一、URL的编码与解码
在python2中包含的urllib和urllib2,都是接受URL请求相关的模块。但是在python3中,却没有urllib2。实际上urllib2的功能在python3中可以用urllib来实现。
通常编码工作,我们使用urllib.parse.urlencode()函数,帮我们将key:value(类似于python的字典)这样的键值对转换成"key=value"这样的字符串,解码工作则可以用unquote()函数来实现。
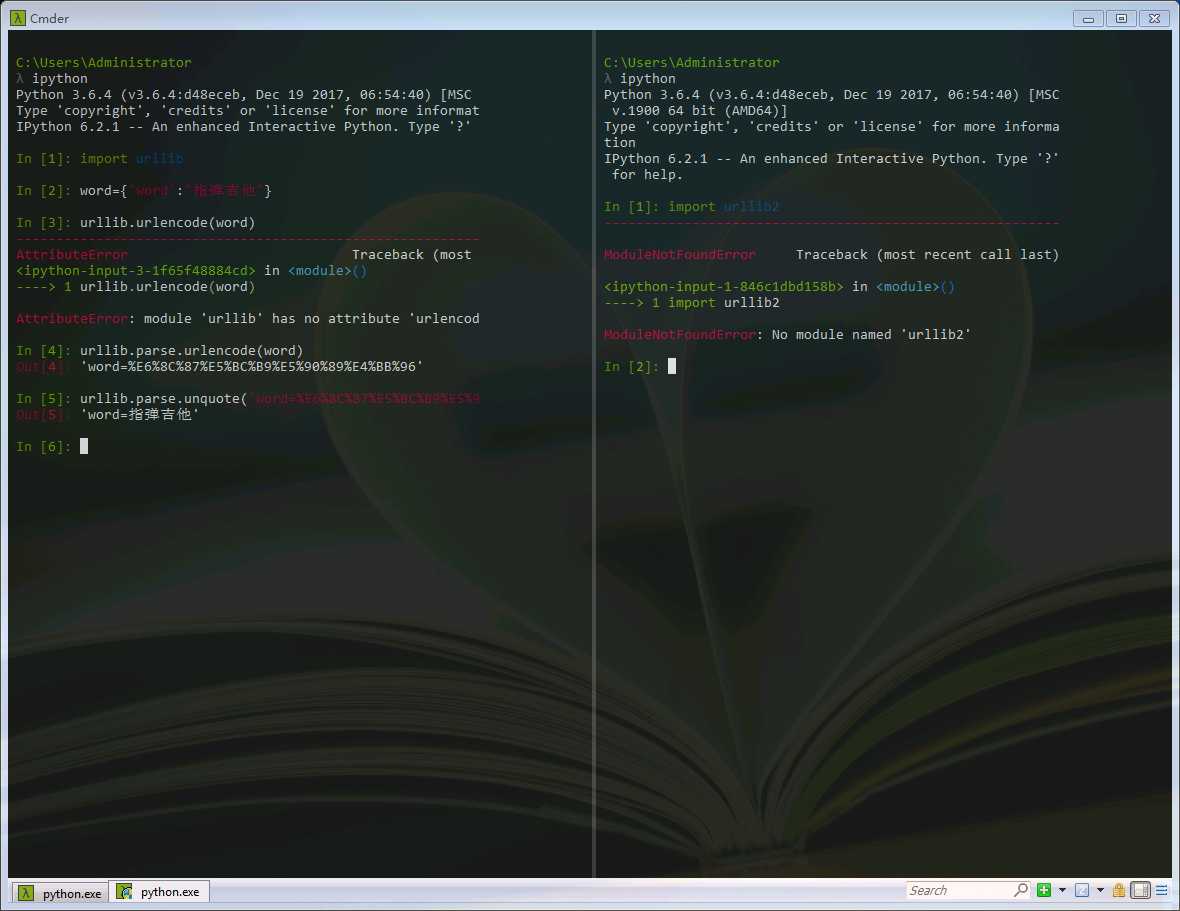
一般的HTTP请求提交数据,需要编码成URL编码格式,然后作为URL的一部分,或者作为参数传到Request对象中。
二、写一个简单的爬虫程序
首先我们在cmder中用vim新建一个python文件,我们得目标是下载上海链家的二手房页面。
可以在浏览器中打开网站分析一下URL
第一页网址是:https://sh.lianjia.com/ershoufang/
第二页网址是:https://sh.lianjia.com/ershoufang/pg2/
第三页网址是:https://sh.lianjia.com/ershoufang/pg3/
............
当我们在https://sh.lianjia.com/ershoufang/后面加上"pg1/"时,发现也能得到第一页。可以根据这个规律来写这个爬虫。
1 from urllib import request 2 3 4 def HTMLspider(url,startPage,endPage): 5 6 #作用:负责处理URL,分配每个URL去发送请求 7 8 for page in range(startPage,endPage+1): 9 filename="第" + str(page) + "页.html" 10 11 12 #组合为完整的url 13 fullurl=url + str(page) 14 15 #调用loadPage()发送请求,获取HTML页面 16 html=loadPage(fullurl,filename) 17 18 #将获取到的HTML页面写入本地磁盘文件 19 writePage(html,filename) 20 21 22 23 def loadPage(fullurl,filename): 24 25 response=request.urlopen(fullurl) 26 return response.read() 27 28 29 30 def writePage(html,filename): 31 """ 32 将服务器的响应文件保存到本地磁盘 33 其中filename为本地磁盘文件名 34 """ 35 print("正在存储"+filename) 36 with open(filename,‘wb‘) as f: 37 f.write(html) 38 39 40 print("--"*30) 41 42 43 if __name__=="__main__": 44 #输入需要下载的起始页和终止页,注意转换成int类型 45 startPage=int(input("请输入起始页:")) 46 endPage=int(input("请输入终止页:")) 47 48 url="https://sh.lianjia.com/ershoufang/" 49 50 HTMLspider(url,startPage,endPage) 51 52 print("下载完成!")
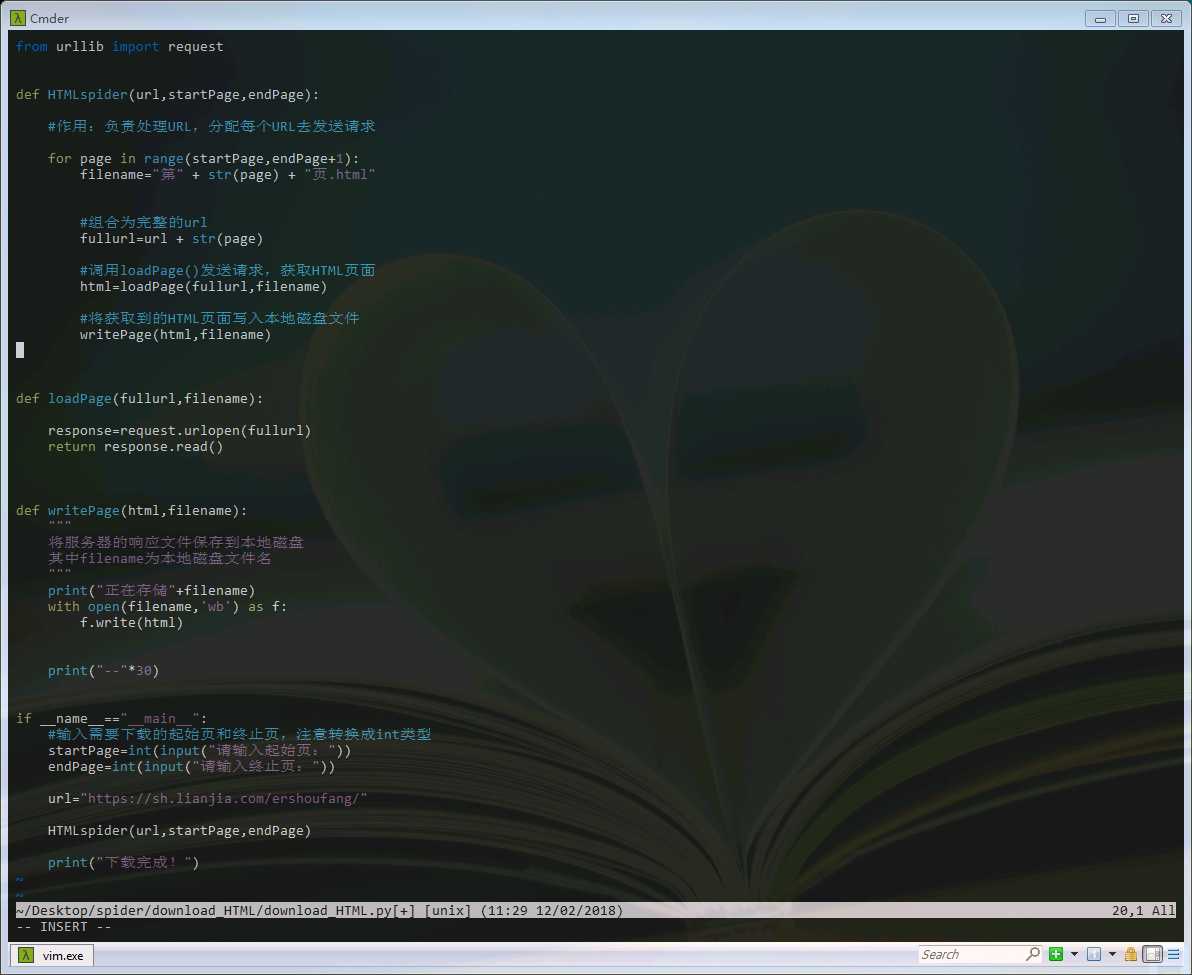
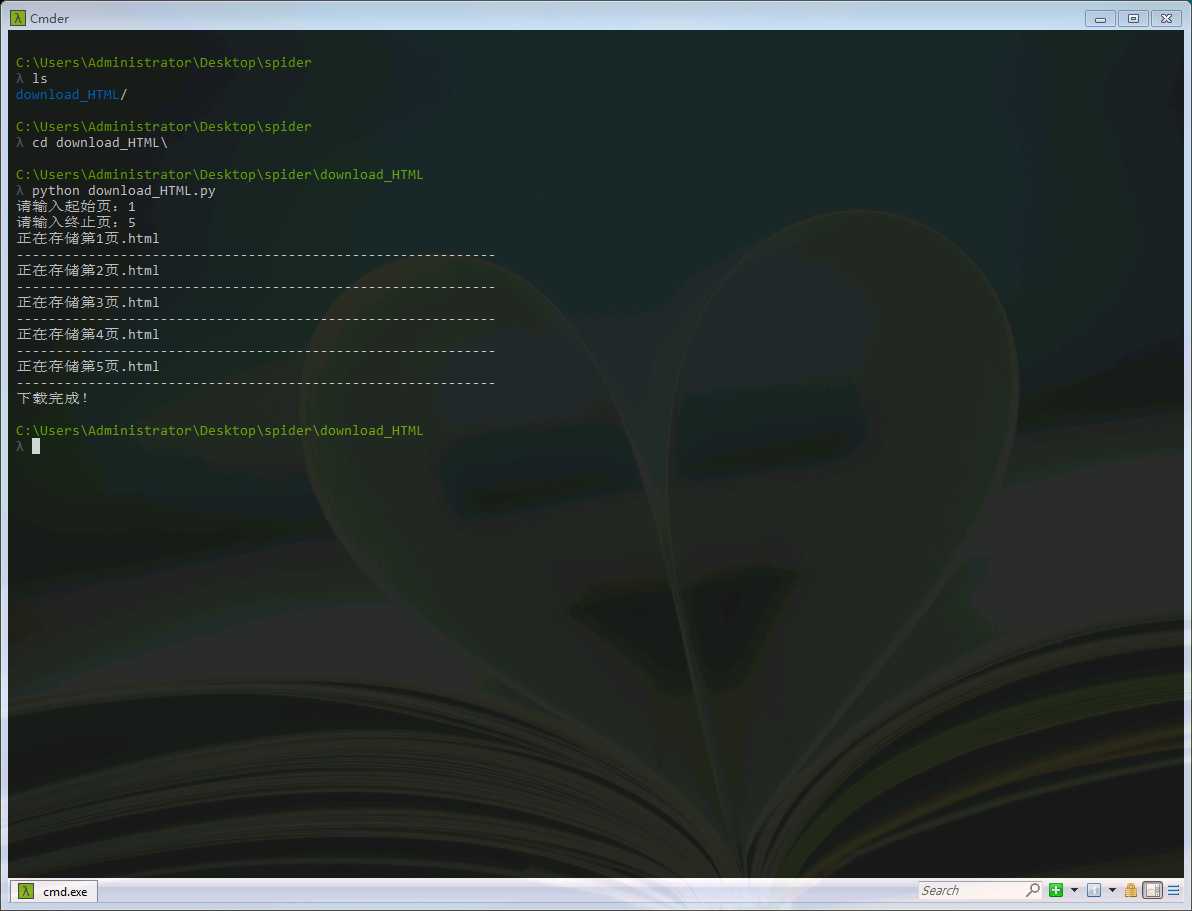
当然,这只是一个非常简单的下载页面的小爬虫。但是我们可以看到爬虫工作的基本过程。
三、关于GET请求和POST方法
GET请求一般用于我们向服务器获取数据,假如我们用百度搜索一个关键词,我们可以看到在请求部分,http://www.baidu.com/?之后出现一个长长的字符串,这就是包含了我们要查询的关键词,于是我们可以用默认的GET方式来发送请求。GET方式是直接以链接的形式访问的,链接中包含了所有参数。
而在发送POST请求时,需要特别注意headers的一些属性:content-length(表单数据长度),X-Requested-With:XMLHttpRequest(Ajax异步请求)等等。POST不会在网址上显示所有参数,服务器端用Requeste.Form获取提交的数据。
“对于一个爬虫工程师,我们必须关注爬虫的来源”