JAVA课程设计
基于学院网站的搜索引擎
对学院网站进行抓取、建索(需要中文分词)、排序(可选)、搜索、摘要显示。可以是GUI界面,也可以是Web界面。
一、团队介绍
201621123049 |
网络1612 |
[组长]袁德兴 |
热衷于网络安全 |
201621123047 |
网络1612 |
陈芳毅 |
有思想,有深度 ,有能力 |
201621044079 |
网络1612 |
韩烨 |
学习力强,人称韩可爱 |
201621123055 |
网络1612 |
刘兵 |
人称五社区发哥,动手能力强 |
201621123054 |
网络1612 |
张晨曦 |
掌管学校所有社团,足球一级6 |
二、项目git地址
码云地址
三、项目git提交记录截图
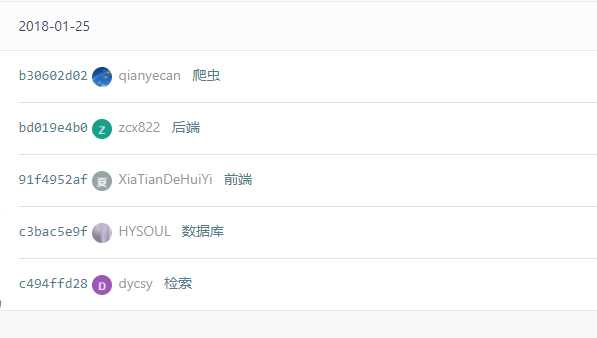
四、项目主要使用技术
Httplcient
Jsoup
多线程
数据库dao模式
IKAnanyzer
Lucene
Javascript /jQuery
Bootstrap
Web
五、项目其余特点
容错处理完善
界面美观
有配置文件
数据量大的时候查询速度依旧快
六、项目功能架构图与主要功能流程图
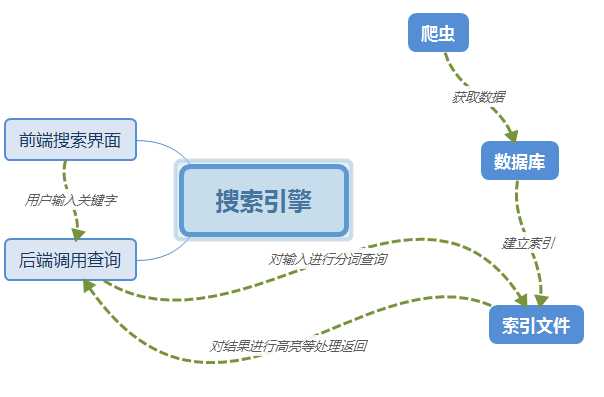
七、项目运行截图
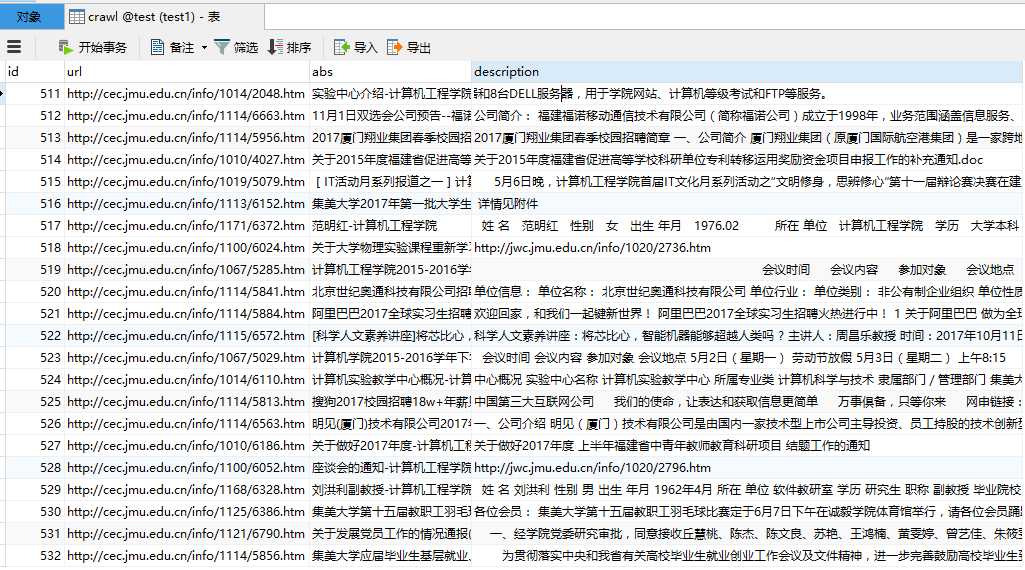
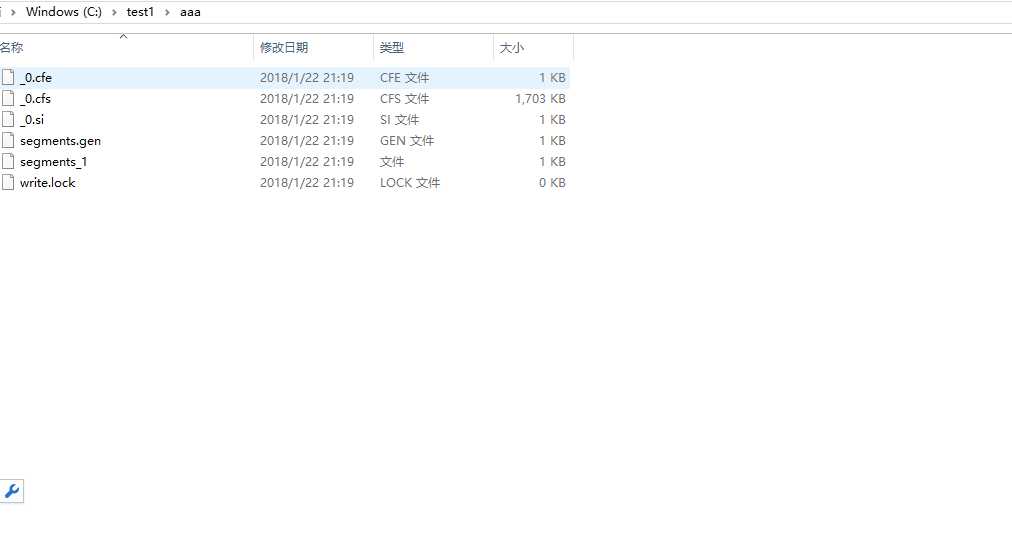
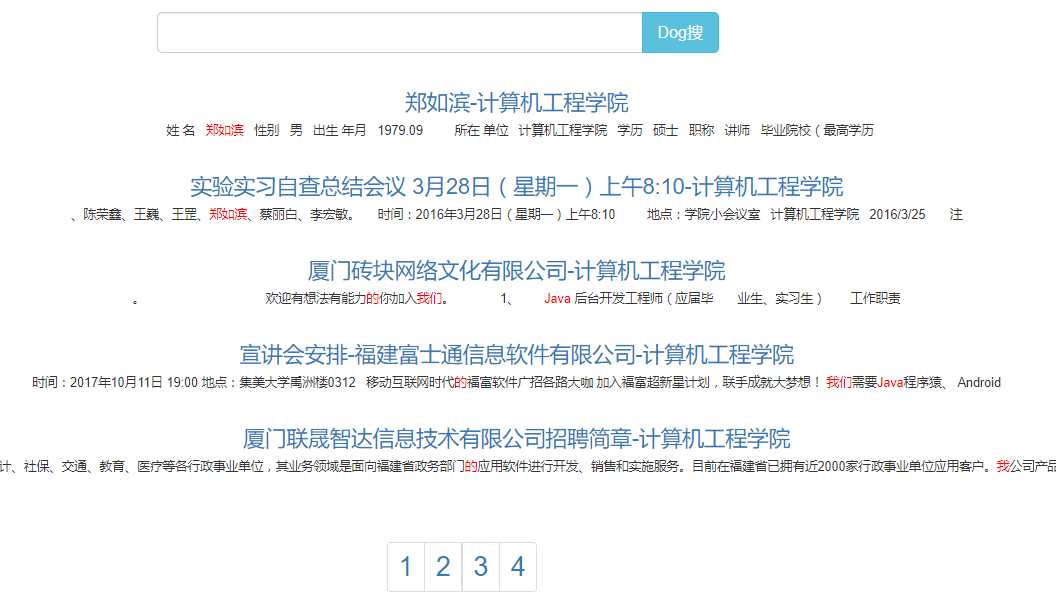
八、项目关键代码
try {
Document doc=Jsoup.connect("http://cec.jmu.edu.cn/").get();
Elements links = doc.select(".menu0_0_");
for (Element link : links) {
lis1.add(oriurl+link.attr("href"));
}
} catch (IOException e1) {
e1.printStackTrace();
}
try {
CloseableHttpResponse response = httpClient.execute(httpget, context);
try {
HttpEntity entity = response.getEntity();
Document doc=Jsoup.parse(EntityUtils.toString(entity,"utf8"));
Elements links=doc.select(".c124907");
for (Element link : links) {
lis1.add(url +link.attr("href"));
}
String pattern ="\\?a2t=([0-9]{1,})&a2p=[0-9]{1,}&a2c=10&urltype=tree.TreeTempUrl&wbtreeid=([0-9]{1,})";
Elements links1=doc.select("a[href]");
for (Element link1 : links1) {
String line=link1.attr("href");
Pattern r = Pattern.compile(pattern);
Matcher m = r.matcher(line);
int i=0;
if (m.find( )) {
// System.out.println("Found value: " + m.group(0) );
int j=Integer.parseInt(m.group(1));
if(j>7){
for(int k=1;k<j+1;k++){
lis.add("?a2t="+String.valueOf(j)+"&a2p="+String.valueOf(k)+"&a2c=10&urltype=tree.TreeTempUrl&wbtreeid="+m.group(2));
}
}
else{
lis.add(m.group(0));
}
CloseableHttpResponse response = httpClient.execute(httpget, context);
try {
HttpEntity entity = response.getEntity();
Document doc=Jsoup.parse(EntityUtils.toString(entity,"utf8"));
Elements links=doc.select(".c124907");
for (Element link : links) {
lis.add(link.attr("href"));
}
try {
HttpEntity entity = response.getEntity();
Document doc=Jsoup.parse(EntityUtils.toString(entity,"utf8"));
String title = doc.select(".contentstyle124904").text();
Crawl crawl=new Crawl(httpget.getURI().toString(),doc.title().toString(),title);
CrawlDaoImpl test=new CrawlDaoImpl();
try {
if(bool){
test.add(crawl);
System.out.println(httpget.toString()+"添加成功");
}
else{
System.out.println("添加失败");
jdbc.url=jdbc:mysql://localhost:3306/test
jdbc.username=root
jdbc.password=root
jdbc.driver=com.mysql.jdbc.Driver
@Override
public Crawl findById(int id) throws SQLException {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
Crawl p = null;
String sql = "select url,abs,description from crawl where id=?";
try{
conn = DBUtils.getConnection();
ps = conn.prepareStatement(sql);
ps.setInt(1, id);
rs = ps.executeQuery();
if(rs.next()){
p = new Crawl();
p.setId(id);
p.setUrl(rs.getString(1));
p.setAbs(rs.getString(2));
p.setDescription(rs.getString(3));
}
}catch(SQLException e){
e.printStackTrace();
throw new SQLException("*");
}finally{
DBUtils.close(rs, ps, conn);
}
return p;
}
public class IndexManager {
@Test
public void createIndex() throws Exception {
// 采集数据
CrawlDao dao = new CrawlDaoImpl();
List<Crawl> list = dao.findAll();
// 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList();
Document document;
for (Crawl crawl : list) {
document = new Document();
// store:如果是yes,则说明存储到文档域中
Field id = new IntField("id", crawl.getId(), Store.YES);
Field url = new StoredField("url", crawl.getUrl());
Field abs = new StoredField("abs", crawl.getAbs());
Field description = new TextField("description",
crawl.getDescription(), Store.YES);
document.add(id);
document.add(url);
document.add(abs);
document.add(description);
docList.add(document);
}
// 创建分词器,标准分词器
// Analyzer analyzer = new StandardAnalyzer();
// 使用ikanalyzer
Analyzer analyzer = new IKAnalyzer();
// 创建IndexWriter
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_4_10_3,
analyzer);
// 指定索引库的地址
File indexFile = new File("C:\\test1\\aaa\\");
Directory directory = FSDirectory.open(indexFile);
IndexWriter writer = new IndexWriter(directory, cfg);
// 通过IndexWriter对象将Document写入到索引库中
for (Document doc : docList) {
writer.addDocument(doc);
}
writer.close();
}
public class IndexSearch {
List<Crawl> lis1=new ArrayList();
public List doSearch(Query query) throws InvalidTokenOffsetsException {
// 创建IndexSearcher
// 指定索引库的地址
try {
File indexFile = new File("C:\\test1\\aaa\\");
Directory directory = FSDirectory.open(indexFile);
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = searcher.search(query, 20);
// 根据查询条件匹配出的记录总数
int count = topDocs.totalHits;
// ScoreDoc[] scoreDocs = topDocs.scoreDocs;
String filed="description";
// TopDocs top=searcher.search(query, 100);
QueryScorer score=new QueryScorer(query,filed);//传入评分
SimpleHTMLFormatter fors=new SimpleHTMLFormatter("<span style=\"color:red;\">", "</span>");//定制高亮标签
Highlighter highlighter=new Highlighter(fors,score);//高亮分析器
// highlighter.setMaxDocCharsToAnalyze(10);//设置高亮处理的字符个数
for(ScoreDoc sd:topDocs.scoreDocs){
Document doc=searcher.doc(sd.doc);
String description=doc.get(filed);
//Lucene中分词的所有信息我们都可以从TokenStream流中获取.
TokenStream token=TokenSources.getAnyTokenStream(searcher.getIndexReader(), sd.doc, "description", new IKAnalyzer(true));//获取tokenstream
Fragmenter fragment=new SimpleSpanFragmenter(score); //根据这个评分新建一个对象
highlighter.setTextFragmenter(fragment); //必须选取最合适的
highlighter.setTextFragmenter(new SimpleFragmenter());//设置每次返回的字符数
String str=highlighter.getBestFragment(token, description);//获取高亮的片段,可以对其数量进行限制
Crawl crawl = new Crawl();
crawl.setDescription(str);
crawl.setAbs(doc.get("abs"));
crawl.setUrl(doc.get("url"));
lis1.add(crawl);
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
return lis1;
}
<div id="test"> <img src="./img/logo.png" height="300" width="250"/></div>
<form action="./query2.jsp" method="GET">
<div class="search-wrapper">
<div class="input-holder">
<input type="text" class="search-input" placeholder="" name="name"/>
<button class="search-icon" onclick="searchToggle(this, event);"><span></span></button>
</div>
<span class="close" onclick="searchToggle(this, event);"></span>
<div class="result-container">
</div>
</div>
</form>
<script src="js/jquery-1.11.0.min.js" type="text/javascript"></script>
<script type="text/javascript">
function searchToggle(obj, evt){
var container = $(obj).closest('.search-wrapper');
if(!container.hasClass('active')){
container.addClass('active');
evt.preventDefault();
}
else if(container.hasClass('active') && $(obj).closest('.input-holder').length == 0){
container.removeClass('active');
container.find('.search-input').val('');
container.find('.result-container').fadeOut(100, function(){$(this).empty();});
}
}
function submitFn(obj, evt){
value = $(obj).find('.search-input').val().trim();
_html = "Yup yup! Your search text sounds like this: ";
if(!value.length){
_html = "Yup yup! Add some text friend :D";
}
else{
_html += "<b>" + value + "</b>";
}
$(obj).find('.result-container').html('<span>' + _html + '</span>');
$(obj).find('.result-container').fadeIn(100);
evt.preventDefault();
}
</script>
<script type="text/javascript">
$(function(){
var Count = "<%=i %>";//记录条数
var tmp = "<%=test %>";
var PageSize=5;//设置每页示数目
var PageCount=Math.ceil(Count/PageSize);//计算总页数
var currentPage =1;//当前页,默认为1。
//造个简单的分页按钮
for(var i=1;i<=PageCount;i++){
if(PageCount==1){
}//如果页数为1的话,那么我们就是不分页
else{
var pageN='<li style=\"font-size:30px\"><a href="?name='+tmp+'&a='+i+'">'+i+'</a></li>';
$('.pagination').append(pageN);
}
}
//显示默认页(第一页)
});
</script>
<%
String d =request.getParameter("a");
//out.print(d+"<br>");
int b=0;
int k=0;
if(i!=0&&d==null){
for(Crawl crawl: lis){
if(5>k&&k>=0){
out.print("<h3><p class=\"text-center\"><a href=\""+crawl.getUrl()+"\">"+crawl.getAbs()+"</a></p></h3>");
out.print("<p class=\"text-center\">"+crawl.getDescription()+"<br>");
out.print("<br>");
}
k=k+1;
}
}
else{
if(d!=null){
int c=Integer.valueOf(d);
//out.print(c);
for(Crawl crawl: lis){
if(c*5>b&&b>=(c-1)*5){
if(crawl.getDescription()==null){
out.print("");
}
else{
out.print("<h3><p class=\"text-center\"><a href=\""+crawl.getUrl()+"\">"+crawl.getAbs()+"</a></p></h3>");
out.print("<p class=\"text-center\">"+crawl.getDescription()+"<br>");
out.print("<br>");
}
}
b=b+1;
}
}
}
%>
尚待改进或者新的想法
变量的命名不太规范
可以尝试着去做一个只有修改部分参数,就可以去爬取别的网站的搜索引擎
团队成员任务分配
袁德兴 |
利用Lucene和IKanalyzer进行检索,部分前后端内容与模块衔接 |
陈芳毅 |
采用httpclient和jsoup,进行爬取和解析,部分数据库内容 |
韩烨 |
采用数据库的dao模式将jsoup解析后的内容进行存储,部分前端和logo的设计 |
刘兵 |
采用bootstrap和jsp等进行前端界面的设计和后端代码实现 |
张晨曦 |
采用jquery和jsp等进行前端界面的设计和后端代码的实现 |