声明:以下代码,Python版本3.6完美运行
一、思路介绍
不同的图片网站设有不同的反爬虫机制,根据具体网站采取对应的方法
1. 浏览器浏览分析地址变化规律
2. Python测试类获取网页内容,从而获取图片地址
3. Python测试类下载图片,保存成功则爬虫可以实现
二、豆瓣美女(难度:?)
1. 网址:https://www.dbmeinv.com/dbgroup/show.htm
浏览器里点击后,按分类和页数得到新的地址:"https://www.dbmeinv.com/dbgroup/show.htm?cid=%s&pager_offset=%s" % (cid, index)
(其中cid:2-胸 3-腿 4-脸 5-杂 6-臀 7-袜子 index:页数)
2. 通过python调用,查看获取网页内容,以下是Test_Url.py的内容
1 from urllib import request
2 import re
3 from bs4 import BeautifulSoup
4
5
6 def get_html(url):
7 req = request.Request(url)
8 return request.urlopen(req).read()
9
10
11 if __name__ == ‘__main__‘:
12 url = "https://www.dbmeinv.com/dbgroup/show.htm?cid=2&pager_offset=2"
13 html = get_html(url)
14 data = BeautifulSoup(html, "lxml")
15 print(data)
16 r = r‘(https://\S+\.jpg)‘
17 p = re.compile(r)
18 get_list = re.findall(p, str(data))
19 print(get_list)
通过urllib.request.Request(Url)请求网站,BeautifulSoup解析返回的二进制内容,re.findall()匹配图片地址
最终print(get_list)打印出了图片地址的一个列表
3. 通过python调用,下载图片,以下是Test_Down.py的内容
1 from urllib import request
2
3
4 def get_image(url):
5 req = request.Request(url)
6 get_img = request.urlopen(req).read()
7 with open(‘E:/Python_Doc/Images/DownTest/001.jpg‘, ‘wb‘) as fp:
8 fp.write(get_img)
9 print("Download success!")
10 return
11
12
13 if __name__ == ‘__main__‘:
14 url = "https://ww2.sinaimg.cn/bmiddle/0060lm7Tgy1fn1cmtxkrcj30dw09a0u3.jpg"
15 get_image(url)
通过urllib.request.Request(image_url)获取图片,然后写入本地,看到路径下多了一张图片,说明整个爬虫实现是可实现的
4. 综合上面分析,写出完整爬虫代码 douban_spider.py


1 from urllib import request 2 from urllib.request import urlopen 3 from bs4 import BeautifulSoup 4 import os 5 import time 6 import re 7 import threading 8 9 10 # 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面 11 # 图片地址 12 picpath = r‘E:\Python_Doc\Images‘ 13 # 豆瓣地址 14 douban_url = "https://www.dbmeinv.com/dbgroup/show.htm?cid=%s&pager_offset=%s" 15 16 17 # 保存路径的文件夹,没有则自己创建文件夹,不能创建上级文件夹 18 def setpath(name): 19 path = os.path.join(picpath, name) 20 if not os.path.isdir(path): 21 os.mkdir(path) 22 return path 23 24 25 # 获取html内容 26 def get_html(url): 27 req = request.Request(url) 28 return request.urlopen(req).read() 29 30 31 # 获取图片地址 32 def get_ImageUrl(html): 33 data = BeautifulSoup(html, "lxml") 34 r = r‘(https://\S+\.jpg)‘ 35 p = re.compile(r) 36 return re.findall(p, str(data)) 37 38 39 # 保存图片 40 def save_image(savepath, url): 41 content = urlopen(url).read() 42 # url[-11:] 表示截取原图片后面11位 43 with open(savepath + ‘/‘ + url[-11:], ‘wb‘) as code: 44 code.write(content) 45 46 47 def do_task(savepath, cid, index): 48 url = douban_url % (cid, index) 49 html = get_html(url) 50 image_list = get_ImageUrl(html) 51 # 此处判断其实意义不大,程序基本都是人手动终止的,因为图片你是下不完的 52 if not image_list: 53 print(u‘已经全部抓取完毕‘) 54 return 55 # 实时查看,这个有必要 56 print("=============================================================================") 57 print(u‘开始抓取Cid= %s 第 %s 页‘ % (cid, index)) 58 for image in image_list: 59 save_image(savepath, image) 60 # 抓取下一页 61 do_task(savepath, cid, index+1) 62 63 64 if __name__ == ‘__main__‘: 65 # 文件名 66 filename = "DouBan" 67 filepath = setpath(filename) 68 69 # 2-胸 3-腿 4-脸 5-杂 6-臀 7-袜子 70 for i in range(2, 8): 71 do_task(filepath, i, 1) 72 73 # threads = [] 74 # for i in range(2, 4): 75 # ti = threading.Thread(target=do_task, args=(filepath, i, 1, )) 76 # threads.append(ti) 77 # for t in threads: 78 # t.setDaemon(True) 79 # t.start() 80 # t.join()
运行程序,进入文件夹查看,图片已经不停的写入电脑了!
5. 分析:豆瓣图片下载用比较简单的爬虫就能实现,网站唯一的控制好像只有不能频繁调用,所以豆瓣不适合用多线程调用
豆瓣还有一个地址:https://www.dbmeinv.com/dbgroup/current.htm有兴趣的小朋友可以自己去研究
三、MM131网(难度:??)
1. 网址:http://www.mm131.com
浏览器里点击后,按分类和页数得到新的地址:"http://www.mm131.com/xinggan/list_6_%s.html" % index
(如果清纯:"http://www.mm131.com/qingchun/list_1_%s.html" % index , index:页数)
2. Test_Url.py,双重循化先获取图片人物地址,在获取人物每页的图片
1 from urllib import request
2 import re
3 from bs4 import BeautifulSoup
4
5
6 def get_html(url):
7 req = request.Request(url)
8 return request.urlopen(req).read()
9
10
11 if __name__ == ‘__main__‘:
12 url = "http://www.mm131.com/xinggan/list_6_2.html"
13 html = get_html(url)
14 data = BeautifulSoup(html, "lxml")
15 p = r"(http://www\S*/\d{4}\.html)"
16 get_list = re.findall(p, str(data))
17 # 循化人物地址
18 for i in range(20):
19 # print(get_list[i])
20 # 循环人物的N页图片
21 for j in range(200):
22 url2 = get_list[i][:-5] + "_" + str(j + 2) + ".html"
23 try:
24 html2 = get_html(url2)
25 except:
26 break
27 p = r"(http://\S*/\d{4}\S*\.jpg)"
28 get_list2 = re.findall(p, str(html2))
29 print(get_list2[0])
30 break
3. 下载图片 Test_Down.py,用豆瓣下载的方法下载,发现不论下载多少张,都是一样的下面图片

这个就有点尴尬了,妹子图片地址都有了,就是不能下载,浏览器打开的时候也是时好时坏,网上也找不到原因,当然楼主最终还是找到原因了,下面先贴上代码
1 from urllib import request
2 import requests
3
4
5 def get_image(url):
6 req = request.Request(url)
7 get_img = request.urlopen(req).read()
8 with open(‘E:/Python_Doc/Images/DownTest/123.jpg‘, ‘wb‘) as fp:
9 fp.write(get_img)
10 print("Download success!")
11 return
12
13
14 def get_image2(url_ref, url):
15 headers = {"Referer": url_ref,
16 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ‘
17 ‘(KHTML, like Gecko)Chrome/62.0.3202.94 Safari/537.36‘}
18 content = requests.get(url, headers=headers)
19 if content.status_code == 200:
20 with open(‘E:/Python_Doc/Images/DownTest/124.jpg‘, ‘wb‘) as f:
21 for chunk in content:
22 f.write(chunk)
23 print("Download success!")
24
25
26 if __name__ == ‘__main__‘:
27 url_ref = "http://www.mm131.com/xinggan/2343_3.html"
28 url = "http://img1.mm131.me/pic/2343/3.jpg"
29 get_image2(url_ref, url)
可以看到下载成功,改用requests.get方法获取图片内容,这种请求方法方便设置头文件headers(urllib.request怎么设置headers没有研究过),headers里面有个Referer参数,必须设置为此图片的进入地址,从浏览器F12代码可以看出来,如下图
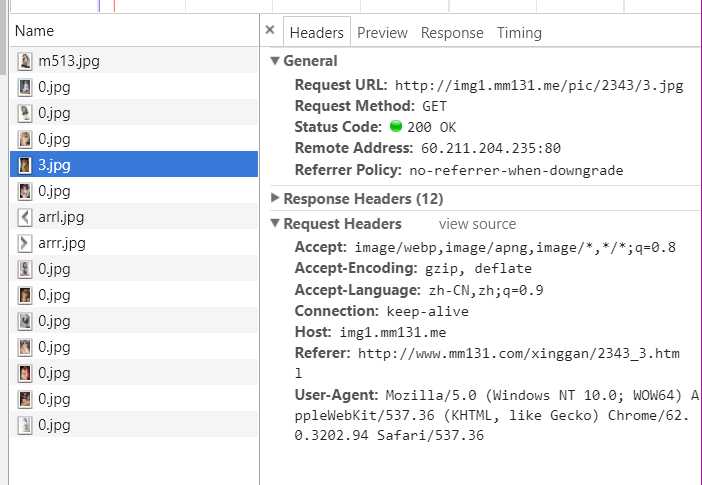
4. 测试都通过了,下面是汇总的完整源码
1 from urllib import request 2 from urllib.request import urlopen 3 from bs4 import BeautifulSoup 4 import os 5 import time 6 import re 7 import requests 8 9 10 # 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面 11 # 图片地址 12 picpath = r‘E:\Python_Doc\Images‘ 13 # mm131地址 14 mm_url = "http://www.mm131.com/xinggan/list_6_%s.html" 15 16 17 # 保存路径的文件夹,没有则自己创建文件夹,不能创建上级文件夹 18 def setpath(name): 19 path = os.path.join(picpath, name) 20 if not os.path.isdir(path): 21 os.mkdir(path) 22 return path 23 24 25 # 获取html内容 26 def get_html(url): 27 req = request.Request(url) 28 return request.urlopen(req).read() 29 30 31 def save_image2(path, url_ref, url): 32 headers = {"Referer": url_ref, 33 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ‘ 34 ‘(KHTML, like Gecko)Chrome/62.0.3202.94 Safari/537.36‘} 35 content = requests.get(url, headers=headers) 36 if content.status_code == 200: 37 with open(path + ‘/‘ + str(time.time()) + ‘.jpg‘, ‘wb‘) as f: 38 for chunk in content: 39 f.write(chunk) 40 41 42 def do_task(path, url): 43 html = get_html(url) 44 data = BeautifulSoup(html, "lxml") 45 p = r"(http://www\S*/\d{1,5}\.html)" 46 get_list = re.findall(p, str(data)) 47 # print(data) 48 # 循化人物地址 每页20个 49 for i in range(20): 50 try: 51 print(get_list[i]) 52 except: 53 break 54 # 循环人物的N页图片 55 for j in range(200): 56 url2 = get_list[i][:-5] + "_" + str(3*j + 2) + ".html" 57 try: 58 html2 = get_html(url2) 59 except: 60 break 61 p = r"(http://\S*/\d{1,4}\S*\.jpg)" 62 get_list2 = re.findall(p, str(html2)) 63 save_image2(path, get_list[i], get_list2[0]) 64 65 66 if __name__ == ‘__main__‘: 67 # 文件名 68 filename = "MM131_XG" 69 filepath = setpath(filename) 70 71 for i in range(2, 100): 72 print("正在List_6_%s " % i) 73 url = mm_url % i 74 do_task(filepath, url)
运行程序后,图片将源源不断的写入电脑
5. 分析:MM131图片下载主要问题是保存图片的时候需要用headers设置Referer
四、煎蛋网(难度:???)
1. 网址:http://jandan.net/ooxx
浏览器里点击后,按分类和页数得到新的地址:http://jandan.net/ooxx/page-%s#comments % index
(index:页数)
2. Test_Url.py,由于通过urllib.request.Request会被拒绝
通过requests添加headers,返回的html文本如下
1 ......
2 <div class="text">
3 <span class="righttext">
4 <a href="//jandan.net/ooxx/page-2#comment-3535967">3535967</a>
5 </span>
6 <p>
7 <img src="//img.jandan.net/img/blank.gif" onload="jandan_load_img(this)" />
8 <span class="img-hash">d0c4TroufRLv8KcPl0CZWwEuhv3ZTfJrTVr02gQHSmnFyf0tWbjze3F+DoWRsMEJFYpWSXTd5YfOrmma+1CKquxniG2C19Gzh81OF3wz84m8TSGr1pXRIA</span>
9 </p>
10 </div>
11 ......
从上面关键结果可以看到,<span class="img-hash">后面的一长串哈希字符才是图片地址,网站打开时候动态转换位图片地址显示的,这个时候只想说三个字MMP
不过上有政策,下有对策,那就把这些hash字符串转为图片地址了,怎么转呢? 以下提供两种方案
(1)通过Python的execjs模块直接调用JS里面的函数,将这个hash转为图片地址,具体实现就是把当前网页保存下来,然后找到里面的js转换方法函数,单独拎出来写在一个JS里面
调用的JS和方法如下:OOXX1.js CallJS.python
1 function OOXX1(a,b) {
2 return md5(a)
3 }
4 function md5(a) {
5 return "Success" + a
6 }
1 import execjs
2
3
4 # 执行本地的js
5 def get_js():
6 f = open("OOXX1.js", ‘r‘, encoding=‘UTF-8‘)
7 line = f.readline()
8 htmlstr = ‘‘
9 while line:
10 htmlstr = htmlstr + line
11 line = f.readline()
12 return htmlstr
13
14
15 js = get_js()
16 ctx = execjs.compile(js)
17 ss = "SS"
18 cc = "CC"
19 print(ctx.call("OOXX1", ss, cc))
此种方法只提供思路,楼主找到的JS如下 OOXX.js,实际调用报错了,这个方法应该会比方法二速度快很多,所以还是贴上未完成代码供读者参阅研究
1 function time() { 2 var a = new Date().getTime(); 3 return parseInt(a / 1000) 4 } 5 function microtime(b) { 6 var a = new Date().getTime(); 7 var c = parseInt(a / 1000); 8 return b ? (a / 1000) : (a - (c * 1000)) / 1000 + " " + c 9 } 10 function chr(a) { 11 return String.fromCharCode(a) 12 } 13 function ord(a) { 14 return a.charCodeAt() 15 } 16 function md5(a) { 17 return hex_md5(a) 18 } 19 function base64_encode(a) { 20 return btoa(a) 21 } 22 function base64_decode(a) { 23 return atob(a) 24 } (function(g) { 25 function o(u, z) { 26 var w = (u & 65535) + (z & 65535), 27 v = (u >> 16) + (z >> 16) + (w >> 16); 28 return (v << 16) | (w & 65535) 29 } 30 function s(u, v) { 31 return (u << v) | (u >>> (32 - v)) 32 } 33 function c(A, w, v, u, z, y) { 34 return o(s(o(o(w, A), o(u, y)), z), v) 35 } 36 function b(w, v, B, A, u, z, y) { 37 return c((v & B) | ((~v) & A), w, v, u, z, y) 38 } 39 function i(w, v, B, A, u, z, y) { 40 return c((v & A) | (B & (~A)), w, v, u, z, y) 41 } 42 function n(w, v, B, A, u, z, y) { 43 return c(v ^ B ^ A, w, v, u, z, y) 44 } 45 function a(w, v, B, A, u, z, y) { 46 return c(B ^ (v | (~A)), w, v, u, z, y) 47 } 48 function d(F, A) { 49 F[A >> 5] |= 128 << (A % 32); 50 F[(((A + 64) >>> 9) << 4) + 14] = A; 51 var w, z, y, v, u, E = 1732584193, 52 D = -271733879, 53 C = -1732584194, 54 B = 271733878; 55 for (w = 0; w < F.length; w += 16) { 56 z = E; 57 y = D; 58 v = C; 59 u = B; 60 E = b(E, D, C, B, F[w], 7, -680876936); 61 B = b(B, E, D, C, F[w + 1], 12, -389564586); 62 C = b(C, B, E, D, F[w + 2], 17, 606105819); 63 D = b(D, C, B, E, F[w + 3], 22, -1044525330); 64 E = b(E, D, C, B, F[w + 4], 7, -176418897); 65 B = b(B, E, D, C, F[w + 5], 12, 1200080426); 66 C = b(C, B, E, D, F[w + 6], 17, -1473231341); 67 D = b(D, C, B, E, F[w + 7], 22, -45705983); 68 E = b(E, D, C, B, F[w + 8], 7, 1770035416); 69 B = b(B, E, D, C, F[w + 9], 12, -1958414417); 70 C = b(C, B, E, D, F[w + 10], 17, -42063); 71 D = b(D, C, B, E, F[w + 11], 22, -1990404162); 72 E = b(E, D, C, B, F[w + 12], 7, 1804603682); 73 B = b(B, E, D, C, F[w + 13], 12, -40341101); 74 C = b(C, B, E, D, F[w + 14], 17, -1502002290); 75 D = b(D, C, B, E, F[w + 15], 22, 1236535329); 76 E = i(E, D, C, B, F[w + 1], 5, -165796510); 77 B = i(B, E, D, C, F[w + 6], 9, -1069501632); 78 C = i(C, B, E, D, F[w + 11], 14, 643717713); 79 D = i(D, C, B, E, F[w], 20, -373897302); 80 E = i(E, D, C, B, F[w + 5], 5, -701558691); 81 B = i(B, E, D, C, F[w + 10], 9, 38016083); 82 C = i(C, B, E, D, F[w + 15], 14, -660478335); 83 D = i(D, C, B, E, F[w + 4], 20, -405537848); 84 E = i(E, D, C, B, F[w + 9], 5, 568446438); 85 B = i(B, E, D, C, F[w + 14], 9, -1019803690); 86 C = i(C, B, E, D, F[w + 3], 14, -187363961); 87 D = i(D, C, B, E, F[w + 8], 20, 1163531501); 88 E = i(E, D, C, B, F[w + 13], 5, -1444681467); 89 B = i(B, E, D, C, F[w + 2], 9, -51403784); 90 C = i(C, B, E, D, F[w + 7], 14, 1735328473); 91 D = i(D, C, B, E, F[w + 12], 20, -1926607734); 92 E = n(E, D, C, B, F[w + 5], 4, -378558); 93 B = n(B, E, D, C, F[w + 8], 11, -2022574463); 94 C = n(C, B, E, D, F[w + 11], 16, 1839030562); 95 D = n(D, C, B, E, F[w + 14], 23, -35309556); 96 E = n(E, D, C, B, F[w + 1], 4, -1530992060); 97 B = n(B, E, D, C, F[w + 4], 11, 1272893353); 98 C = n(C, B, E, D, F[w + 7], 16, -155497632); 99 D = n(D, C, B, E, F[w + 10], 23, -1094730640); 100 E = n(E, D, C, B, F[w + 13], 4, 681279174); 101 B = n(B, E, D, C, F[w], 11, -358537222); 102 C = n(C, B, E, D, F[w + 3], 16, -722521979); 103 D = n(D, C, B, E, F[w + 6], 23, 76029189); 104 E = n(E, D, C, B, F[w + 9], 4, -640364487); 105 B = n(B, E, D, C, F[w + 12], 11, -421815835); 106 C = n(C, B, E, D, F[w + 15], 16, 530742520); 107 D = n(D, C, B, E, F[w + 2], 23, -995338651); 108 E = a(E, D, C, B, F[w], 6, -198630844); 109 B = a(B, E, D, C, F[w + 7], 10, 1126891415); 110 C = a(C, B, E, D, F[w + 14], 15, -1416354905); 111 D = a(D, C, B, E, F[w + 5], 21, -57434055); 112 E = a(E, D, C, B, F[w + 12], 6, 1700485571); 113 B = a(B, E, D, C, F[w + 3], 10, -1894986606); 114 C = a(C, B, E, D, F[w + 10], 15, -1051523); 115 D = a(D, C, B, E, F[w + 1], 21, -2054922799); 116 E = a(E, D, C, B, F[w + 8], 6, 1873313359); 117 B = a(B, E, D, C, F[w + 15], 10, -30611744); 118 C = a(C, B, E, D, F[w + 6], 15, -1560198380); 119 D = a(D, C, B, E, F[w + 13], 21, 1309151649); 120 E = a(E, D, C, B, F[w + 4], 6, -145523070); 121 B = a(B, E, D, C, F[w + 11], 10, -1120210379); 122 C = a(C, B, E, D, F[w + 2], 15, 718787259); 123 D = a(D, C, B, E, F[w + 9], 21, -343485551); 124 E = o(E, z); 125 D = o(D, y); 126 C = o(C, v); 127 B = o(B, u) 128 } 129 return [E, D, C, B] 130 } 131 function p(v) { 132 var w, u = ""; 133 for (w = 0; w < v.length * 32; w += 8) { 134 u += String.fromCharCode((v[w >> 5] >>> (w % 32)) & 255) 135 } 136 return u 137 } 138 function j(v) { 139 var w, u = []; 140 u[(v.length >> 2) - 1] = undefined; 141 for (w = 0; w < u.length; w += 1) { 142 u[w] = 0 143 } 144 for (w = 0; w < v.length * 8; w += 8) { 145 u[w >> 5] |= (v.charCodeAt(w / 8) & 255) << (w % 32) 146 } 147 return u 148 } 149 function k(u) { 150 return p(d(j(u), u.length * 8)) 151 } 152 function e(w, z) { 153 var v, y = j(w), 154 u = [], 155 x = [], 156 A; 157 u[15] = x[15] = undefined; 158 if (y.length > 16) { 159 y = d(y, w.length * 8) 160 } 161 for (v = 0; v < 16; v += 1) { 162 u[v] = y[v] ^ 909522486; 163 x[v] = y[v] ^ 1549556828 164 } 165 A = d(u.concat(j(z)), 512 + z.length * 8); 166 return p(d(x.concat(A), 512 + 128)) 167 } 168 function t(w) { 169 var z = "0123456789abcdef", 170 v = "", 171 u, y; 172 for (y = 0; y < w.length; y += 1) { 173 u = w.charCodeAt(y); 174 v += z.charAt((u >>> 4) & 15) + z.charAt(u & 15) 175 } 176 return v 177 } 178 function m(u) { 179 return unescape(encodeURIComponent(u)) 180 } 181 function q(u) { 182 return k(m(u)) 183 } 184 function l(u) { 185 return t(q(u)) 186 } 187 function h(u, v) { 188 return e(m(u), m(v)) 189 } 190 function r(u, v) { 191 return t(h(u, v)) 192 } 193 function f(v, w, u) { 194 if (!w) { 195 if (!u) { 196 return l(v) 197 } 198 return q(v) 199 } 200 if (!u) { 201 return r(w, v) 202 } 203 return h(w, v) 204 } 205 if (typeof define === "function" && define.amd) { 206 define(function() { 207 return f 208 }) 209 } else { 210 g.md5 = f 211 } 212 } (this)); 213 214 function md5(source) { 215 function safe_add(x, y) { 216 var lsw = (x & 65535) + (y & 65535), 217 msw = (x >> 16) + (y >> 16) + (lsw >> 16); 218 return msw << 16 | lsw & 65535 219 } 220 function bit_rol(num, cnt) { 221 return num << cnt | num >>> 32 - cnt 222 } 223 function md5_cmn(q, a, b, x, s, t) { 224 return safe_add(bit_rol(safe_add(safe_add(a, q), safe_add(x, t)), s), b) 225 } 226 function md5_ff(a, b, c, d, x, s, t) { 227 return md5_cmn(b & c | ~b & d, a, b, x, s, t) 228 } 229 function md5_gg(a, b, c, d, x, s, t) { 230 return md5_cmn(b & d | c & ~d, a, b, x, s, t) 231 } 232 function md5_hh(a, b, c, d, x, s, t) { 233 return md5_cmn(b ^ c ^ d, a, b, x, s, t) 234 } 235 function md5_ii(a, b, c, d, x, s, t) { 236 return md5_cmn(c ^ (b | ~d), a, b, x, s, t) 237 } 238 function binl_md5(x, len) { 239 x[len >> 5] |= 128 << len % 32; 240 x[(len + 64 >>> 9 << 4) + 14] = len; 241 var i, olda, oldb, oldc, oldd, a = 1732584193, 242 b = -271733879, 243 c = -1732584194, 244 d = 271733878; 245 for (i = 0; i < x.length; i += 16) { 246 olda = a; 247 oldb = b; 248 oldc = c; 249 oldd = d; 250 a = md5_ff(a, b, c, d, x[i], 7, -680876936); 251 d = md5_ff(d, a, b, c, x[i + 1], 12, -389564586); 252 c = md5_ff(c, d, a, b, x[i + 2], 17, 606105819); 253 b = md5_ff(b, c, d, a, x[i + 3], 22, -1044525330); 254 a = md5_ff(a, b, c, d, x[i + 4], 7, -176418897); 255 d = md5_ff(d, a, b, c, x[i + 5], 12, 1200080426); 256 c = md5_ff(c, d, a, b, x[i + 6], 17, -1473231341); 257 b = md5_ff(b, c, d, a, x[i + 7], 22, -45705983); 258 a = md5_ff(a, b, c, d, x[i + 8], 7, 1770035416); 259 d = md5_ff(d, a, b, c, x[i + 9], 12, -1958414417); 260 c = md5_ff(c, d, a, b, x[i + 10], 17, -42063); 261 b = md5_ff(b, c, d, a, x[i + 11], 22, -1990404162); 262 a = md5_ff(a, b, c, d, x[i + 12], 7, 1804603682); 263 d = md5_ff(d, a, b, c, x[i + 13], 12, -40341101); 264 c = md5_ff(c, d, a, b, x[i + 14], 17, -1502002290); 265 b = md5_ff(b, c, d, a, x[i + 15], 22, 1236535329); 266 a = md5_gg(a, b, c, d, x[i + 1], 5, -165796510); 267 d = md5_gg(d, a, b, c, x[i + 6], 9, -1069501632); 268 c = md5_gg(c, d, a, b, x[i + 11], 14, 643717713); 269 b = md5_gg(b, c, d, a, x[i], 20, -373897302); 270 a = md5_gg(a, b, c, d, x[i + 5], 5, -701558691); 271 d = md5_gg(d, a, b, c, x[i + 10], 9, 38016083); 272 c = md5_gg(c, d, a, b, x[i + 15], 14, -660478335); 273 b = md5_gg(b, c, d, a, x[i + 4], 20, -405537848); 274 a = md5_gg(a, b, c, d, x[i + 9], 5, 568446438); 275 d = md5_gg(d, a, b, c, x[i + 14], 9, -1019803690); 276 c = md5_gg(c, d, a, b, x[i + 3], 14, -187363961); 277 b = md5_gg(b, c, d, a, x[i + 8], 20, 1163531501); 278 a = md5_gg(a, b, c, d, x[i + 13], 5, -1444681467); 279 d = md5_gg(d, a, b, c, x[i + 2], 9, -51403784); 280 c = md5_gg(c, d, a, b, x[i + 7], 14, 1735328473); 281 b = md5_gg(b, c, d, a, x[i + 12], 20, -1926607734); 282 a = md5_hh(a, b, c, d, x[i + 5], 4, -378558); 283 d = md5_hh(d, a, b, c, x[i + 8], 11, -2022574463); 284 c = md5_hh(c, d, a, b, x[i + 11], 16, 1839030562); 285 b = md5_hh(b, c, d, a, x[i + 14], 23, -35309556); 286 a = md5_hh(a, b, c, d, x[i + 1], 4, -1530992060); 287 d = md5_hh(d, a, b, c, x[i + 4], 11, 1272893353); 288 c = md5_hh(c, d, a, b, x[i + 7], 16, -155497632); 289 b = md5_hh(b, c, d, a, x[i + 10], 23, -1094730640); 290 a = md5_hh(a, b, c, d, x[i + 13], 4, 681279174); 291 d = md5_hh(d, a, b, c, x[i], 11, -358537222); 292 c = md5_hh(c, d, a, b, x[i + 3], 16, -722521979); 293 b = md5_hh(b, c, d, a, x[i + 6], 23, 76029189); 294 a = md5_hh(a, b, c, d, x[i + 9], 4, -640364487); 295 d = md5_hh(d, a, b, c, x[i + 12], 11, -421815835); 296 c = md5_hh(c, d, a, b, x[i + 15], 16, 530742520); 297 b = md5_hh(b, c, d, a, x[i + 2], 23, -995338651); 298 a = md5_ii(a, b, c, d, x[i], 6, -198630844); 299 d = md5_ii(d, a, b, c, x[i + 7], 10, 1126891415); 300 c = md5_ii(c, d, a, b, x[i + 14], 15, -1416354905); 301 b = md5_ii(b, c, d, a, x[i + 5], 21, -57434055); 302 a = md5_ii(a, b, c, d, x[i + 12], 6, 1700485571); 303 d = md5_ii(d, a, b, c, x[i + 3], 10, -1894986606); 304 c = md5_ii(c, d, a, b, x[i + 10], 15, -1051523); 305 b = md5_ii(b, c, d, a, x[i + 1], 21, -2054922799); 306 a = md5_ii(a, b, c, d, x[i + 8], 6, 1873313359); 307 d = md5_ii(d, a, b, c, x[i + 15], 10, -30611744); 308 c = md5_ii(c, d, a, b, x[i + 6], 15, -1560198380); 309 b = md5_ii(b, c, d, a, x[i + 13], 21, 1309151649); 310 a = md5_ii(a, b, c, d, x[i + 4], 6, -145523070); 311 d = md5_ii(d, a, b, c, x[i + 11], 10, -1120210379); 312 c = md5_ii(c, d, a, b, x[i + 2], 15, 718787259); 313 b = md5_ii(b, c, d, a, x[i + 9], 21, -343485551); 314 a = safe_add(a, olda); 315 b = safe_add(b, oldb); 316 c = safe_add(c, oldc); 317 d = safe_add(d, oldd) 318 } 319 return [a, b, c, d] 320 } 321 function binl2rstr(input) { 322 var i, output = ""; 323 for (i = 0; i < input.length * 32; i += 8) output += String.fromCharCode(input[i >> 5] >>> i % 32 & 255); 324 return output 325 } 326 function rstr2binl(input) { 327 var i, output = []; 328 output[(input.length >> 2) - 1] = undefined; 329 for (i = 0; i < output.length; i += 1) output[i] = 0; 330 for (i = 0; i < input.length * 8; i += 8) output[i >> 5] |= (input.charCodeAt(i / 8) & 255) << i % 32; 331 return output 332 } 333 function rstr_md5(s) { 334 return binl2rstr(binl_md5(rstr2binl(s), s.length * 8)) 335 } 336 function rstr_hmac_md5(key, data) { 337 var i, bkey = rstr2binl(key), 338 ipad = [], 339 opad = [], 340 hash; 341 ipad[15] = opad[15] = undefined; 342 if (bkey.length > 16) bkey = binl_md5(bkey, key.length * 8); 343 for (i = 0; i < 16; i += 1) { 344 ipad[i] = bkey[i] ^ 909522486; 345 opad[i] = bkey[i] ^ 1549556828 346 } 347 hash = binl_md5(ipad.concat(rstr2binl(data)), 512 + data.length * 8); 348 return binl2rstr(binl_md5(opad.concat(hash), 512 + 128)) 349 } 350 function rstr2hex(input) { 351 var hex_tab = "0123456789abcdef", 352 output = "", 353 x, i; 354 for (i = 0; i < input.length; i += 1) { 355 x = input.charCodeAt(i); 356 output += hex_tab.charAt(x >>> 4 & 15) + hex_tab.charAt(x & 15) 357 } 358 return output 359 } 360 function str2rstr_utf8(input) { 361 return unescape(encodeURIComponent(input)) 362 } 363 function raw_md5(s) { 364 return rstr_md5(str2rstr_utf8(s)) 365 } 366 function hex_md5(s) { 367 return rstr2hex(raw_md5(s)) 368 } 369 function raw_hmac_md5(k, d) { 370 return rstr_hmac_md5(str2rstr_utf8(k), str2rstr_utf8(d)) 371 } 372 function hex_hmac_md5(k, d) { 373 return rstr2hex(raw_hmac_md5(k, d)) 374 } 375 return hex_md5(source) 376 } 377 378 function OOXX(m, r, d) { 379 var e = "DECODE"; 380 var r = r ? r: ""; 381 var d = d ? d: 0; 382 var q = 4; 383 r = md5(r); 384 var o = md5(r.substr(0, 16)); 385 var n = md5(r.substr(16, 16)); 386 if (q) { 387 if (e == "DECODE") { 388 var l = m.substr(0, q) 389 } 390 } else { 391 var l = "" 392 } 393 var c = o + md5(o + l); 394 var k; 395 if (e == "DECODE") { 396 m = m.substr(q); 397 k = base64_decode(m) 398 } 399 var h = new Array(256); 400 for (var g = 0; g < 256; g++) { 401 h[g] = g 402 } 403 var b = new Array(); 404 for (var g = 0; g < 256; g++) { 405 b[g] = c.charCodeAt(g % c.length) 406 } 407 for (var f = g = 0; g < 256; g++) { 408 f = (f + h[g] + b[g]) % 256; 409 tmp = h[g]; 410 h[g] = h[f]; 411 h[f] = tmp 412 } 413 var t = ""; 414 k = k.split(""); 415 for (var p = f = g = 0; g < k.length; g++) { 416 p = (p + 1) % 256; 417 f = (f + h[p]) % 256; 418 tmp = h[p]; 419 h[p] = h[f]; 420 h[f] = tmp; 421 t += chr(ord(k[g]) ^ (h[(h[p] + h[f]) % 256])) 422 } 423 if (e == "DECODE") { 424 if ((t.substr(0, 10) == 0 || t.substr(0, 10) - time() > 0) && t.substr(10, 16) == md5(t.substr(26) + n).substr(0, 16)) { 425 t = t.substr(26) 426 } else { 427 t = "" 428 } 429 } 430 return t 431 };
(2)通过Python的selenium调用Chrome的无头浏览器(说明:低版本的Python可以用Phantomjs无头浏览器,Python3.6是直接弃用了这个浏览器,只好选择Chrome)
用Chrome无头浏览器需要Chrome60以上版本,根据Chrome版本下载对应(下图对面关系)的chromedrive.exe(说是好像Chrome60以上版本自带无头浏览器功能,楼主没有成功实现,还是老老实实下载了chromedriver,下载地址:http://chromedriver.storage.googleapis.com/index.html)

1 from urllib import request
2 import re
3 from selenium import webdriver
4 import requests
5
6
7 def get_html(url):
8 req = request.Request(url)
9 return request.urlopen(req).read()
10
11
12 def get_html2(url):
13 headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ‘
14 ‘(KHTML, like Gecko)Chrome/62.0.3202.94 Safari/537.36‘}
15 return requests.get(url, headers=headers).text
16
17
18 # 用chrome headless打开网页
19 def get_html3(url):
20 chromedriver = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
21 options = webdriver.ChromeOptions()
22 options.add_argument(‘--headless‘)
23 browser = webdriver.Chrome(chromedriver, chrome_options=options)
24 browser.get(url)
25 html = browser.page_source
26 browser.quit()
27 return html
28
29
30 # 打开网页返回网页内容
31 def open_webpage(html):
32 reg = r"(http:\S+(\.jpg|\.png|\.gif))"
33 imgre = re.compile(reg)
34 imglist = re.findall(imgre, html)
35 return imglist
36
37
38 if __name__ == ‘__main__‘:
39 url = "http://jandan.net/ooxx/page-2#comments"
40 html = get_html3(url)
41 reg = r"(http:\S+(\.jpg|\.png))"
42 imglist = re.findall(reg, html)
43 for img in imglist:
44 print(img[0])
3. 下载图片 用上面提到过的urllib.request.Request方法就可以实现
4. 测试都通过了,下面是汇总的完整源码OOXX_spider.py
1 from selenium import webdriver 2 import os 3 import requests 4 import re 5 from urllib.request import urlopen 6 7 8 # 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面 9 # 图片地址 10 picpath = r‘E:\Python_Doc\Images‘ 11 # 网站地址 12 ooxx_url = "http://jandan.net/ooxx/page-{}#comments" 13 # chromedriver地址 14 chromedriver = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe" 15 16 17 # 保存路径的文件夹,没有则自己创建,不能创建目录 18 def setpath(name): 19 path = os.path.join(picpath, name) 20 if not os.path.isdir(path): 21 os.mkdir(path) 22 return path 23 24 25 # 用chrome headless打开网页 26 def gethtml(url): 27 options = webdriver.ChromeOptions() 28 options.add_argument(‘--headless‘) 29 browser = webdriver.Chrome(chromedriver, chrome_options=options) 30 browser.get(url) 31 html = browser.page_source 32 browser.quit() 33 return html 34 35 36 # 打开网页返回网页内容 37 def open_webpage(html): 38 reg = r"(http:\S+(\.jpg|\.png))" 39 imgre = re.compile(reg) 40 imglist = re.findall(imgre, html) 41 return imglist 42 43 44 # 保存照片 45 def savegirl(path, url): 46 content = urlopen(url).read() 47 with open(path + ‘/‘ + url[-11:], ‘wb‘) as code: 48 code.write(content) 49 50 51 def do_task(path, index): 52 print("正在抓取低 %s 页" % index) 53 web_url = ooxx_url.format(index) 54 htmltext = gethtml(web_url) 55 imglists = open_webpage(htmltext) 56 print("抓取成功,开始保存 %s 页图片" % index) 57 for j in range(len(imglists)): 58 savegirl(path, imglists[j][0]) 59 60 61 if __name__ == ‘__main__‘: 62 filename = "OOXX" 63 filepath = setpath(filename) 64 for i in range(1, 310): 65 do_task(filepath, i)
5. 分析:用调用chrome方法速度会比较慢,不过这个方法会是反爬虫技术越来越先进的必然选择,如何提速才是要考虑的关键
五、其他直接贴完整代码(难度:??)
1. 网址:http://pic.yesky.com yesky_spider.py
1 from urllib import request 2 import re 3 import os 4 from bs4 import BeautifulSoup 5 from urllib.error import HTTPError 6 7 8 # 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面 9 # 图片地址 10 picpath = r‘E:\Python_Doc\Images‘ 11 # 网站地址 12 mm_url = "http://pic.yesky.com/c/6_20771_%s.shtml" 13 14 15 # 保存路径的文件夹,没有则自己创建文件夹,不能创建上级文件夹 16 def setpath(name): 17 path = os.path.join(picpath, name) 18 if not os.path.isdir(path): 19 os.mkdir(path) 20 return path 21 22 23 # 获取html内容 24 def get_html(url): 25 req = request.Request(url) 26 return request.urlopen(req).read() 27 28 29 # 保存图片 30 def save_image(path, url): 31 req = request.Request(url) 32 get_img = request.urlopen(req).read() 33 with open(path + ‘/‘ + url[-14:] + ‘.jpg‘, ‘wb‘) as fp: 34 fp.write(get_img) 35 return 36 37 38 def do_task(path, url): 39 html = get_html(url) 40 p = r‘(http://pic.yesky.com/\d+/\d+.shtml)‘ 41 urllist = re.findall(p, str(html)) 42 print(urllist) 43 for ur in urllist: 44 for i in range(2, 100): 45 url1 = ur[:-6] + "_" + str(i) + ".shtml" 46 print(url1) 47 try: 48 html1 = get_html(url1) 49 data = BeautifulSoup(html1, "lxml") 50 p = r"http://dynamic-image\.yesky\.com/740x-/uploadImages/\S+\.jpg" 51 image_list = re.findall(p, str(data)) 52 print(image_list[0]) 53 save_image(path, image_list[0]) 54 except: 55 break 56 57 58 if __name__ == ‘__main__‘: 59 60 # 文件名 61 filename = "YeSky" 62 filepath = setpath(filename) 63 64 for i in range(2, 100): 65 print("正在6_20771_%s " % i) 66 url = mm_url % i 67 do_task(filepath, url)
2. 网站:http://www.7160.com 7160_spider
1 from urllib import request 2 import re 3 import os 4 5 6 # 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面 7 # 图片地址 8 picpath = r‘E:\Python_Doc\Images‘ 9 # 7160地址 10 mm_url = "http://www.7160.com/xingganmeinv/list_3_%s.html" 11 mm_url2 = "http://www.7160.com/meinv/%s/index_%s.html" 12 13 14 # 保存路径的文件夹,没有则自己创建文件夹,不能创建上级文件夹 15 def setpath(name): 16 path = os.path.join(picpath, name) 17 if not os.path.isdir(path): 18 os.mkdir(path) 19 return path 20 21 22 def get_html(url): 23 req = request.Request(url) 24 return request.urlopen(req).read() 25 26 27 def get_image(path, url): 28 req = request.Request(url) 29 get_img = request.urlopen(req).read() 30 with open(path + ‘/‘ + url[-14:] + ‘.jpg‘, ‘wb‘) as fp: 31 fp.write(get_img) 32 return 33 34 35 def do_task(path, url): 36 html = get_html(url) 37 p = r"<a href=\"/meinv/(\d+)/\"" 38 get_list = re.findall(p, str(html)) 39 for list in get_list: 40 for i in range(2, 200): 41 try: 42 url2 = mm_url2 % (list, i) 43 html2 = get_html(url2) 44 p = r"http://img\.7160\.com/uploads/allimg/\d+/\S+\.jpg" 45 image_list = re.findall(p, str(html2)) 46 # print(image_list[0]) 47 get_image(path, image_list[0]) 48 except: 49 break 50 break 51 52 53 if __name__ == ‘__main__‘: 54 # 文件名 55 filename = "7160" 56 filepath = setpath(filename) 57 58 for i in range(2, 288): 59 print("正在下载页数:List_3_%s " % i) 60 url = mm_url % i 61 do_task(filepath, url)
3. 网站:http://www.263dm.com 263dm_spider.py
1 from urllib.request import urlopen 2 import urllib.request 3 import os 4 import sys 5 import time 6 import re 7 import requests 8 9 10 # 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面 11 # 图片地址 12 picpath = r‘E:\Python_Doc\Images‘ 13 # 网站地址 14 mm_url = "http://www.263dm.com/html/ai/%s.html" 15 16 17 # 保存路径的文件夹,没有则自己创建文件夹,不能创建上级文件夹 18 def setpath(name): 19 path = os.path.join(picpath, name) 20 if not os.path.isdir(path): 21 os.mkdir(path) 22 return path 23 24 25 def getUrl(url): 26 aa = urllib.request.Request(url) 27 html = urllib.request.urlopen(aa).read() 28 p = r"(http://www\S*/\d{4}\.html)" 29 return re.findall(p, str(html)) 30 31 32 def get_image(savepath, url): 33 aa = urllib.request.Request(url) 34 html = urllib.request.urlopen(aa).read() 35 p = r"(http:\S+\.jpg)" 36 url_list = re.findall(p, str(html)) 37 for ur in url_list: 38 save_image(ur, ur, savepath) 39 40 41 def save_image(url_ref, url, path): 42 headers = {"Referer": url_ref, 43 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ‘ 44 ‘(KHTML, like Gecko)Chrome/62.0.3202.94 Safari/537.36‘} 45 content = requests.get(url, headers=headers) 46 if content.status_code == 200: 47 with open(path + "/" + str(time.time()) + ‘.jpg‘, ‘wb‘) as f: 48 for chunk in content: 49 f.write(chunk) 50 51 52 def do_task(savepath, index): 53 print("正在保存页数:%s " % index) 54 url = mm_url % i 55 get_image(savepath, url) 56 57 58 if __name__ == ‘__main__‘: 59 # 文件名 60 filename = "Adult" 61 filepath = setpath(filename) 62 63 for i in range(10705, 9424, -1): 64 do_task(filepath, i)
六、总结和补充
1. 获取网页内容有三种方式
urllib.request.Request和urllib.request.urlopen
——速度快,很容易被发现,不能获取js执行后的网页内容
requests带headers的请求方法
——速度快,可以实现伪装,不能获取js执行后的网页内容
chrome headless方法
——速度慢,等于浏览器访问,可以获取js执行后的网页内容