标签:sar命令 ada 分享 历史 监控系统 启动 自己 ctrl 包括
一、w命令linux管理员最常用的命令就是这个 w 了,该命令显示的信息还是蛮丰富的。第一行从左面开始显示的信息依次为:时间,系统运行时间,登录用户数,平均负载。
第二行开始以及下面所有的行,告诉我们的信息是,当前登录的都有哪些用户,以及他们是从哪里登录的等等。其实,在这些信息当中,我们最应该关注的应该是第一行中的 ‘load average:’ 后面的三个数值。
第一个数值表示1分钟内系统的平均负载值;
第二个数值表示5分钟内系统的平均负载值;
第三个数值表示15分钟系统的平均负载值。
这几个个值的意义是,单位时间段内CPU活动进程数。当然这个值越大就说明你的服务器压力越大。一般情况下这个值只要不超过服务器的cpu数量就没有关系,如果服务器cpu数量为8,那么这个值若小于8,就说明当前服务器没有压力,否则就要关注一下了。
那么我们怎么查看cpu核心数量呢?
# cat /proc/cpuinfo这里的processor计数从0开始,也就是说一个显示为0,二个显示为1。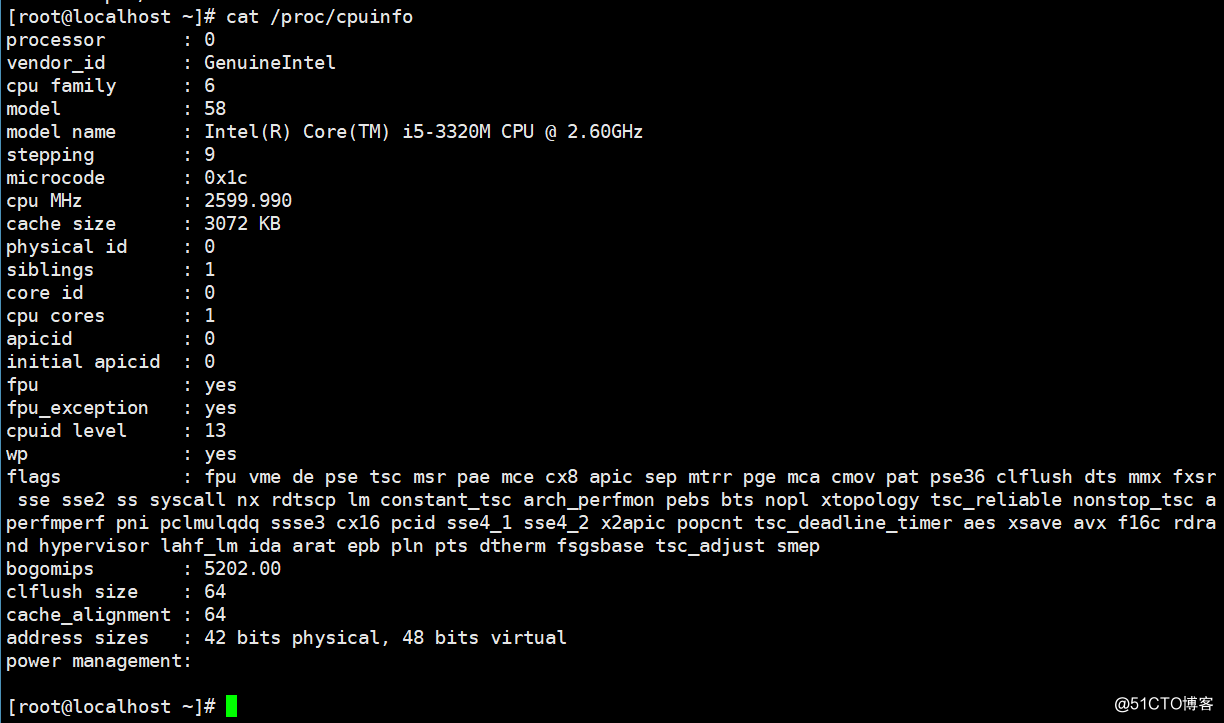
查看当前系统有几个cpu,我们可以使用这个命令:
grep -c ‘processor‘ /proc/cpuinfovmstat命令的含义为显示虚拟内存状态(“Viryual Memor Statics”),但是它可以报告关于进程、内存、I/O等系统整体运行状态。
命令选项:
-a:显示活动内页;
-f:显示启动后创建的进程总数;
-m:显示slab信息;
-n:头信息仅显示一次;
-s:以表格方式显示事件计数器和内存状态;
-d:报告磁盘状态;
-p:显示指定的硬盘分区状态;
-S:输出信息的单位。
具体用法:
# vmstat //显示当前系统状态
# vmstat 2 //每隔2秒输出一次运行状态,可以是其他任意数值,ctrl+c终止
# vmstat 2 5 //每隔2秒输出一次运行状态,输出5次后终止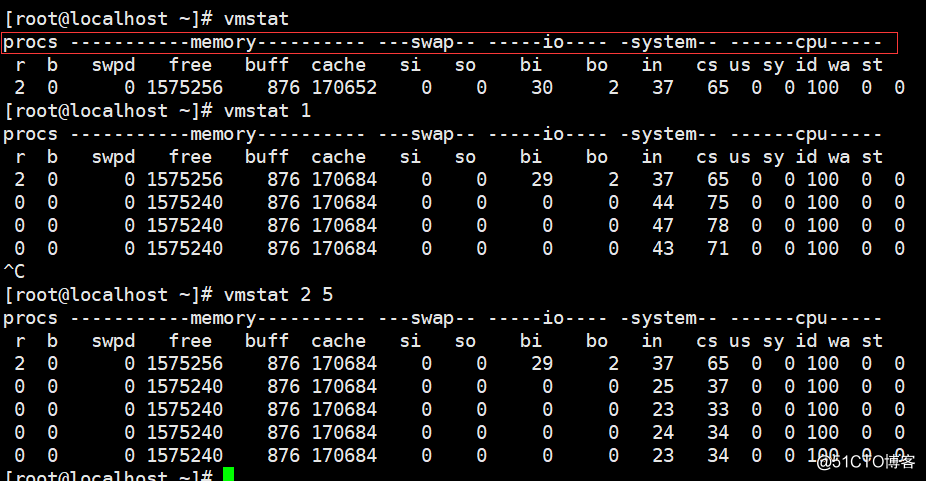
vmstat命令打印的结果共分为6部分:procs, memory, swap, io, system, cpu.。请重点关注一下r、b、si、 so、bi、bo、wa几列。
procs显示进程的相关信息:
r (run):表示运行或等待CPU时间片的进程数。说明:不要误以为等待CPU时间片意味着这个进程没有进行,实际上某一时刻一个CPU只能有一个进程,其他进程只能排着队等着,此时这些排队等待CPU资源的进程依然是运行状态。该数值如果长期大于服务器CPU的个数,则说明CPU资源不够用了。
b (block):表示等待资源的进程数,这个资源指的是I/O、内存等。举个例子:当磁盘读写非常频繁时,写数据就会非常慢,此时CPU运算很快就结束了,但进程需要把计算的结果写入磁盘,这样进程的任务才算完成,那此时这个进程只能慢慢地等待,这样这个进程就是这个b状态。该数值如果长时间大于1,则需要关注一下。
memory显示内存的相关信息:
swpd:表示切换到交换分区中的内存数量,单位为KB。
free:表示当前空闲的内存数量,单位为KB。
buff:表示(即将写入磁盘的)缓冲大小,单位为KB。
cache:表示(从磁盘中读取的)缓存大小,单位为KB。
swap显示内存的交换情况:
si:表示由交换区写入内存的数据量,单位为KB。
so:表示由内存写入交换区的数据量,单位为KB。
io显示磁盘的使用情况:
bi:表示从块设备读取数据的量(读磁盘),单位为KB。
bo:表示从块设备写入数据的量(写磁盘),单位为KB。
system显示采集间隔内发生的中断次数:
in:表示在某一时间间隔内观测到的每秒设备的中断次数。
cs:表示每秒产生的上下文切换次数。
cpu显示CPU的使用状态:
us:显示用户下花费CPU的时间百分比。
sy:显示系统花费CPU的时间百分比。
id:表示CPU处于空闲状态的时间百分比。
wa:表示I/O等待所占用CPU的时间百分比。
st:表示被偷走的CPU所占百分比(一般都为0,不用关注)
以上所介绍的各个参数中,经常会关注r列,b列,和wa列,三列代表的含义在上边说得已经很清楚。IO部分的bi以及bo也是要经常参考的对象。如果磁盘io压力很大时,这两列的数值会比较高。另外当si, so两列的数值比较高,并且在不断变化时,说明内存不够了,内存中的数据频繁交换到交换分区中,这往往对系统性能影响极大。
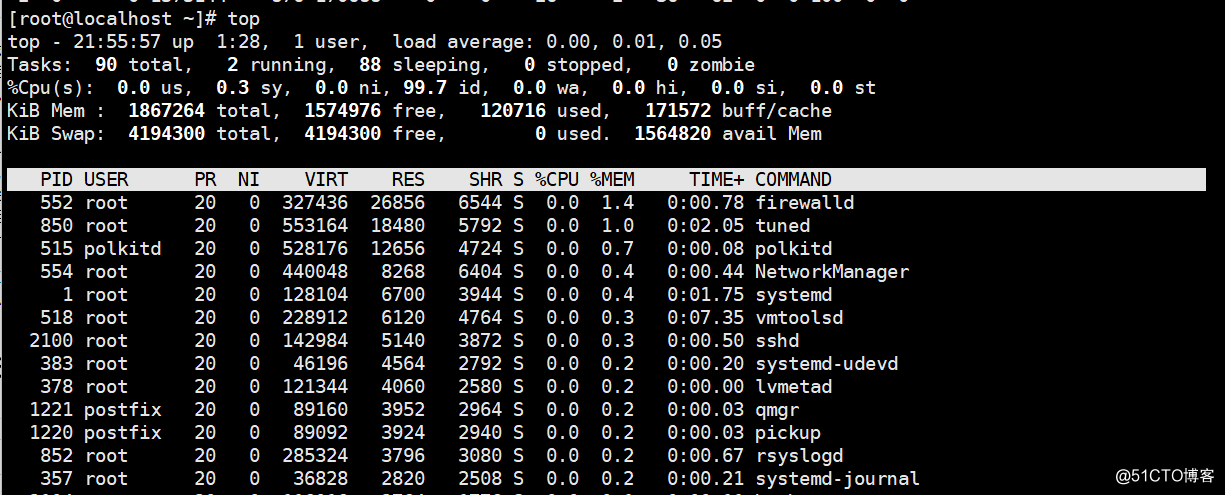
这个命令用于动态监控进程所占系统资源,每隔3秒变一次。这个命令的特点是把占用系统资源(CPU,内存,磁盘IO等)最高的进程放到最前面。top命令打印出了很多信息,包括系统负载(loadaverage)、进程数(Tasks)、cpu使用情况、内存使用情况以及交换分区使用情况。具体每个字段含义参考:http://man.linuxde.net/top
在这些状态信息中,需要关注的值有load average,tasks,%CPU,%MEM,COMMAND。
RES表示进程占用的内存数量。
shift+m表示按内存使用量排序。
shift+p表示按cpu使用量排序。
按数字1可以列出每个cpu的占用量。
top -c显示详细的进程信息。
top -bn1静态显示所有进程。
q退出。
kill+PID杀死程。
sar 命令很强大,它可以监控系统所有资源状态,比如平均负载、网卡流量、磁盘状态、内存使用等等。它不同于其他系统状态监控工具的地方在于,它可以打印历史信息,可以显示当天从零点开始到当前时刻的系统状态信息。如果你系统没有安装这个命令,请使用 yum install -y sysstat 命令安装。初次使用sar命令会报错,那是因为sar工具还没有生成相应的数据库文件(时时监控就不会了,因为不用去查询那个库文件)。它的数据库文件在 “/var/log/sa/” 目录下,默认保存一个月。sar命令很复杂,这里说下两个简单的方面,sar命令的用法可以sar -h获取帮助,或者参考:http://man.linuxde.net/sar
1)查看网卡流量
# sar -n DEV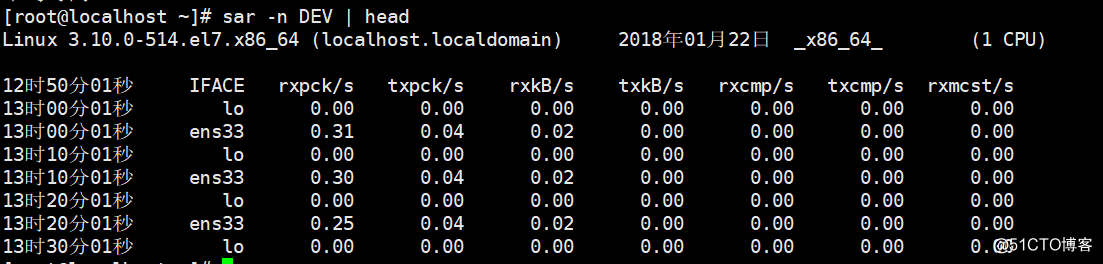
IFACE:表示设备名称.
rxpck/s:表示每秒进入收取的包的数量有多少。
txpck/s:表示每秒发送出云的包的数量有多少。
rxkB/s:表示每秒收取的数据量(单位为KB)。
txkB/S:表示每秒发送的数据量。
剩下后面几列不需要关注。如果有一天你所管理的服务器丢包非常严重,那么你就应该看一看这个网卡流量是否异常了,如果rxpck/s 那一列的数值大于4000,或者rxbyt/s那列大于5,000,000则很有可能是被攻击了,正常的服务器网卡流量不会高于这么多,除非是你自己在拷贝数据。
2)实时查看网卡流量
# sar -n DEV 2 5 //每隔2秒输出一次网卡流量状态,5次后终止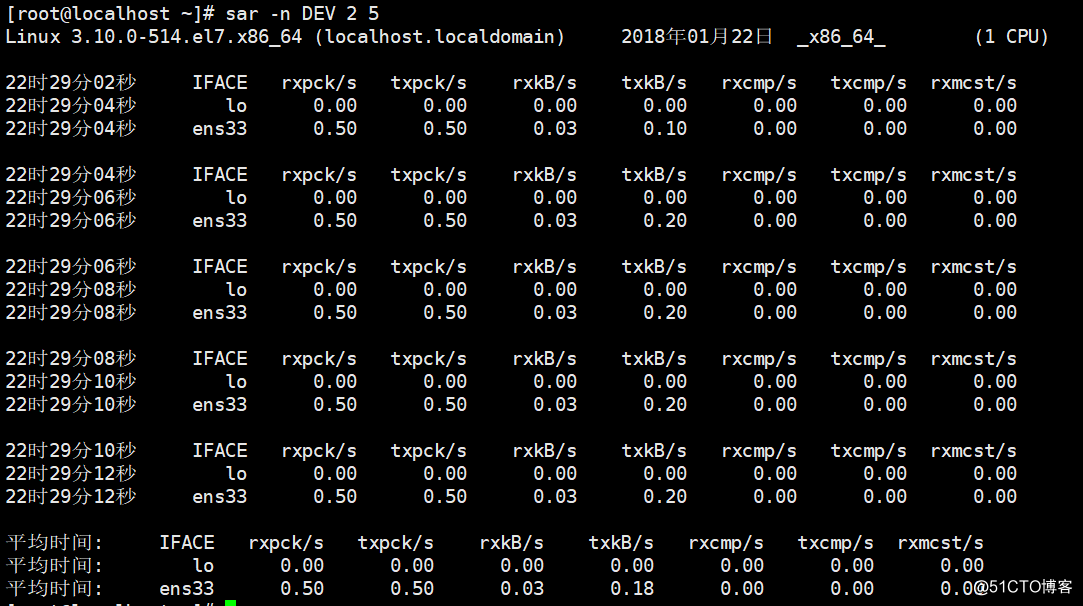
3)使用-f选项查看某一天的网卡流量历史,后面跟文件名。(在Red Hat或者CentOS发行版中,sar的库文件一定在/var/log/sa/目录下的saxx目录,xx代表日期)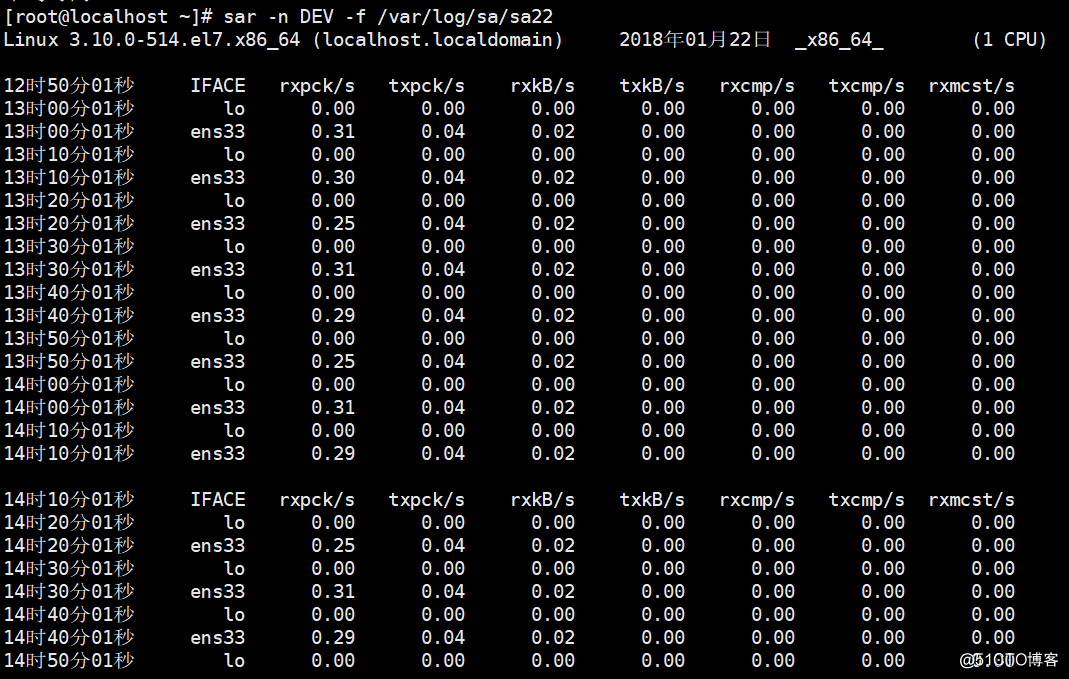
4)查看历史负载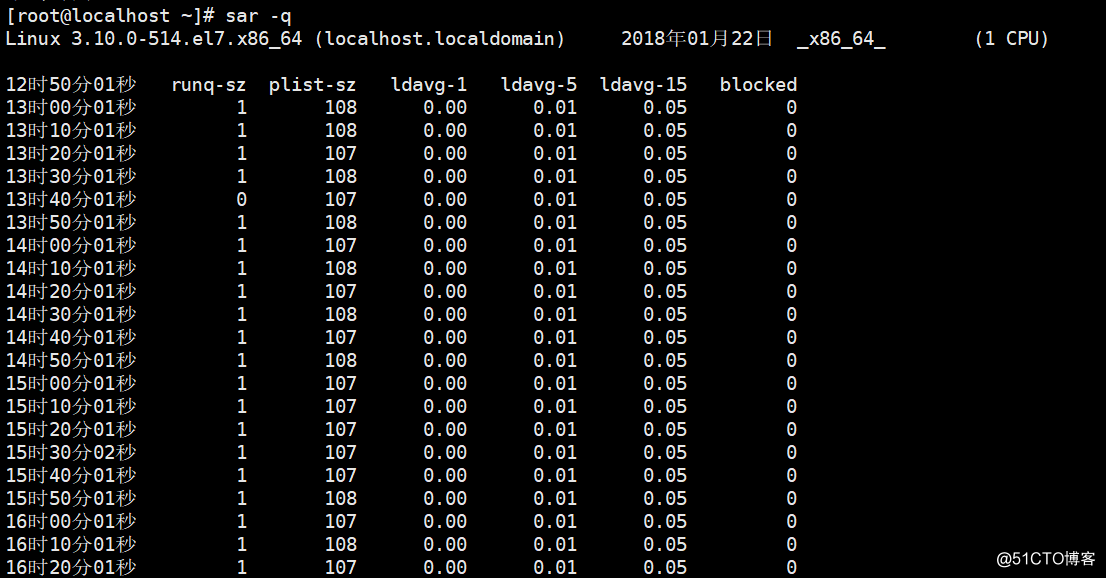
sar虽然可以查看网卡流量,但是不够直观,还有一个更好用的工具,那就是nload。
安装nload:
#yum install -y epel-release //先安装扩展源
#yum install -y nload //因为nload依赖于epel-release。输入nload: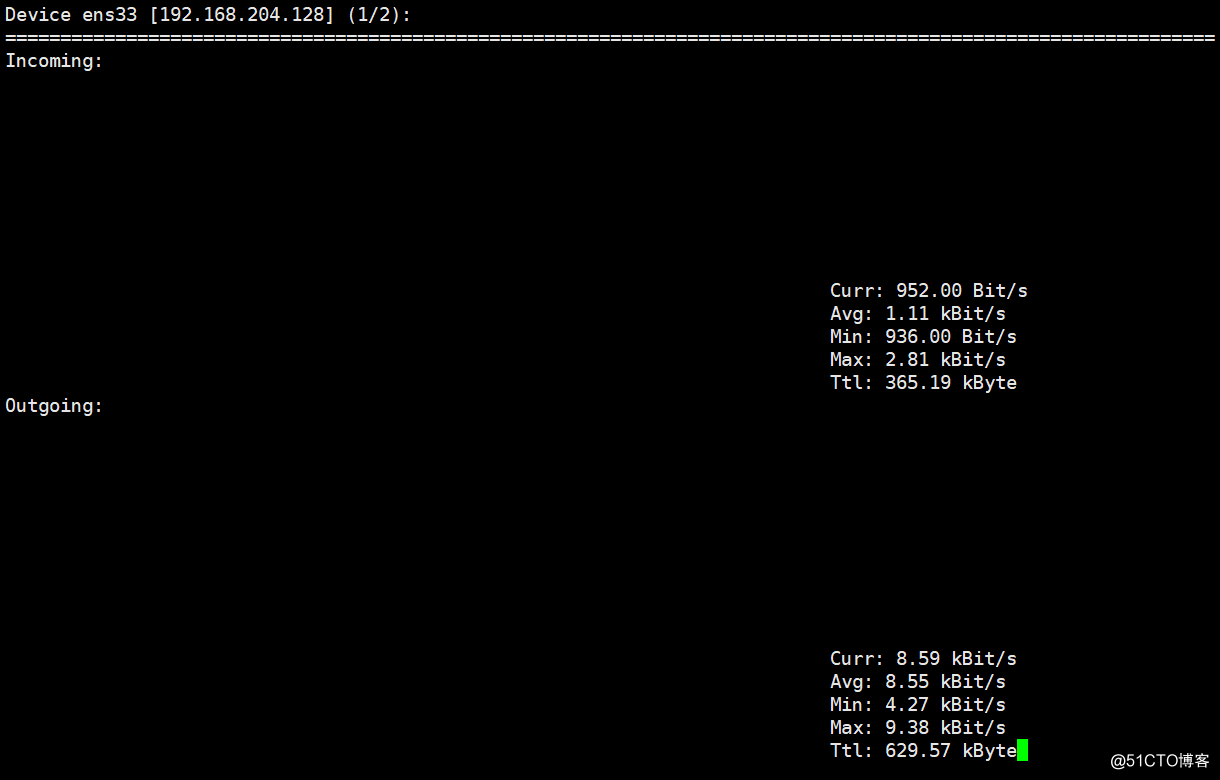
Incoming为进入网卡的流量。
Outgoing为网卡出去的流量。
主要关注Curr那行的数据,其单位也可以动态自动调整。
按q退出该界面。
Linux日常管理技巧(1):w,top,vmstat,sar命令
标签:sar命令 ada 分享 历史 监控系统 启动 自己 ctrl 包括
原文地址:http://blog.51cto.com/3069201/2064000