<机械硬盘>
a:磁盘结构
-----传统的机械硬盘一般为3.5英寸硬盘,并由多个圆形蝶片组成,每个蝶片拥有独立的机械臂和磁头,每个堞片的圆形平面被划分了不同的同心圆,每一个同心圆称为一个磁道,位于最外面的道的周长最长称为外道,最里面的道称为内道,通常硬盘厂商会将圆形蝶片最靠里面的一些内道(速度较慢,影响性能)封装起来不用;道又被划分成不同的块单元称为扇区,每个道的周长不同,现代硬盘不同长度的道划分出来的扇区数也是不相同的,而磁头不工作的时候一般位于内道,如果追求响应时间,则数据可存储在硬盘的内道,如果追求大的吞吐量,则数据应存储在硬盘的外道;
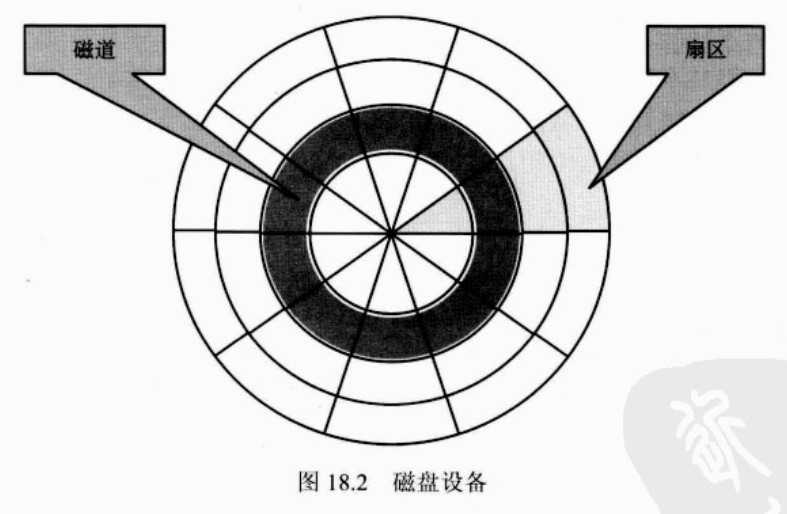
注意:;一个弧道被划分成多个段,每一个段就是一个扇区
b:磁盘访问
------SATA硬盘实现的是串行ATA协议,ATA下盘命令中记录有LBA(Logic Block Address)起始地址和扇区数;LBA地址实际上是一个ATA协议逻辑地址,硬盘的固件会解析收到的ATA命令,并将要访问的LBA地址映射至某个磁道中的某个物理块即扇区。操作系统暂可认为LBA地址就是硬盘的物理地址。
c:扇区
------硬盘的基本访问单位,扇区的大小一般是512B(对于现在的有些磁盘的扇区>512B,比如光盘的一个扇区就是2048B,Linux将其看成4个扇区,无非就是需要完成4次的读写)。
d:块
------扇区是硬件传输数据的基本单位,硬件一次传输一个扇区的数据到内存中。但是和扇区不同的是,块是虚拟文件系统传输数据的基本单位。在Linux中,块的大小必须是2的幂,但是不能超过一个页的大小(4k)。(在X86平台,一个页的大小是4094个字节,所以块大小可以是512,1024,2048,4096)
e:段
------主要为了做scatter/gather DMA操作使用,同一个物理页面中的在硬盘存储介质上连续的多个块组成一个段。段的大小只与块有关,必须是块的整数倍。所以块通常包括多个扇区,段通常包括多个块,物理段通常包括多个段;段在内核中由结构struct bio_vec来描述,多个段的信息存放于struct bio结构中的bio_io_vec指针数组中,段数组在后续的块设备处理流程中会被合并成物理段,段结构定义如下:
struct bio_vec {
struct page *bv_page; // 段所在的物理页面结构,即bh->b_page
unsigned int bv_len; // 段的字节数,即bh->b_size
unsigned int bv_offset; // 段在bv_page页面中的偏移,即bh->b_data
};
f:文件块
------大小定义和文件系统块一样;只是相对于文件的一个偏移逻辑块,需要通过具体文件系统中的此文件对应的inode所记录的间接块信息,换算成对应的文件系统块;此做法是为了将一个文件的内容存于硬盘的不同位置,以提高访问速度;即一个文件的内容在硬盘是一般是不连续的;EXT2中,ext2_get_block()完成文件块到文件系统块的映射。
g:总结
------扇区由磁盘的物理特性决定;块缓冲区由内核代码决定;块由缓冲区决定,是块缓冲区大小的整数倍(但是不能超过一个页)。三者关系如下:
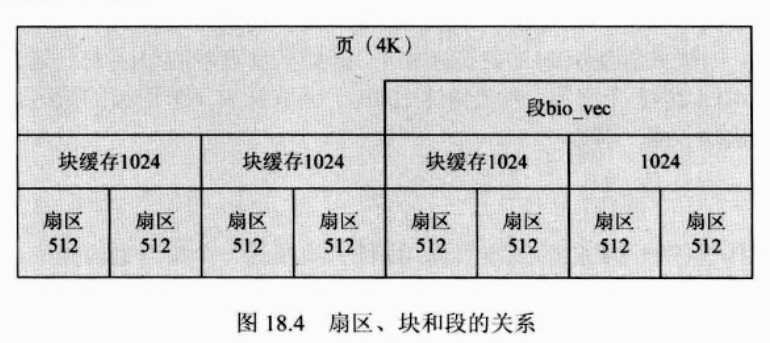
所以:扇区(512)≤块≤页(4096) 块=n*扇区(n为整数)
注意:段(struct bio_vec{})由多个块组成,一个段就是一个内存页(如果一个块是两个扇区大小,也就是1024B,那么一个段的大小可以是1024,2018,3072,4096,也就是说段的大小只与块有关,而且是整数倍)。Linux系统一次读取磁盘的大小是一个块,而不是一个扇区,块设备驱动由此得名。
<块设备处理过程>
a:linux 内核中,块设备将数据存储与固定的大小的块中,每个块都有自己的固定地址。Linux内核中块设备和其他模块的关系如下。
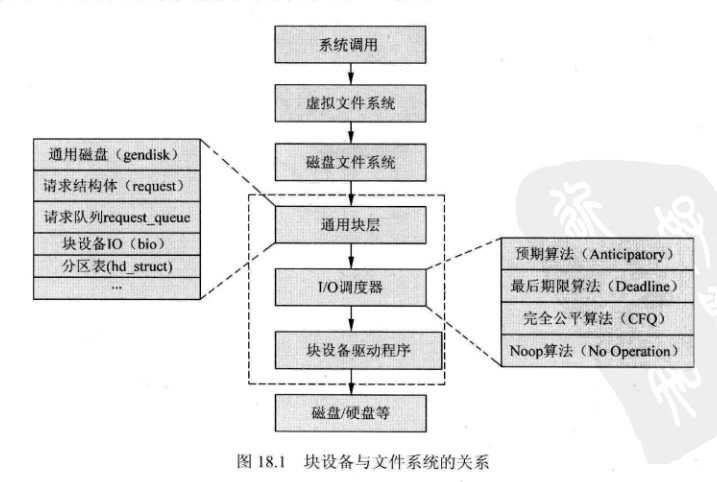
a:块设备的处理过程涉及Linux内核中的很多模块,下面简单描述之间的处理过过程。
(1)当一个用户程序要向磁盘写入数据时,会发发出write()系统调用给内核。
(2)内核会调用虚拟文件系统相应的函数,将需要写入发文件描述符和文件内容指针传递给该函数。
(3)内核需要确定写入磁盘的位置,通过映射层知道需要写入磁盘的哪一块。
(4)根据磁盘的文件系统的类型,调用不同文件格式的写入函数,江苏数据发送给通用块层(比如ext2和ext3文件系统的写入函数是不同的,这些函数由内核开发者实现,驱动开发者不用实现这类函数)
(5)数据到达通用块层后,就对块设备发出写请求。内核利用通用块层的启动I/O调度器,对数据进行排序。
(6)同用块层下面是"I/O调度器"。调度器作用是把物理上相邻的读写合并在一起,这样可以加快访问速度。
(7)最后快设备驱动向磁盘发送指令和数据,将数据写入磁盘。
<基本概念>
a:块设备(block device)
-----是一种具有一定结构的随机存取设备,对这种设备的读写是按块进行的,他使用缓冲区来存放暂时的数据,待条件成熟后,从缓存一次性写入设备或者从设备一次性读到缓冲区。
b:字符设备(Character device)
---是一个顺序的数据流设备,对这种设备的读写是按字符进行的,而且这些字符是连续地形成一个数据流。他不具备缓冲区,所以对这种设备的读写是实时的。
<linux 块设备驱动架构图>
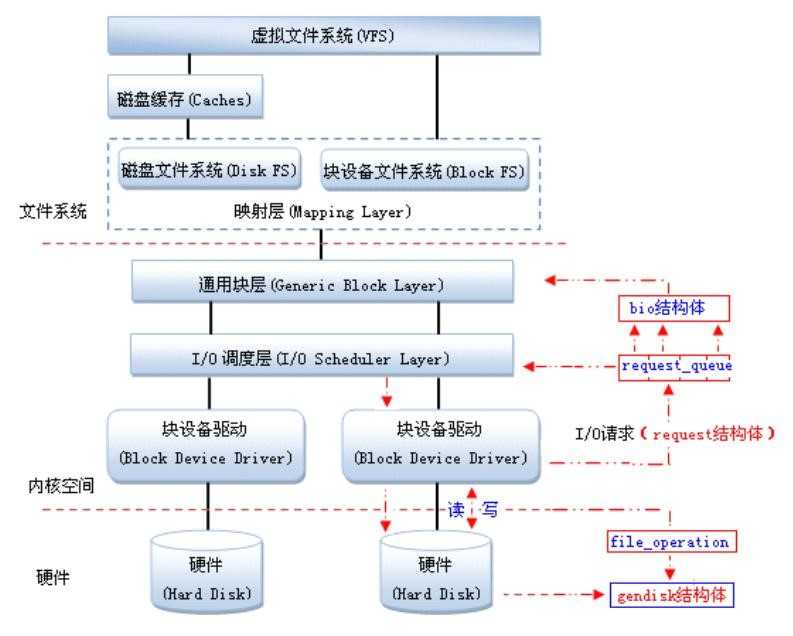
a:架构分析
1)struct bio
------当一个进程被Read时,首先读取cache 中有没有相应的文件,这个cache由一个buffer_head结构读取。如果没有,文件系统就会利用块设备驱动去读取磁盘扇区的数据。于是read()函数就会初始化一个bio结构体,并提交给通用块层。通常用一个bio结构体来对应一个I/O请求。
(1)内核结构如下:
| 1 struct bio { 2 sector_t bi_sector; /* 要传输的第一个扇区 */ 3 struct bio *bi_next; /* 下一个 bio */ 4 struct block_device*bi_bdev; 5 unsigned long bi_flags; /* 状态、命令等 */ 6 unsigned long bi_rw; /* 低位表示 READ/WRITE,高位表示优先级*/ 7 8 unsigned short bi_vcnt; /* bio_vec 数量 */ 9 unsigned short bi_idx; /* 当前 bvl_vec 索引 */ 10 11 /* 执行物理地址合并后 sgement 的数目 */ 12 unsigned short bi_phys_segments; 13 14 unsigned int bi_size; 15 16 /* 为了明了最大的 segment 尺寸,我们考虑这个 bio 中第一个和最后一个 17 可合并的 segment 的尺寸 */ 18 unsigned int bi_hw_front_size; 19 unsigned int bi_hw_back_size; 20 21 unsigned int bi_max_vecs; /* 我们能持有的最大 bvl_vecs 数 */ 22 unsigned int bi_comp_cpu; /* completion CPU */ 23 24 struct bio_vec *bi_io_vec; /* 实际的 vec 列表 */ 25 26 bio_end_io_t *bi_end_io; 27 atomic_t bi_cnt; 28 29 void *bi_private; 30 #if defined(CONFIG_BLK_DEV_INTEGRITY) 31 struct bio_integrity_payload *bi_integrity; /* 数据完整性 */ 32 #endif 33 34 bio_destructor_t *bi_destructor; /* 析构 */ 35 }; |
(2)bio的核心是一个被称为bi_io_vec的数组,它由bio_vec组成(也就是说bio由许多bio_vec组成)。内核定义如下:
bio_vec描述一个特定的片段,片段所在的物理页,块在物理页中的偏移页,整个bio_io_vec结构表示一个完整的缓冲区。当一个块被调用内存时,要储存在一个缓冲区,每个缓冲区与一个块对应,所以每一个缓冲区独有一个对应的描述符,该描述符用buffer_head结构表示:
| 1 struct bio_vec { 2 struct page *bv_page; /* 页指针 */ 3 unsigned int bv_len; /* 传输的字节数 */ 4 unsigned int bv_offset; /* 偏移位置 */ 5 }; |
- struct buffer_head {
- unsigned long b_state; /* buffer state bitmap (see above) */
- struct buffer_head *b_this_page; /* circular list of page‘s buffers */
- struct page *b_page; /* the page this bh is mapped to */
- sector_t b_blocknr; /* start block number */
- size_t b_size; /* size of mapping */
- char *b_data; /* pointer to data within the page */
- struct block_device *b_bdev;
- bh_end_io_t *b_end_io; /* I/O completion */
- void *b_private; /* reserved for b_end_io */
- struct list_head b_assoc_buffers; /* associated with another mapping */
- struct address_space *b_assoc_map; /* mapping this buffer is
- associated with */
- atomic_t b_count; /* users using this buffer_head */
- };
(3)bio和buffer_head之间的使用关系
核心ll_rw_block函数:
- void ll_rw_block(int rw, int nr, struct buffer_head *bhs[])
- {
- int i;
- for (i = 0; i < nr; i ) {
- struct buffer_head *bh = bhs[i];
- if (!trylock_buffer(bh))
- continue;
- if (rw == WRITE) {
- if (test_clear_buffer_dirty(bh)) {
- bh->b_end_io = end_buffer_write_sync;
- get_bh(bh);
- submit_bh(WRITE, bh);
- continue;
- }
- } else {
- if (!buffer_uptodate(bh)) {
- bh->b_end_io = end_buffer_read_sync;
- get_bh(bh);
- submit_bh(rw, bh);
- continue;
- }
- }
- unlock_buffer(bh);
- }
- }
核心submit_bh()函数:
- int submit_bh(int rw, struct buffer_head * bh)
- {
- struct bio *bio;
- int ret = 0;
- BUG_ON(!buffer_locked(bh));
- BUG_ON(!buffer_mapped(bh));
- BUG_ON(!bh->b_end_io);
- BUG_ON(buffer_delay(bh));
- BUG_ON(buffer_unwritten(bh));
- /*
- * Only clear out a write error when rewriting
- */
- if (test_set_buffer_req(bh) && (rw & WRITE))
- clear_buffer_write_io_error(bh);
- /*
- * from here on down, it‘s all bio -- do the initial mapping,
- * submit_bio -> generic_make_request may further map this bio around
- */
- bio = bio_alloc(GFP_NOIO, 1);
- bio->bi_sector = bh->b_blocknr * (bh->b_size >> 9);
- bio->bi_bdev = bh->b_bdev;
- bio->bi_io_vec[0].bv_page = bh->b_page;
- bio->bi_io_vec[0].bv_len = bh->b_size;
- bio->bi_io_vec[0].bv_offset = bh_offset(bh);
- bio->bi_vcnt = 1;
- bio->bi_idx = 0;
- bio->bi_size = bh->b_size;
- bio->bi_end_io = end_bio_bh_io_sync;
- bio->bi_private = bh;
- bio_get(bio);
- submit_bio(rw, bio);
- if (bio_flagged(bio, BIO_EOPNOTSUPP))
- ret = -EOPNOTSUPP;
- bio_put(bio);
- return ret;
- }
这个函数主要是调用submit_bio,最终调用generic_make_request去完成将bio传递给驱动去处理。如下所示:
- void generic_make_request(struct bio *bio)
- {
- struct bio_list bio_list_on_stack;
- if (!generic_make_request_checks(bio))
- return;
- if (current->bio_list) {
- bio_list_add(current->bio_list, bio);
- return;
- }
- BUG_ON(bio->bi_next);
- bio_list_init(&bio_list_on_stack);
- current->bio_list = &bio_list_on_stack;
- do {
- struct request_queue *q = bdev_get_queue(bio->bi_bdev);
- q->make_request_fn(q, bio);
- bio = bio_list_pop(current->bio_list);
- } while (bio);
- current->bio_list = NULL; /* deactivate */
- }
这个函数主要是取出块设备相应的队列中的每个设备,在调用块设备驱动的make_request,如果没有指定make_request就调用内核默认的__make_request,这个函数主要作用就是调用I/O调度算法将bio合并,或插入到队列中合适的位置中去。
2)struct request
------提交工作由submit_bio()去完成,通用层在调用相应的设备IO调度器,这个调度器的调度算法,将这个bio合并到已经存在的request中,或者创建一个新的request,并将创建的插入到请求队列中。最后就剩下块设备驱动层来完成后面的所有工作。(Linux系统中,对块设备的IO请求,都会向块设备驱动发出一个请求,在驱动中用request结构体描述)
内核结构如下:
| 1 struct request { 2 struct list_head queuelist; 3 struct call_single_data csd; 4 int cpu; 5 6 struct request_queue *q; 7 8 unsigned int cmd_flags; 9 enum rq_cmd_type_bits cmd_type; 10 unsigned long atomic_flags; 11 12 /* 维护 I/O submission 的 BIO 遍历状态 13 * hard_开头的成员仅用于块层内部,驱动不应该改变它们 14 */ 15 16 sector_t sector; /* 要提交的下一个 sector */ 17 sector_t hard_sector; /* 要完成的下一个 sector */ 18 unsigned long nr_sectors; /* 剩余需要提交的 sector 数 */ 19 unsigned long hard_nr_sectors; /*剩余需要完成的 sector 数*/ 20 /* 在当前 segment 中剩余的需提交的 sector 数 */ 21 unsigned int current_nr_sectors; 22 23 /*在当前 segment 中剩余的需完成的 sector 数 */ 24 unsigned int hard_cur_sectors; 25 26 struct bio *bio; 27 struct bio *biotail; 28 29 struct hlist_node hash; 30 union { 31 struct rb_node rb_node; /* sort/lookup */ 32 void *completion_data; 33 }; 34 35 /* 36 * I/O 调度器可获得的两个指针,如果需要更多,请动态分配 |
| 37 */ 38 void *elevator_private; 39 void *elevator_private2; 40 41 struct gendisk *rq_disk; 42 unsigned long start_time; 43 44 /* scatter-gather DMA 方式下 addr+len 对的数量(执行物理地址合并后) 45 */ 46 unsigned short nr_phys_segments; 47 48 unsigned short ioprio; 49 50 void *special; 51 char *buffer; 52 53 int tag; 54 int errors; 55 56 int ref_count; 57 58 unsigned short cmd_len; 59 unsigned char __cmd[BLK_MAX_CDB]; 60 unsigned char *cmd; 61 62 unsigned int data_len; 63 unsigned int extra_len; 64 unsigned int sense_len; 65 void *data; 66 void *sense; 67 68 unsigned long deadline; 69 struct list_head timeout_list; 70 unsigned int timeout; 71 int retries; 72 73 /* 74 * 完成回调函数 75 */ 76 rq_end_io_fn *end_io; 77 void *end_io_data; 78 79 struct request *next_rq; 80 }; |
| 30 return 0; 31 out_queue: unregister_blkdev(XXX_MAJOR, "xxx"); 32 out: put_disk(xxx_disks); 33 blk_cleanup_queue(xxx_queue); 34 35 return -ENOMEM; 36 } |
(3)请求队列初始化:
(3)-1:请求队列数据结构

(3)-2:request_queue_t *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock)
第一个参数是指向"请求处理函数"的指针,该函数直接和硬盘打交道,用来处理数据在内存和硬盘之间的传输。该函数整体的作用就是为了分配请求队列,并初始化。
(3)-3:typedef void (request_fn_proc)(struct reqest_queue *q)
该函数作为上述函数(request_queue_t *blk_init_queue(request_fn_proc *rfn,spinlock_t *lock))的参数,主要作用就是处理请求队列中的bio,完成数据在内存和硬盘之间的传递。(注意:该函数参数中的bio都是经过i/o调度器的)
(3)-4:typedef int (make_request_fn)(struct request_queue *q,struct bio *bio)
该函数是的第一个参数是请求队列,第二个参数是bio,该函数的作用是根据bio生成一个request(所以叫制造请求函数)。
注意:在想不使用I/O调度器的时候,就应该在该函数中实现,对每一传入该函数的bio之间进行处理,完成数据在内存和硬盘的之间的传输,这样就可以不使用"request_fn_proc"函数了。(所以可以看出来,如果使用i/o调度器,make_request_fn函数是在request_fn_proc函数之前执行)
<I/O调度器的使用与否>
a:背景
------I/O调度器看起来可以提高访问速度,但是这是并不是最快的,因为I/O调度过程会花费很多时间。最快的方式就是不使用I/O调度器
b:请求队列和I/O调度器
------要脱离I/O调度器,就必须了解请求队列request_queue,因为I/O调度器和请求队列是绑定在一起的。其关系如下:
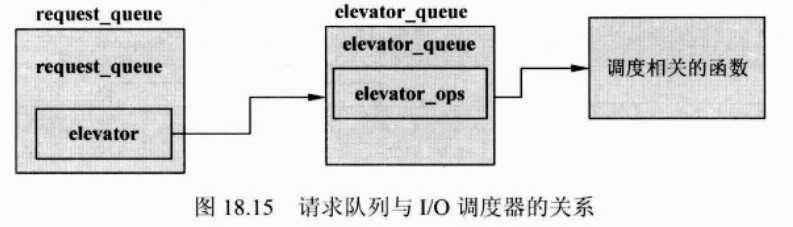
如山图所示,请求队列request_queue 中的elevator指针式指向I/O调度函数的。
b:通用块层函数调用关系(对bio的处理过程)
b-1:调用框图
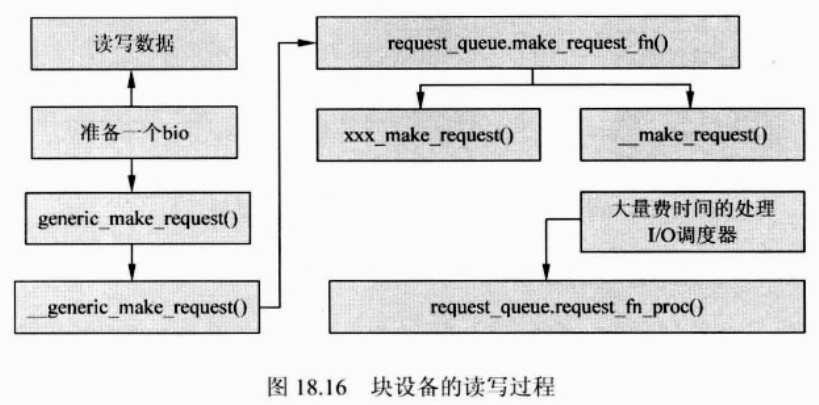
b-2:具体分析
(1)当需要读写一个数据的时候,通用块层,会根据用户空间的请求,生成一个bio结构体。
(2)准备好bio后,会调用函数generic_make_request()函数,函数原形如下:
void generic_make_request(struct bio *bio)
(3)该函数会调用底层函数:
static inline void _generic_make_request(struct bio *bio);
(4)到这里会分层两种情况:
第一种,调用请求队列中自己定义的make_request_fn()函数,那问题来了,系统怎么知道这个自己定义函数在哪里呢?由内核函数blk_queue_make_request()函数指定,函数原形:
void blk_queue_make_request(struct request_queue *q,make_request_fn *mfn);
第一种,调用请求队列中自己定义的make_request_fn()函数,那问题来了,系统怎么知道这个自己定义函数在哪里呢?由内核函数blk_queue_make_request()函数指定,函数原形:
void blk_queue_make_request(struct request_queue *q,make_request_fn *mfn);
第二种,使用请求队列中系统默认__make_request()函数,函数原形“
static int __make_request(struct request_queue *q,struct bio *bio);
static int __make_request(struct request_queue *q,struct bio *bio);
该函数会启动I/O调度器,对bio进行调度处理,bio结构或被合并到请求队列的一个请求结构的request中。最后调用request_fn_proc()将数据写入或读出块块设备。
c:使用I/O调度器和不使用I/O调度器
c-1:不使用i/o调度器(blk_alloc_queue())
bio的流程完全由驱动开发人员控制,要达到这个目的,必须使用函数blk_alloc_queue()来申请请求队列,然后使用函数blk_queue_make_requset()给bio指定具有request_fn_proc()功能的函数Virtual_blkdev_make_request来完成数据在内存和硬盘之间的传输(该函数本来是用来将bio加入request中的)。
| static int Virtual_blkdev_make_request(struct requset_queue *q,structb bio *bio) { //因为不使用I/O调度算法,直接在该函数中完成数据在内存和硬盘之间的数据传输,该函数 //代替了request_fn_proc()函数的功能 ............ } Virtual_blkdev_queue = blk_alloc_queue(GFP_KERNEL) if(!Virtual_blkdev_queue) { ret=-ENOMEN; goto err_alloc_queue; } blk_queue_make_request(Virtual_blkdev_queue,Virtual_blkdev_make_request); |
c-2:使用i/o调度器(blk_init_queue())
bio先经过__make_request()函数,I/O调度器,和request_fn_proc()完成内存和硬盘之间的数据传输。该过程使用函数blk_init_queue()函数完成队列的初始化,并指定request_fn_proc():
| struct request_queue* blk_inti_queue(request_fn_proc *rfn,spinlock_t *lock) |
<总结驱动框架>
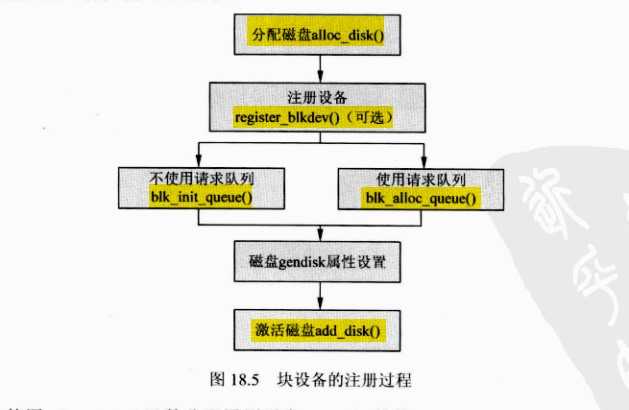
a:块设备驱动加载过程
(1)使用alloc_disk()函数分配通用磁盘gendisk的结构体。
(2)通过内核函数register_blkdev()函数注册设备,该过程是一个可选过程。
(也可以不用注册设备,驱动一样可以工作,该函数和字符设备的register_chrdev()函数相对应,对于大多数的块设备,第一个工作就是相内核注册自己,但是在Linux2.6以后,register_blkdev()函数的调用变得可选,内核中register_blkdev()函数的功能正在逐渐减少。基本上就只有如下作用:
1)分局major分配一个块设备号
2)在/proc/devices中新增加一行数据,表示块设备的信息)
(3)根据是否需要I/O调度,将情况分为两种情况,一种是使用请求队列进行数据传输,一种是不使用请求队列进行数据传输。
(4)初始化gendisk结构体的数据成员,包括major,fops,queue等赋初值。
(5)使用add_disk()函数激活磁盘设备(当调用该函数后就可以对磁盘进行操作(访问),所以调用该函数之前必须所有的准备工作就绪)
b:块设备驱动卸载过程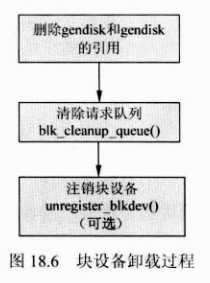
(1)使用del_gendisk()函数删除gendisk设备,并使用put_disk()删除对gendisk设备的引用;
(2)使用blk_clean_queue()函数清楚请求队列,并释放请求队列所占用的资源。
(3)如果在模块加载函数中使用register_blkdev()注册设备,那么就需要调用unregister_blkdev()函数注销设备并释放对设备的引用。
<块设备驱动代码示例(不使用I/O调度器)>




制造请求函数(在这里完成数据的读写)



卸载函数

<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">