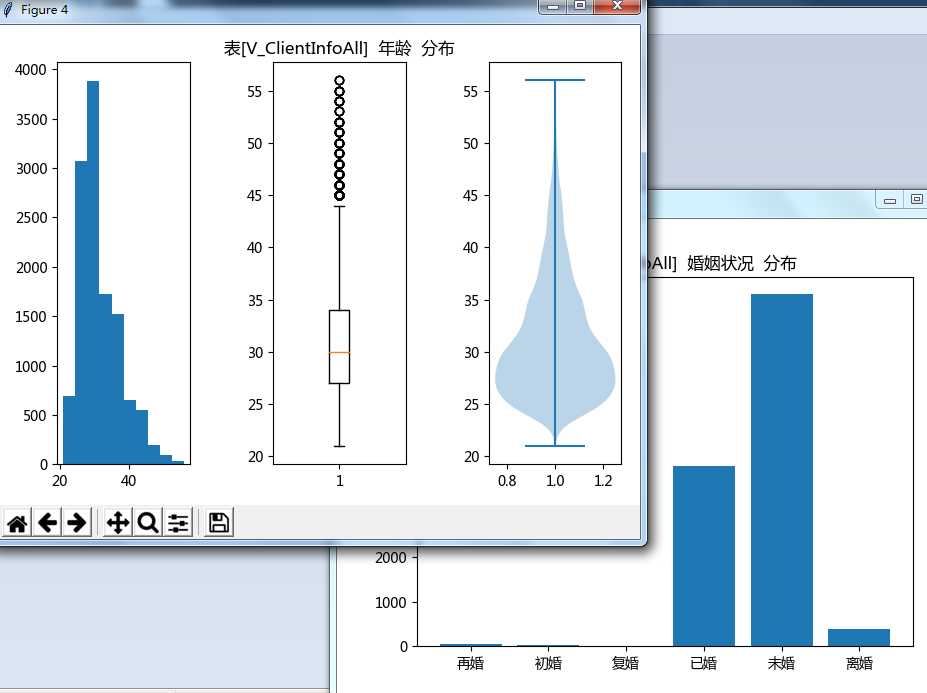
# -*- coding: UTF-8 -*- # python 3.5.0 # 探索性数据分析(Exploratory Data Analysis,EDA) __author__ = ‘HZC‘ import math import sqlalchemy import numpy as np import pandas as pd import matplotlib.pyplot as plt class EDA: def __init__(self,d): self.engine = sqlalchemy.create_engine("mssql+pymssql://%s:%s@%s/%s" %(d[‘user‘],d[‘pwd‘],d[‘ins‘],d[‘db‘])) def get_df_from_table(self,table_name): df = pd.read_sql_table(table_name, self.engine) return df def get_df_from_query(self,sql): df = pd.read_sql_query(sql, self.engine) return df #读取表各字段数据类型 def get_table_type(self,table_name): sql = """select c.name as colname,t.name as typename from sys.sysobjects o inner join syscolumns c on o.id=c.id and o.name<>‘dtproperties‘ inner join sys.systypes t on c.xusertype=t.xusertype where o.name=‘%s‘""" % table_name df = self.get_df_from_query(sql) return df #绘图 def eda_plot(self,table_name): list_char = [‘char‘,‘nchar‘,‘varchar‘,‘nvarchar‘,‘text‘,‘ntext‘,‘sysname‘] list_num = [‘tinyint‘,‘smallint‘,‘int‘,‘real‘,‘money‘,‘float‘,‘decimal‘,‘numeric‘,‘smallmoney‘,‘bigint‘] df_type = self.get_table_type(table_name) df_date = self.get_df_from_table(table_name) date_count = df_date.shape[0] k = 0 for row in df_type.itertuples(): k = k + 1 #字符类型,绘柱状图 if row.typename in list_char: col = df_date.groupby([row.colname]).agg({row.colname:[‘count‘]}) row_count = col.shape[0] #col_count = col.shape[1] col = col.sort_index() val = col.values.tolist() #只绘不重复数占总数比小于 5% 的 if math.floor(row_count*100/date_count) <5: df_ = pd.DataFrame(col.index.values.tolist(), columns=[row.colname]) df_[‘count‘] = list(i[0] for i in val) x_axle = range(len(df_[row.colname])) y_axle = df_[‘count‘].tolist() x_label = df_[row.colname].tolist() fig, ax = plt.subplots() ax.bar(x_axle,y_axle) ax.set_xticks(x_axle) ax.set_xticklabels(x_label) ax.set_title(‘表[%s] %s 分布‘ % (table_name,row.colname)) #数值类型,其他分布图 elif row.typename in list_num: df__ = pd.DataFrame(df_date[row.colname]) df__ = df__[(df__[row.colname].notnull())].sort_values(row.colname, ascending=True).reset_index(drop=True) k = k + 1 plt.figure(k) plt.subplot(1,3,1) plt.hist(df__[row.colname]) plt.subplot(1,3,2) plt.boxplot(df__[row.colname]) plt.gca().set_title(‘表[%s] %s 分布‘ % (table_name,row.colname)) plt.subplot(1,3,3) plt.violinplot(df__[row.colname]) plt.tight_layout() else: pass plt.show() if __name__ == "__main__": conn = {‘user‘:‘kk‘,‘pwd‘:‘kk‘,‘ins‘:‘hzc‘,‘db‘:‘Demo‘} eda = EDA(conn) eda.eda_plot("V_ClientInfoAll")
显示图分为字符型(离散型)和数值型(连续型),示例结果如下: