一、概述:
1.1 AIS和OpenAIS简介
AIS应用接口规范,是用来定义应用程序接口(API)的开放性规范的集合,这些应用程序作为中间件为应用服务提供一种开放、高移植性的程序接口。是在实现高可用应用过程中是亟需的。服务可用性论坛(SA
Forum)是一个开放性论坛,它开发并发布这些免费规范。使用AIS规范的应用程序接口(API),可以减少应用程序的复杂性和缩短应用程序的开发时间,这些规范的主要目的就是为了提高中间组件可移植性和应用程序的高可用性。
OpenAIS是基于SA Forum
标准的集群框架的应用程序接口规范。OpenAIS提供一种集群模式,这个模式包括集群框架,集群成员管理,通信方式,集群监测等,能够为集群软件或工具提供满足
AIS标准的集群接口,但是它没有集群资源管理功能,不能独立形成一个集群。
1.2 corosync简介
Corosync是OpenAIS发展到Wilson版本后衍生出来的开放性集群引擎工程,corosync最初只是用来演示OpenAIS集群框架接口规范的一个应用,可以说corosync是OpenAIS的一部分,但后面的发展明显超越了官方最初的设想,越来越多的厂商尝试使用corosync作为集群解决方案。如RedHat的RHCS集群套件就是基于corosync实现。
corosync只提供了message layer,而没有直接提供CRM,一般使用Pacemaker进行资源管理。
1.3 pacemaker简介
pacemaker就是Heartbeat
到了V3版本后拆分出来的资源管理器(CRM),用来管理整个HA的控制中心,要想使用pacemaker配置的话需要安装一个pacemaker的接口,它的这个程序的接口叫crmshell,它在新版本的
pacemaker已经被独立出来了,不再是pacemaker的组成部分。
(1)pacemaker 内部结构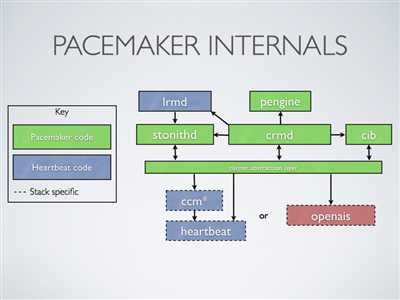
(2)群集组件说明:
stonithd:心跳系统。
lrmd:本地资源管理守护进程。它提供了一个通用的接口支持的资源类型。直接调用资源代理(脚本)。
pengine:政策引擎。根据当前状态和配置集群计算的下一个状态。产生一个过渡图,包含行动和依赖关系的列表。
CIB:群集信息库。包含所有群集选项,节点,资源,他们彼此之间的关系和现状的定义。同步更新到所有群集节点。
CRMD:集群资源管理守护进程。主要是消息代理的PEngine和LRM,还选举一个领导者(DC)统筹活动(包括启动/停止资源)的集群。
OpenAIS:OpenAIS的消息和成员层。
Heartbeat:心跳消息层,OpenAIS的一种替代。
CCM:共识群集成员,心跳成员层。
功能概述
CIB使用XML表示集群的集群中的所有资源的配置和当前状态。CIB的内容会被自动在整个集群中同步,使用PEngine计算集群的理想状态,生成指令列表,然后输送到DC(指定协调员)。Pacemaker
集群中所有节点选举的DC节点作为主决策节点。如果当选DC节点宕机,它会在所有的节点上,
迅速建立一个新的DC。DC将PEngine生成的策略,传递给其他节点上的LRMd(本地资源管理守护程序)或CRMD通过集群消息传递基础结构。当集群中有节点宕机,PEngine重新计算的理想策略。在某些情况下,可能有必要关闭节点,以保护共享数据或完整的资源回收。为此,Pacemaker配备了stonithd设备。STONITH可以将其它节点“爆头”,通常是实现与远程电源开关。Pacemaker会将STONITH设备,配置为资源保存在CIB中,使他们可以更容易地监测资源失败或宕机。
(3)CRM中的几个基本概念:
资源粘性:资源粘性表示资源是否倾向于留在当前节点,如果为正整数,表示倾向,负数表示移离,-inf表示正无穷,inf表示正无穷。
资源黏性值范围及其作用:
0:默认选项。资源放置在系统中的最适合位置。这意味着当负载能力“较好”或较差的节点变得可用时才转移资源。
此选项的作用基本等同于自动故障回复,只是资源可能会转移到非之前活动的节点上;
大于0:资源更愿意留在当前位置,但是如果有更合适的节点可用时会移动。值越高表示资源越愿意留在当前位置;
小于0:资源更愿意移离当前位置。绝对值越高表示资源越愿意离开当前位置;
INFINITY:如果不是因节点不适合运行资源(节点关机、节点待机、达到migration-threshold 或配置更改)而强制资源转移,
资源总是留在当前位置。此选项的作用几乎等同于完全禁用自动故障回复;
-INFINITY:资源总是移离当前位置;
资源类型:
primitive(native):基本资源,原始资源
group:资源组
clone:克隆资源(可同时运行在多个节点上),要先定义为primitive后才能进行clone。主要包含STONITH和集群文件系统(cluster filesystem)
master/slave:主从资源,如drdb(下文详细讲解)
RA类型:
Lsb:linux表中库,一般位于/etc/rc.d/init.d/目录下的支持start|stop|status等参数的服务脚本都是lsb
ocf:Open cluster Framework,开放集群架构
heartbeat:heartbaet V1版本
stonith:专为配置stonith设备而用
(4)pacemaker 支持集群
基于OpenAIS的集群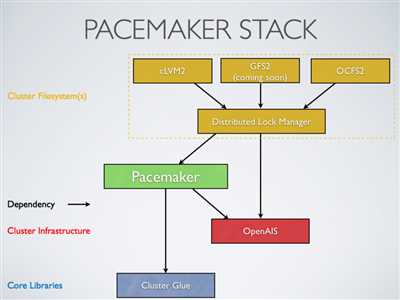
基于心跳信息的传统集群架构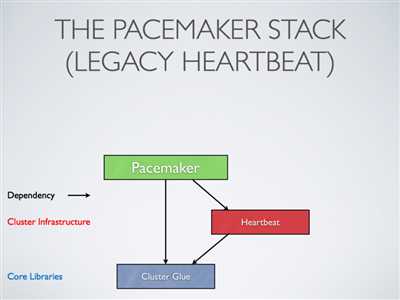
1.4Corosync+Pacemaker 支持集群
可实现多种集群模型,包?括? Active/Active、 Active/Passive、 N+1、 N+M、N-to-1、 N-to-N and Split site
主从架构集群:
许多高可用性的情况下,使用Pacemaker和DRBD的双节点主/从集群是一个符合成本效益的解决方案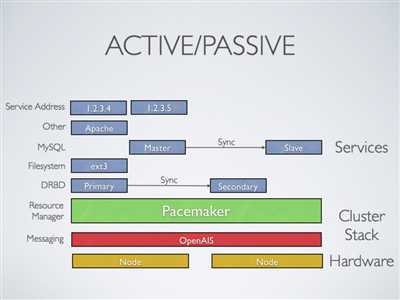
多节点备份集群:
支持多少节点,Pacemaker可以显着降低硬件成本通过允许几个主/从群集要结合和共享一个公用备份节点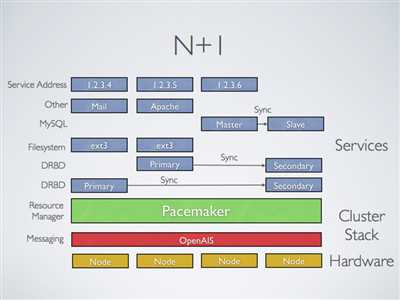
共享存储集群(多个节点多个服务):
有共享存储时,每个节点可能被用于故障转移,Pacemaker甚至可以运行多个服务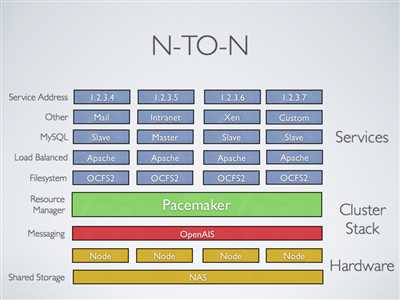
站点集群:
Pacemaker 1.2 将包括增强简化设立分站点集群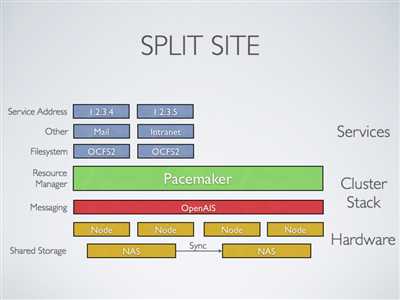
二、集群简介
引自suse官方关于corosync的高可用集群的框架图: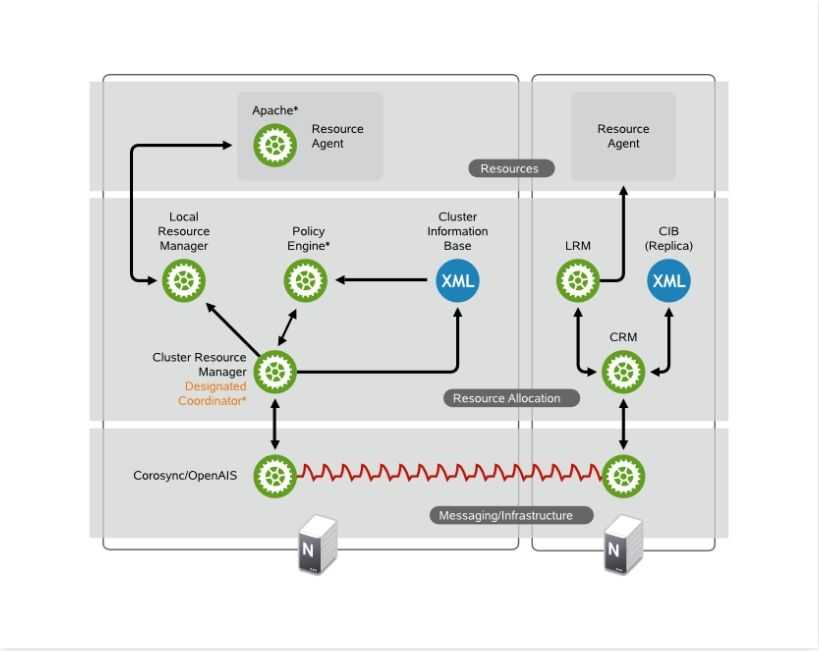
由此图,我们可以看到,SUSE官方将集群的Architecture Layers分成四层。
- 第一层:Messaging/Infrastructure Layer提供了HeartBeat节点间传递心跳信息,即为心跳层。
- 第二层:Membership Layer层为集群事务决策层,决定了哪些节点作为集群节点,并传递给集群内所有节点,如果集群中成员拥有的法定票数不大于半数,该怎么作出决策等,通俗点讲,就是投票系统,同时,还提供了构建成员关系的视图。
- 第三层:Resource Allocation Layer为资源分配层,包含了CRM,CIB;CRM作为资源分配层的核心组件,包括了Local Resource Manager、Transition Engine、Policy Engine三大组件,这三大组件都是在CRM的基础之上得以实现的,同时,每个节点的CRM还维持本节点的CIB。在CRM中选出一个节点作为DC(Designated Coordinator),DC负责维持主CIB,所以所有CIB的修改都由DC来实现,而后DC同步给其他节点,一个集群只有一个DC。CIB是一个在内存中xml格式书写的保存着集群配置各条目的配置信息(集群状态,各节点,各资源,约束关系),可以使用gui修改,也可以使用CRM_sh命令行修改。Transition Engine和Policy Engine,这两个组件只有DC拥有,PE是当集群状态改变时,根据配置文件中的约束信息,节点粘性计算要转移到的节点一应状态信息,并写入CIB,TE根据PE作出的指示进行转移资源等操作。DC将改变的状态信息传至各CRM,各节点的CRM将要作出的改变传给LRM作出相应的更改,LRM有start|stop|monitor三种状态信息,在接受CRM指令作出更改后,将状态信息传回CRM。
- 第四层:Resources Layer层,即资源代理层,负责根据LRM传来的指令,找到对应的执行脚本执行,资源代理层有LSB格式,OCF格式的脚本,OCF相对于LSB,除了能接收更多参数外,还能提供监控功能。
三、环境介绍
3.1网络拓扑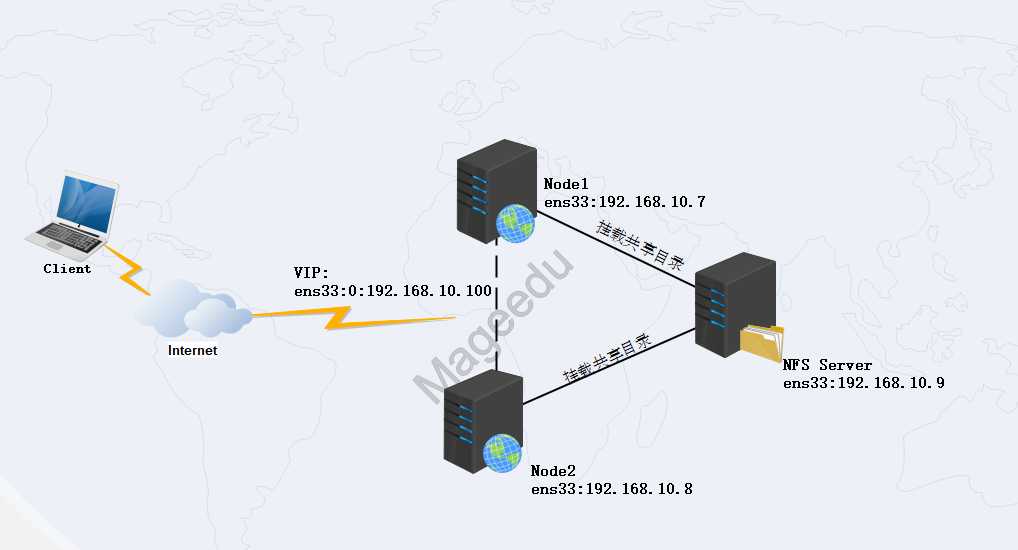
3.2环境说明
3.3 集群配置前提
(1)节点间时间必须同步,使用ntp协议实现;
(2)节点间需要通过主机名互相通信,必须解析主机至IP地址
(a)建议名称解析功能使用hosts文件来实现
(b)通信中使用的名字与节点名字必须保持一致: "uname -n"命令,或“hostname"展示出的名字保持一致
(3)考虑仲裁设备是否会用到
3.4 前期环境准备:
(1) 各服务器关闭防火墙及清空防火墙策略
(2) 各服务器禁用SELinux,然后进行重启操作
(3) 各服务器设置hosts文件来实现解析
[root@Node1 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.7 Node1.contoso.com Node1 192.168.10.8 Node2.contoso.com Node2 192.168.10.9 Node3.contoso.com Node3 192.168.10.100 www.contoso.com
(4)Node1与Node2节点设置时间同步计划任务
[root@Node1 ~]# crontab -e //编辑crontab文件 [root@Node1 ~]# crontab -l //查看任务计划 #synchronization time //每隔五分钟进行同步一次 */5 * * * * /usr/sbin/ntpdate 192.168.10.9 > /dev/null 2>&1
(5)时间同步
[root@Node3 ~]# ansible all -m command -a ‘ntpdate 192.168.10.9‘ 192.168.10.7 | SUCCESS | rc=0 >> 31 Jan 22:25:31 ntpdate[1739]: adjust time server 192.168.10.9 offset 0.267077 sec 192.168.10.8 | SUCCESS | rc=0 >> 31 Jan 22:25:31 ntpdate[1748]: adjust time server 192.168.10.9 offset -0.162604 sec
四、集群软件部署与配置
4.1安装pacemaker与corosync
[root@Node1 ~]# yum -y install pacemaker Loaded plugins: fastestmirror, langpacks CentOS7.4 | 3.6 kB 00:00:00 (1/2): CentOS7.4/group_gz | 156 kB 00:00:00 (2/2): CentOS7.4/primary_db | 3.1 MB 00:00:01 Determining fastest mirrors Resolving Dependencies --> Running transaction check .........................省略部分......................... Installed: pacemaker.x86_64 0:1.1.16-12.el7 Dependency Installed: ****安装所有依赖包***** cifs-utils.x86_64 0:6.2-10.el7 corosync.x86_64 0:2.4.0-9.el7 corosynclib.x86_64 0:2.4.0-9.el7 libqb.x86_64 0:1.0.1-5.el7 pacemaker-cli.x86_64 0:1.1.16-12.el7 pacemaker-cluster-libs.x86_64 0:1.1.16-12.el7 pacemaker-libs.x86_64 0:1.1.16-12.el7 perl-TimeDate.noarch 1:2.30-2.el7 resource-agents.x86_64 0:3.9.5-105.el7 Complete!
4.2配置文件修改
[root@Node1 ~]# cd /etc/corosync/
[root@Node1 corosync]# cp corosync.conf.example corosync.conf //将模板复制成一份,生成corosync.conf配置文件
[root@Node1 corosync]# grep -v "[[:space:]]*#" /etc/corosync/corosync.conf |grep -v "^[[:space:]]*$" //修改过的配置文件如下
totem { //节点间的通信协议,主要定义通信方式,通信协议版本,加密算法
version: 2 //协议版本
crypto_cipher: aes256 //加密密码类型
crypto_hash: sha1 //加密为sha1
interface { //定义集群心跳信息及传递的接口中,可以有多组
ringnumber: 0 //环数量,如果一个主机有多块网卡,避免心跳信息环发送
bindnetaddr: 192.168.10.0 //绑定的网段(本机网段为192.168.10.0/24)
mcastaddr: 239.255.10.9 //组播地址
mcastport: 5405 //组播端口
ttl: 1 //数据包的ttl值,由于不跨三层设备,这里用默认的1
}
}
logging { //跟日志相关配置
fileline: off //是否记录fileline
to_stderr: no //表示是否需要发送到错误输出
to_logfile: yes //是否记录在日志文件中
logfile: /var/log/cluster/corosync.log //日志文件目录
to_syslog: no //是否将日志发往系统日志
debug: off //是否输出debug日志
timestamp: on //是否打开时间戳
logger_subsys {
subsys: QUORUM
debug: off
}
}
quorum { //投票系统
provider: corosync_votequorum //支持哪种投票方式
expected_votes:2 //总投票数
two_nodes: 1 //是否为2节点集群(两节点特殊}
}
nodelist { //节点列表
node {
ring0_addr: Node1.contoso.com //节点名称:主机名或IP
nodeid: 1 //节点编号
}
node {
ring0_addr: Node2.contoso.com
nodeid: 2
}
}
4.3生成生成密匙文件拷贝至另一节点
[root@Node1 corosync]# corosync-keygen //生成密钥文件 Corosync Cluster Engine Authentication key generator. Gathering 1024 bits for key from /dev/random. Press keys on your keyboard to generate entropy. Press keys on your keyboard to generate entropy (bits = 920). Press keys on your keyboard to generate entropy (bits = 1000). Writing corosync key to /etc/corosync/authkey. [root@Node1 corosync]# ll authkey //查看文件权限为400 -r-------- 1 root root 128 Jan 31 16:21 authkey [root@Node1 corosync]# scp -p authkey corosync.conf node2:/etc/corosync/ //将两个文件复制到另外一个节点 root@node2‘s password: authkey 100% 128 90.7KB/s 00:00 corosync.conf 100% 3090 4.0MB/s 00:00
4.4 各节点启动服务,查看状态是否正常
[root@Node1 corosync]# systemctl start corosync.service //启动corosync服务 [root@Node1 corosync]# systemctl start pacemaker.service //启动pacemaker服务 [root@Node1 corosync]# ss -unl //查看UDP端口是否处于监听状态 State Recv-Q Send-Q Local Address:Port Peer Address:Port UNCONN 0 0 *:5353 *:* UNCONN 0 0 192.168.10.7:5404 *:* UNCONN 0 0 239.255.10.9:5405 *:* UNCONN 0 0 192.168.10.7:5405 *:* UNCONN 0 0 192.168.122.1:53 *:* UNCONN 0 0 127.0.0.1:323 *:* UNCONN 0 0 *%virbr0:67 *:* UNCONN 0 0 *:49753 *:* UNCONN 0 0 ::1:323 :::*
4.5 检查集群启动状态
(1)查看corosync引擎是否正常启动
[root@Node1 ~]# grep -e "Corosync Cluster Engine" -e "configuration file" /var/log/cluster/corosync.log Feb 01 08:53:49 [41390] Node1.contoso.com cib: info: cib_file_write_with_digest: Reading cluster configuration file /var/lib/pacemaker/cib/cib.CIKPy4 (digest: /var/lib/pacemaker/cib/cib.UhBVLu) Feb 01 08:53:49 [41390] Node1.contoso.com cib: info: cib_file_write_with_digest: Reading cluster configuration file /var/lib/pacemaker/cib/cib.ThQ0B3 (digest: /var/lib/pacemaker/cib/cib.NhKZPt) [root@Node1 ~]#
(2)查看初始化成员节点通知是否正常发出
[root@Node2 ~]# grep TOTEM /var/log/cluster/corosync.log Feb 01 08:53:05 [49238] Node2.contoso.com corosync notice [TOTEM ] Initializing transport (UDP/IP Multicast). Feb 01 08:53:05 [49238] Node2.contoso.com corosync notice [TOTEM ] Initializing transmit/receive security (NSS) crypto: aes256 hash: sha1 Feb 01 08:53:05 [49238] Node2.contoso.com corosync notice [TOTEM ] The network interface [192.168.10.8] is now up. Feb 01 08:53:05 [49238] Node2.contoso.com corosync notice [TOTEM ] A new membership (192.168.10.8:4) was formed. Members joined: 2 Feb 01 08:53:05 [49238] Node2.contoso.com corosync notice [TOTEM ] A new membership (192.168.10.7:8) was formed. Members joined: 1
(3)查看初始化成员节点通知是否正常发出
[root@Node2 ~]# grep ERROR: /var/log/cluster/corosync.log
(4)检查集群启动状态
[root@Node1 corosync]# corosync-cfgtool -s //检查各节点通信状态(显示为no faults即为OK) Printing ring status. Local node ID 1 RING ID 0 id = 192.168.10.7 status = ring 0 active with no faults [root@Node2 ~]# corosync-cfgtool -s Printing ring status. Local node ID 2 RING ID 0 id = 192.168.10.8 status = ring 0 active with no faults
(5)检查集群成员关系及Quorum API:
[root@Node2 ~]# corosync-cmapctl | grep members runtime.totem.pg.mrp.srp.members.1.config_version (u64) = 0 runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(192.168.10.7) runtime.totem.pg.mrp.srp.members.1.join_count (u32) = 1 runtime.totem.pg.mrp.srp.members.1.status (str) = joined runtime.totem.pg.mrp.srp.members.2.config_version (u64) = 0 runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(192.168.10.8) runtime.totem.pg.mrp.srp.members.2.join_count (u32) = 1 runtime.totem.pg.mrp.srp.members.2.status (str) = joined
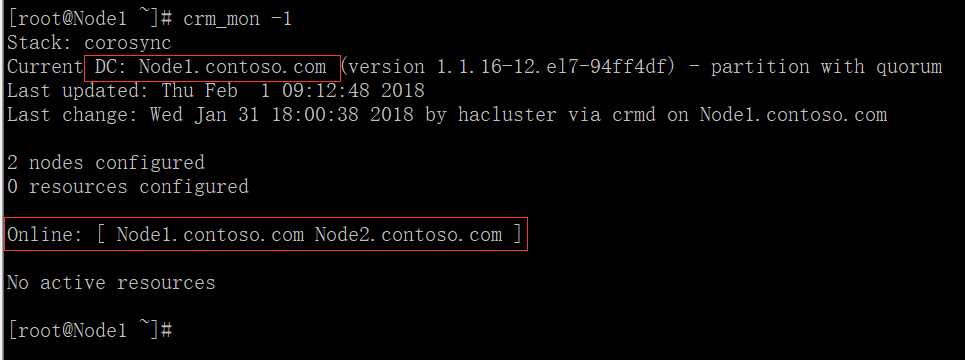
(5)查看集群节点状态及DC:
五、http软件部署及NFS设置
(1)Node1与Node2节点安装httpd软件
[root@Node3 ~]#ansible Webservers -m yum -a ‘name=httpd state=latest‘ [root@Node3 ~]#ansible Webservers -m service -a ‘enabled=on name=httpd state=started‘
(2)Node1与Node2节点的/var/www/html目录下各生成index.html测试页面
[root@Node1 ~]# echo "<h1>Test Page Node1.contoso.com </h1>" > /var/www/html/index.html //生成测试index测试页面 [root@Node1 ~]# curl 192.168.10.7 //本地测试是否访问正常 <h1>Test Page Node1.contoso.com </h1> [root@Node1 ~]# systemctl stop httpd.service //测试正常之后,把httpd服务进行停掉 [root@Node2 ~]# echo "<h1>Test Page Node2.contoso.com </h1>" > /var/www/html/index.html [root@Node2 ~]# [root@Node2 ~]# curl 192.168.10.8 <h1>Test Page Node2.contoso.com </h1> [root@Node2 ~]# systemctl stop httpd.service
(3)Node3节点安装httpd、nfs软件及设置
[root@Node3 ~]# yum install httpd -y //安装httpd软件,主要为了生成apache用户,无需启动 [root@Node3 ~]# mkdir /data/web/htdocs -pv //创建目录 mkdir: created directory ‘/data’ mkdir: created directory ‘/data/web’ mkdir: created directory ‘/data/web/htdocs’ [root@Node3 ~]# echo "<h1>Content to NFS Server</h1>" > /data/web/htdocs/index.html //创建index.html文件 [root@Node3 ~]# setfacl -m u:apache:rwx /data/web/htdocs/ //设置htdocs目录对apache用户具有读写执行权限 [root@Node3 ~]# echo "/data/web/htdocs 192.168.10.0/24 (rw)" > /etc/exports //修改服务端配置文件 [root@Node3 ~]# systemctl start nfs-server.service //启动nfs服务 [root@Node3 ~]# systemctl enable nfs-server.service [root@Node3 ~]# iptables -L //查看防火墙规则 Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination [root@Node3 ~]# getenforce Disabled
六、crmsh命令基本介绍
crmsh提供了一个命令行的交互接口来对Pacemaker集群进行管理,它具有更强大的管理功能,同样也更加易用,在更多的集群上都得到了广泛的应用,注:在crm管理接口所做的配置会同步到各个节点上;
pacemaker的配置接口有两种,一是crmsh,另一个是pcs,主里以crmsh的使用为例。
crmsh依赖pssh这个包,所以两个都需要分别在各个集群节点上进行安装,这两个包可以在这里进行下载http://crmsh.github.io/,下载完成之后进行安装即可

crmsh的crm命令有两种模式:一种是命令模式,当执行一个命令,crmsh会把执行得到的结果输出到shell的标准输出;另一种是交互式模式
(1)查看配置信息: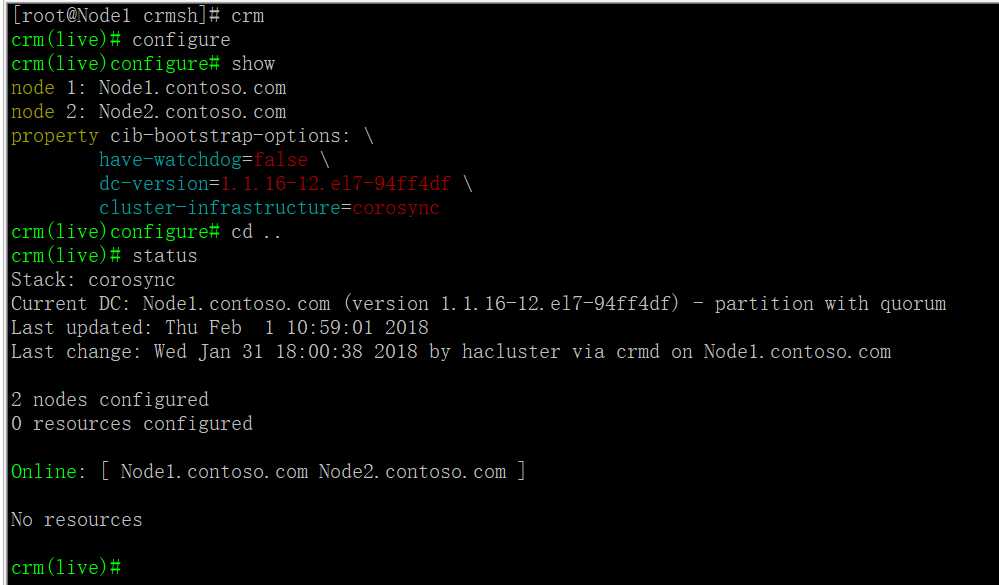
(2)crmsh之node子命令介绍 :
crm(live)# node crm(live)node# help attribute Manage attributes clearstate Clear node state //清理当前node的状态信息 delete Delete node //删除节点 fence Fence node maintenance Put node into maintenance mode online Set node online //将当前节点重新上线,standby转为online ready Put node into ready mode server Show node hostname or server address show Show node //显示当前所有节点 standby Put node into standby //将当前节点转为备用 status Show nodes‘ status as XML status-attr Manage status attributes utilization Manage utilization attributes
(3)crmsh之configure子命令介绍 :
node define a cluster node //定义一个集群节点 primitive define a resource //定义资源 monitor add monitor operation to a primitive //对一个资源添加监控选项(如超时时间,启动失败后的操作) group define a group //定义一个组类型(包含一个或多个资源,这些资源可通过“组”这个资源统一进行调度) clone define a clone //定义一个克隆类型(可以在同一个集群内的多个节点运行多份克隆) ms define a master-slave resource //定义一个主从类型(集群内的节点只能有一个运行主资源,其它从的做备用) rsc_template define a resource template //定义一个资源模板 location a location preference //定义位置约束优先级(默认运行于那一个节点(如果位置约束的值相同,默认倾向性那一个高,就在那一个节点上运行)) colocation colocate resources //排列约束资源(多个资源在一起的可能性) order order resources //顺序约束,定义资源在同一个节点上启动时的先后顺序 rsc_ticket resources ticket dependency property set a cluster property //设置集群属性 rsc_defaults set resource defaults //设置资源默认属性(粘性) fencing_topology node fencing order //隔离节点顺序 role define role access rights //定义角色的访问权限 user define user access rights //定义用用户访问权限 op_defaults set resource operations defaults //设置资源默认选项 schema set or display current CIB RNG schema show display CIB objects //显示集群信息库对 edit edit CIB objects //编辑集群信息库对象(vim模式下编辑) filter filter CIB objects //过滤CIB对象 delete delete CIB objects //删除CIB对象 default-timeouts set timeouts for operations to minimums from the meta-data rename rename a CIB object //重命名CIB对象 modgroup modify group //改变资源组 refresh refresh from CIB //重新读取CIB信息 erase erase the CIB //清除CIB信息 ptest show cluster actions if changes were committed rsctest test resources as currently configured cib CIB shadow management cibstatus CIB status management and editing template edit and import a configuration from a template commit commit the changes to the CIB //将更改后的信息提交写入CIB verify verify the CIB with crm_verify //CIB语法验证 upgrade upgrade the CIB to version 1.0 save save the CIB to a file //将当前CIB导出到一个文件中(导出的文件存于切换crm 之前的目录) load import the CIB from a file //从文件内容载入CIB
(4)crmsh之resource子命令:
crm(live)#resource crm(live)resource# help ban Ban a resource from a node //禁止资源在一个节点 cleanup Cleanup resource status //清理资源状态 constraints Show constraints affecting a resource //显示影响资源的约束 demote Demote a master-slave resource //降级主从资源 failcount Manage failcounts //管理员错误状态统计数据 locate Show the location of resources //显示资源的位置 maintenance Enable/disable per-resource maintenance mode //启用/禁用每个资源维护模式 manage Put a resource into managed mode //资源定义为可被管理状态 meta Manage a meta attribute //管理meta 属性 move Move a resource to another node //将资源移动到另一个节点 operations Show active resource operations //显示活动的资源的操作 param Manage a parameter of a resource //管理资源参数 promote Promote a master-slave resource refresh Refresh CIB from the LRM status reprobe Probe for resources not started by the CRM restart Restart resources //重启一个资源 scores Display resource scores //查看资源 secret Manage sensitive parameters start Start resources //开启一个资源 status Show status of resources //资源当前状态 stop Stop resources //停止一个资源 trace Start RA unmanage Put a resource into unmanaged mode //资源定义为不可被管理状态 untrace Stop RA tracing utilization Manage a utilization attribute
(5)crmsh之资源代理RA子命令:
crm(live)# ra crm(live)ra# help classes List classes and providers //列出资源代理类型 info Show meta data for a RA //显示资源代理的帮助信息 list List RA for a class (and provider) //列出资源代理类型中所拥有的资源代理 providers Show providers for a RA and a class validate Validate parameters for RA
七、使用crmsh配置pacemaker
(1)基本配置
crm //切换至crm命令提示符
crm(live)# config //切换至配置模式
crm(live)configure#property stonith-enabled=false //测试环境没有fence设备,故禁用stonith设备
crm(live)configure#property no-quorum-policy=ignore //忽略集群中当节点数小于等于quorum,节点数将无法运行,默认是stop
crm(live)configure#property default-resource-stickiness=INFINITY //资源粘性配置,主节点故障恢复后不切回资源
(2)配置web高可用集群
crm(live)configure# primitive webip ocf:heartbeat:IPaddr parms ip="192.168.10.100" nic="ens33" cidr_netmask="24" broadcast="192.168.10.255" //定义webip资源 crm(live)configure# primitive webserver systemd:httpd op start timeout=100s op stop timeout=100s //定义webserver资源 crm(live)configure# primitive webstore ocf:heartbeat:Filesystem params device="192.168.10.9:/data/web/htdocs" directory="/var/www/html" fstype="nfs" op start timeout=60s op stop timeout=60s //定义webstore资源
(3)crm status查看资源
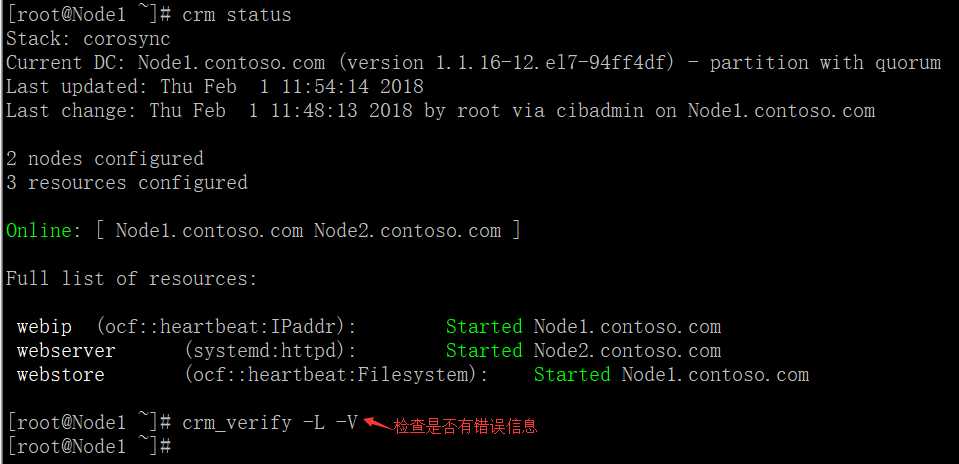
高可用集群默认为资源平均分配,因此我们要通过组或者约束使资源在同一个节点
crm(live)configure# group webservice webstore webserver webip crm(live)configure# verify crm(live)configure# commit crm(live)configure# cd .. crm(live)# status Stack: corosync Current DC: Node1.contoso.com (version 1.1.16-12.el7-94ff4df) - partition with quorum Last updated: Thu Feb 1 14:14:14 2018 Last change: Thu Feb 1 14:11:57 2018 by root via cibadmin on Node1.contoso.com 2 nodes configured 3 resources configured Online: [ Node1.contoso.com Node2.contoso.com ] Full list of resources: Resource Group: webservice webstore (ocf::heartbeat:Filesystem): Started Node1.contoso.com webserver (systemd:httpd): Started Node1.contoso.com webip (ocf::heartbeat:IPaddr): Started Node1.contoso.com crm(live)#
(4)查看网站是正常(先做hosts解析记录)
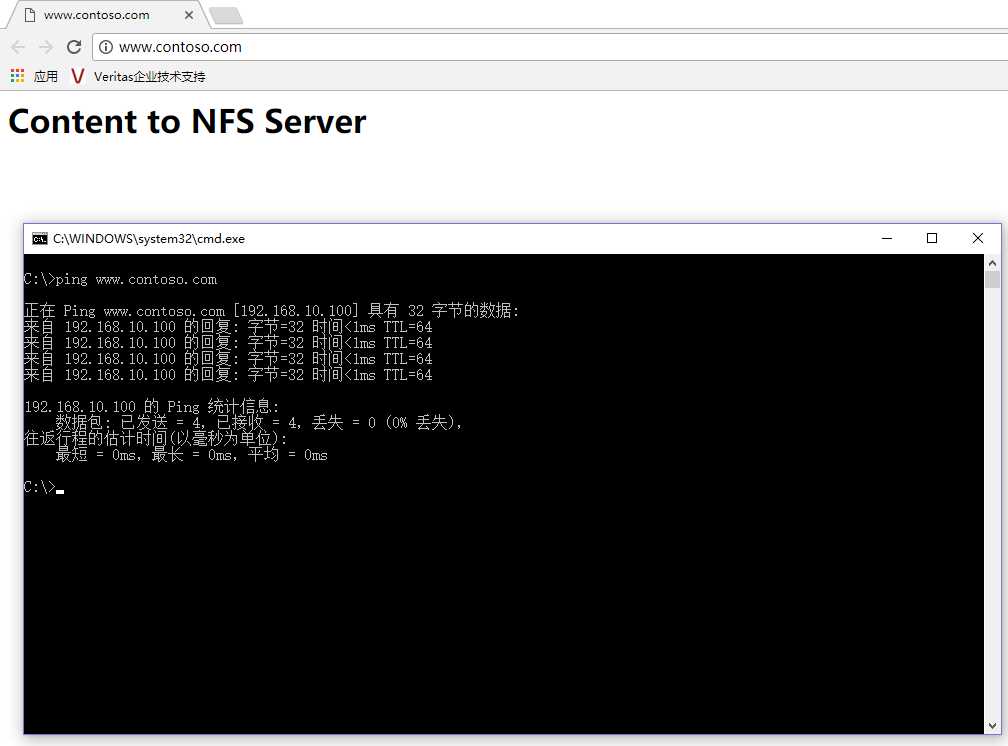
检查NFS是否挂载成功
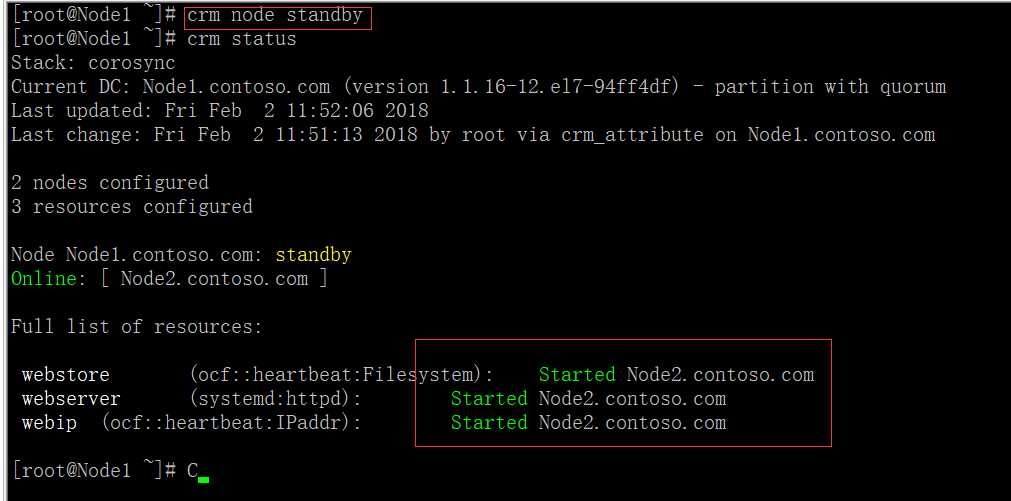
(5)把Node1设为standby模式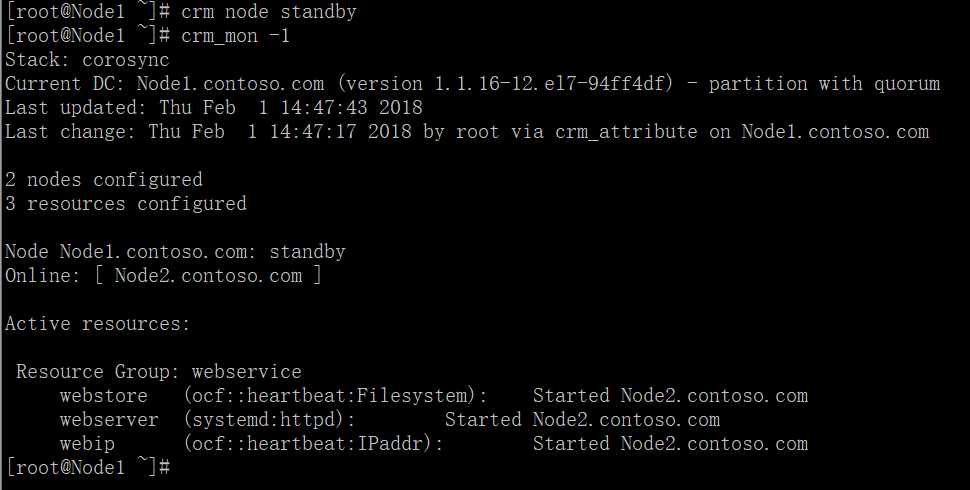
进入Node2节点查看IP地址与NFS是否转移过来
查看网站是正常
(6)定义对资源监控monitor
因为corosync+pacemaker集群默认对节点高可用,但是对于节点上资源的运行状态无法监控,因此,我们要配置集群对于资源的监控,在资源因意外情况下,无法提供服务时,对资源提供高可用。
[root@Node1 ~]# crm configure
crm(live)configure# monitor webip 30s:20s
crm(live)configure# monitor webserver 30s:100s
crm(live)configure# monitor webstore 60s:40s
crm(live)configure# verify
crm(live)configure# commit
此时资源运行于Node1节点,在Node1上手动结束httpd,测试监控,经过一小段时间后,httpd又自动启来了!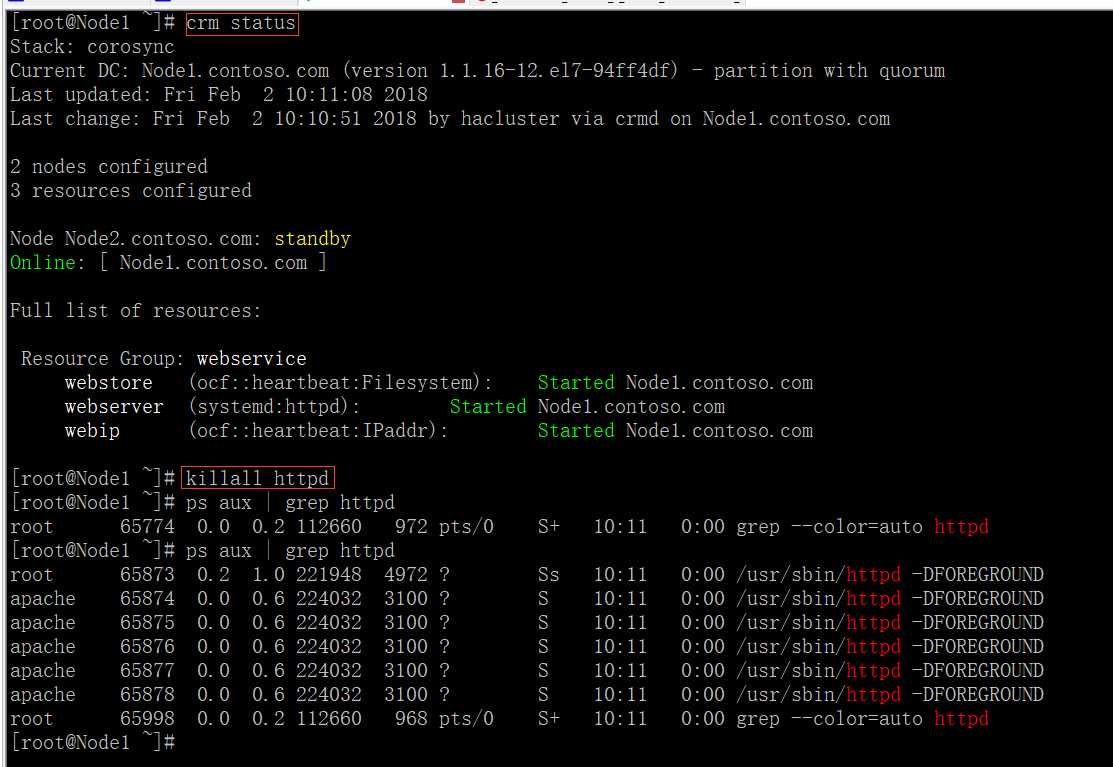
(7)定义约束
资源约束则用以指定在哪些群集节点上运行资源,以何种顺序装载资源,以及特定资源依赖于哪些其它资源。
pacemaker共给我们提供了三种资源约束方法:
1)Resource Location(资源位置):定义资源可以、不可以或尽可能在哪些节点上运行;
2)Resource Collocation(资源排列):排列约束用以定义集群资源可以或不可以在某个节点上同时运行;
3)Resource Order(资源顺序):顺序约束定义集群资源在节点上启动的顺序;
定义约束时,还需要指定分数。各种分数是集群工作方式的重要组成部分。其实,从迁移资源到决定在已降级集群中停止哪些资源的整个过程是通过以某种方式修改分数来实现的。分数按每个资源来计算,资源分数为负的任何节点都无法运行该资源。在计算出资源分数后,集群选择分数最高的节点。INFINITY(无穷大)目前定义为 1,000,000。加减无穷大遵循以下3个基本规则:
1)任何值 + 无穷大 = 无穷大
2)任何值 - 无穷大 = -无穷大
3)无穷大 - 无穷大 = -无穷大
定义资源约束时,也可以指定每个约束的分数。分数表示指派给此资源约束的值。分数较高的约束先应用,分数较低的约束后应用。通过使用不同的分数为既定资源创建更多位置约束,可以指定资源要故障转移至的目标节点的顺序
[root@Node1 ~]# crm configure crm(live)configure# delete webservice crm(live)configure# location webip_on_node1 webip inf: Node1.contoso.com //位置约束 crm(live)configure# colocation webip_with_webserver_with_webstore inf: webip webserver webstore //排列约束 crm(live)configure# order webstore_befroe_webserver_befroe_webip Mandatory: webstore webserver webip //顺序约束 crm(live)configure# verify //检查语法是否有错误 crm(live)configure# commit //提交配置 crm(live)configure# cd .. crm(live)# status Stack: corosync Current DC: Node1.contoso.com (version 1.1.16-12.el7-94ff4df) - partition with quorum Last updated: Fri Feb 2 11:35:58 2018 Last change: Fri Feb 2 11:35:53 2018 by root via cibadmin on Node1.contoso.com 2 nodes configured 3 resources configured Online: [ Node1.contoso.com Node2.contoso.com ] Full list of resources: webstore (ocf::heartbeat:Filesystem): Started Node1.contoso.com webserver (systemd:httpd): Started Node1.contoso.com webip (ocf::heartbeat:IPaddr): Started Node1.contoso.com crm(live)#
(8)查看当前配置信息

(9)将Node1节点设为standby,看资源是否转移成功